vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction
TL;DR: vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on Llama 8B model, and 1.8x higher throughput and 2x less TPOT on Llama 70B model.
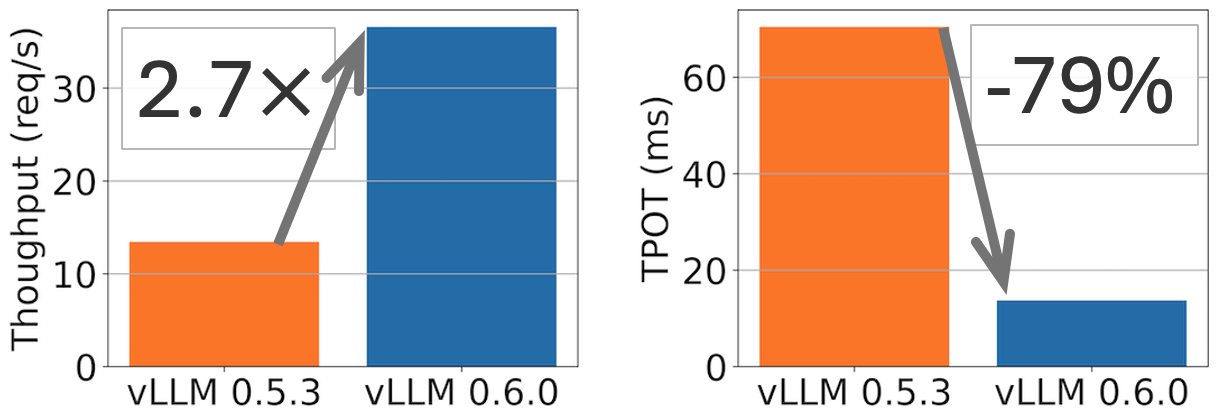
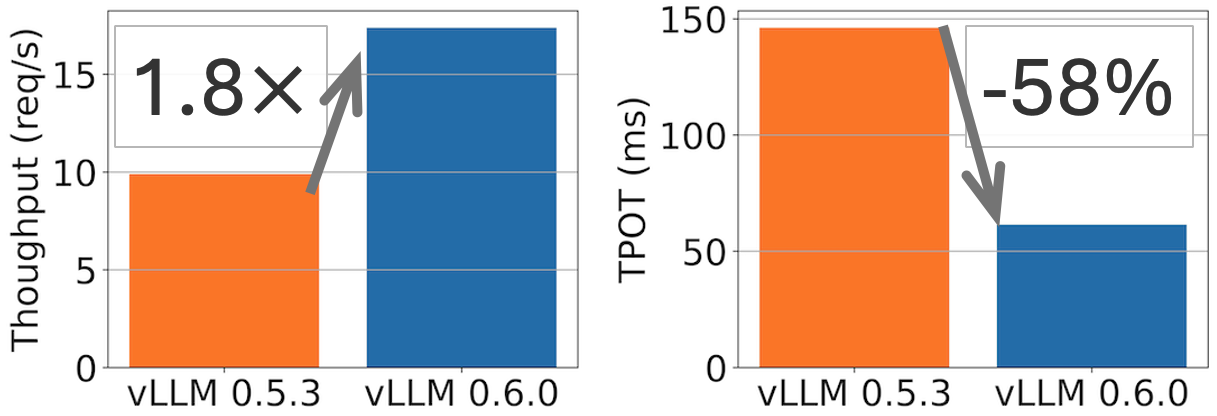
Performance comparison between vLLM v0.5.3 and v0.6.0 for Llama 8B on 1xH100 and 70B on 4xH100 on ShareGPT dataset (500 prompts). TPOT measured at 32 QPS.
A month ago, we released our performance roadmap committing to performance as our top priority. Today, we released vLLM v0.6.0, with 1.8-2.7x throughput improvements compared to v0.5.3, reaching state-of-the-art performance while keeping rich features and great usability.
