Announcing Llama 3.1 Support in vLLM
Today, the vLLM team is excited to partner with Meta to announce the support for the Llama 3.1 model series. Llama 3.1 comes with exciting new features with longer context length (up to 128K tokens), larger model size (up to 405B parameters), and more advanced model capabilities. The vLLM community has added many enhancements to make sure the longer, larger Llamas run smoothly on vLLM, which includes chunked prefill, FP8 quantization, and pipeline parallelism. We will introduce these new enhancements in this blogpost.
Introduction
vLLM is a fast, easy-to-use, open-source serving engine for large language models. vLLM has support for more than 40 types of open-source LLMs, a diverse set of hardware platforms (Nvidia GPU, AMD GPU, AWS Inferentia, Google TPU, Intel CPU, GPU, Gaudi, …) and all kinds of inference optimizations. Learn more about vLLM here.
For the new Llama 3.1 series, vLLM can run the models with a full 128K context window. In order to support a large context window, vLLM automatically enables chunked prefill. Chunked prefill not only keeps memory usage under control, but also reduces the interruption from long prompt processing for ongoing requests. You can install vLLM by running the following command or using our official docker image (vllm/vllm-openai):
pip install -U vllm
For the large Llama 405B model, vLLM supports it in several methods:
- FP8: vLLM runs the official FP8 quantized model natively on 8xA100 or 8xH100.
- Pipeline Parallelism: vLLM runs the official BF16 version on multiple nodes by placing different layers of the model on different nodes.
- Tensor Parallelism: vLLM can also run by sharding the model across multiple nodes, and multiple GPUs within the nodes.
- AMD MI300x or NVIDIA H200: vLLM can run the model on a single 8xMI300x or 8xH200 machine, where each GPU has 192GB and 141 GB memory, respectively.
- CPU Offloading: as the last resort, vLLM can offload some of the weights to CPU while performing the forward pass, allowing you to run the large model at full precision on limited GPU memory.
Please note that while vLLM supports all these methods, the performance is still preliminary. The vLLM community is actively working on optimizations and we welcome everyone’s contribution. For example, we are actively exploring more approaches to quantize the model, and to increase the throughput of pipeline parallelism. The performance numbers posted later in the blog are meant as early reference points; we expect the performance to improve significantly over the next few weeks.
Out of all the methods, we recommend FP8 for a single node, and pipeline parallelism for multiple nodes. Let’s discuss them in more detail.
FP8
FP8 represents float point numbers in 8 bits. The current generation of GPUs (H100, MI300x) provide native support for FP8 via specialized tensor cores. Currently, vLLM can run FP8 quantized models for KV cache, attention, and MLP layers. This reduces memory footprint, increases throughput, lowers latency, and comes with minimal accuracy drops.
Currently, vLLM supports the official Meta Llama 3.1 405B FP8 model quantized via FBGEMM by leveraging per-channel quantization in the MLP layer. In particular, each channel of the up/gate/down projections are quantized and multiplied by a static scaling factor. Combined with skipping quantization for the first and the last layer, and a static upper bound, this approach has minimal impact on the model’s accuracy. You can run the model with latest vLLM on a single 8xH100 or 8xA100 with the following command:
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 --tensor-parallel-size 8
Using the FP8 quantized model serving requests with the average input length of 1024 tokens and the average output length of 128 output tokens, the server can sustain 2.82 requests per second. The corresponding serving throughput is 2884.86 input tokens per second and 291.53 output tokens per seconds, respectively.
We also independently confirmed the accuracy drop of the FP8 checkpoints is minimal. For example, running the GSM8K benchmark using lm-eval-harness with 8 shots and chain-of-thought, we observed the exact match score of 95.38% (+- 0.56% stddev), which is a minimal drop compared to the BF16 official score of 96.8%.
Pipeline Parallelism
What if you want to run the Llama 3.1 405B model without quantization? You can do it with 16xH100 or 16xA100 GPUs using vLLM’s pipeline parallelism!
Pipeline parallelism splits a model into smaller sets of layers, executing them in parallel on two or more nodes in a pipelined fashion. Unlike tensor parallelism, which requires expensive all-reduce operations, pipeline parallelism partitions the model across layer boundaries, needing only inexpensive point-to-point communication. This is particularly useful when you have multiple nodes that are not necessarily connected via fast interconnects like Infiniband.