We will start by diagnosing the performance bottleneck in vLLM previously. Then we will describe the solution we implemented and landed in the past month. Finally, we will showcase the benchmarks of the latest vLLM release v0.6.0 other inference engines.
Performance Diagnosis
LLM inference requires tight collaboration between CPUs and GPUs. Although the major computation happens in GPUs, CPUs also play an important role in serving and scheduling requests. If CPUs cannot schedule fast enough, GPUs will sit idle to wait for CPUs, which eventually leads to inefficient GPU utilization and hinders inference performance.
One year ago, when vLLM was first released, we mainly optimized for relatively large models on GPUs with limited memory (e.g. Llama 13B on NVIDIA A100-40G). As faster GPUs with larger memory (like NVIDIA H100) become more available and models become more optimized for inference (e.g. with techniques like GQA and quantization), the time spent on other CPU parts of the inference engine becomes a significant bottleneck. Specifically, our profiling results show that for Llama 3 8B running on 1 H100 GPU:
- The HTTP API server takes 33% of the total execution time.
- 29% of the total execution time is spent on scheduling, including gathering the LLM results from the last step, scheduling the requests to run for the next step, and preparing these requests as inputs for the LLMs.
- Finally, only 38% of the time was spent on the actual GPU execution for LLMs.
We found two main issues in vLLM through the benchmark above:
- High CPU overhead. The CPU components of vLLM take a surprisingly long time. To make vLLM’s code easy to understand and contribute, we keep most of vLLM in Python and use many Python native data structures (e.g., Python Lists and Dicts). This becomes a significant overhead that causes the scheduling and data preparation time to be high.
- Lack of asynchronicity among different components. In vLLM, many components (e.g., scheduler and output processor) execute in a synchronous manner that blocks GPU execution. This is mainly due to 1) our original assumption that model execution would be much slower than the CPU parts and 2) ease of implementation for many complicated scheduling situations (e.g., scheduling for beam search). However, this issue causes the GPU to wait for the CPU and reduces its utilization.
To summarize, the performance bottleneck of vLLM is mainly caused by the CPU overhead that blocks the GPU execution. In vLLM v0.6.0, we introduce a series of optimizations to minimize these overheads.
Performance Enhancements
To make sure we can keep GPUs busy, we made several enhancements:
Separating API server and inference engine into different processes (PR #6883)
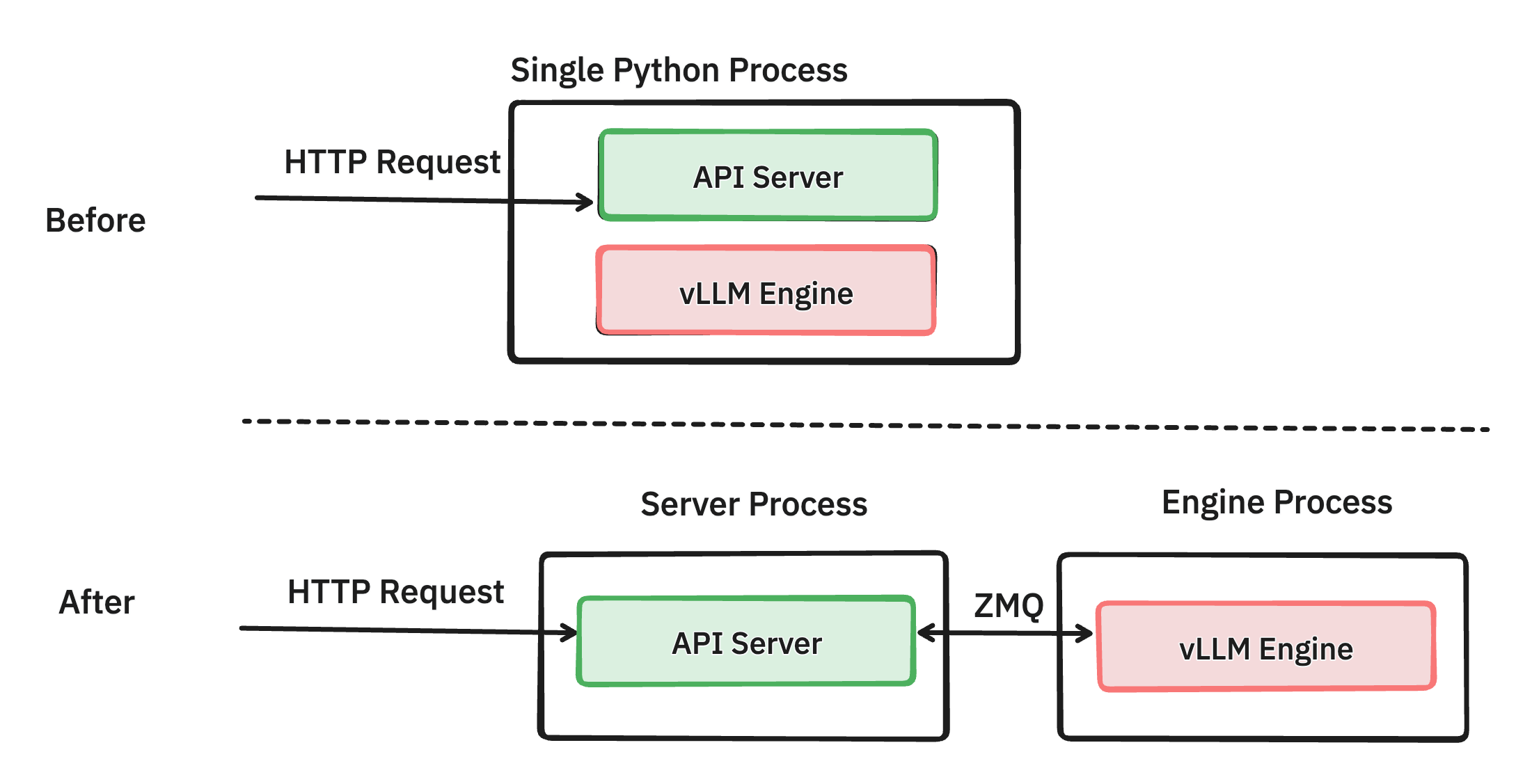
Through careful profiling, we found that managing network requests and formatting the response for OpenAI protocol can consume quite a bit of CPU cycles, especially under high load with token streaming enabled. For example, Llama3 8B can generate 1 token every 13 ms under light load. This translates to the frontend needing to stream back 76 objects per second, and this demand further increases with hundreds of concurrent requests. This posed a challenge for the previous version of vLLM, where the API server and the inference engine were running in the same process. As a result, the inference engine and API server coroutines had to compete for Python GIL, leading to CPU contention.
Our solution is to separate out the API server, which handles request validation, tokenization, and JSON formatting, from the engine, which manages request scheduling and model inference. We connect these two Python processes using ZMQ, which has low overhead. By eliminating GIL constraints, both components can operate more efficiently without CPU contention, leading to improved performance.
Even after splitting these two processes, we find there’s still much room for improvement in terms of how we process requests in the engine and how we interact with http requests. We are actively working on further improving the performance of API server (PR #8157), towards making it as efficient as offline batching inference in the near future.