vLLM supports combining pipeline and tensor parallelism. For example, with 16 GPUs across 2 nodes, you can use 2-way pipeline parallelism and 8-way tensor parallelism to optimize hardware usage. This configuration maps half the model to each node, partitioning each layer across 8 GPUs using NVLink for all-reduce operations. You can run the Llama 3.1 405B model with the following command:
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct --tensor-parallel-size 8 --pipeline-parallel-size 2
If you have fast interconnects like Infiniband, you can use 16-way tensor parallelism:
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct --tensor-parallel-size 16
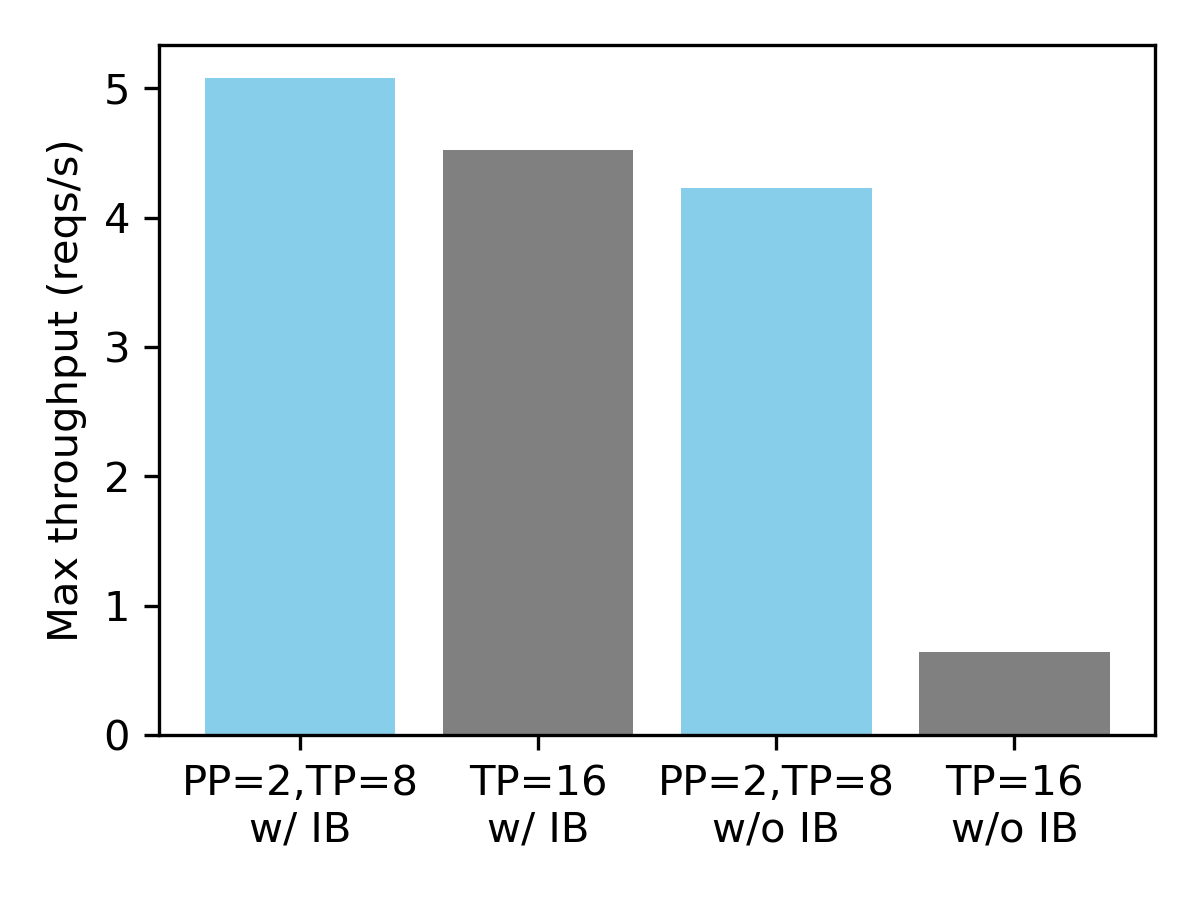
Serving throughput on 16xH100 GPUs with a synthetic dataset (avg. input len 1024, avg. output len 128).
We have observed that pipeline parallelism is essential when the nodes are not connected via Infiniband. Compared to 16-way tensor parallelism, combining 2-way pipeline parallelism with 8-way tensor parallelism leads to 6.6x performance improvements. On the other hand, with Infiniband, the performance of both configurations is similar.
To learn more about distributed inference using vLLM please refer to this doc. For CPU offloading, please refer to this example.
Acknowledgements
We would like to thank Meta for the pre-release partnership and letting us test the model. Independently from the release, we thank the following vLLM contributors for the features mentioned in this blogpost: Neural Magic for FP8 quantization; CentML and Snowflake AI Research for pipeline parallelism; Anyscale for the chunked prefill feature. The evaluation runs on Lambda’s 1-Click Clusters with InfiniBand, and we thank Lambda for the resource and the smooth cluster setup experience.