Batch scheduling multiple steps ahead (PR #7000)
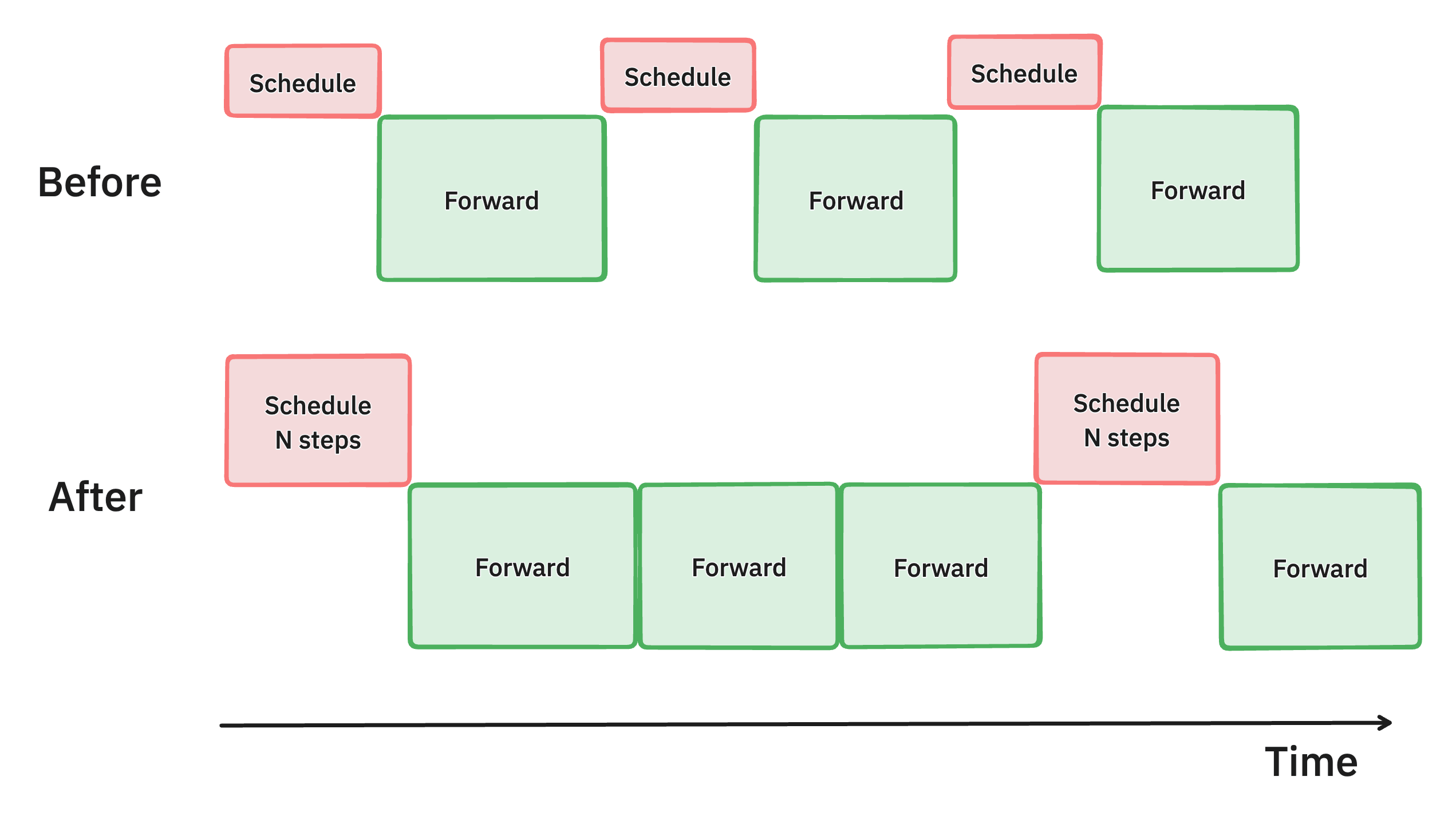
Illustration of the multistep scheduling method in vLLM. By batching multiple scheduling steps at once, we keep the GPU busier than before, therefore reducing latency and improve throughput.
We identified that the CPU overhead from vLLM’s scheduler and input preparation was leading to GPU underutilization, resulting in suboptimal throughput. To tackle this, we introduced multi-step scheduling, which performs scheduling and input preparation once and runs the model for n consecutive steps. By ensuring that the GPU can continue processing between the n steps without waiting for the CPU, this approach spreads the CPU overhead across multiple steps, significantly reducing GPU idle time and boosting overall performance.
This improves the throughput of running Llama 70B models on 4xH100 by 28%.
Asynchronous output processing (PR #7049, #7921, #8050)
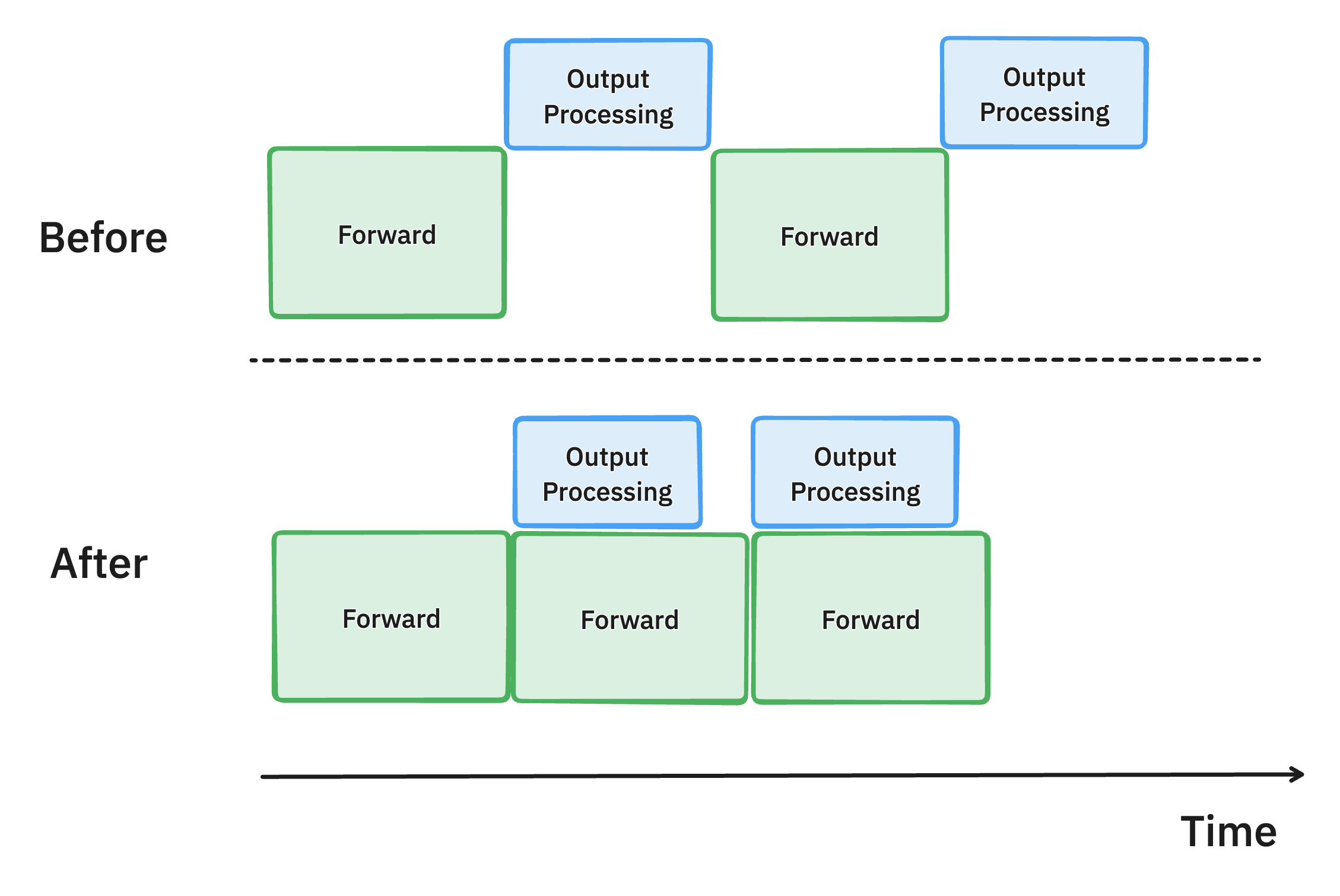
Illustration of the asynchronous output processing in vLLM. By overlapping the CPU work for output data structure processing with the GPU computation, we reduced GPU idle time and improved throughput.
Continuing our efforts to maximize GPU utilization, we also revamped how the model output is processed in vLLM.
Previously, after generating each token, vLLM moved the model output from GPU to CPU, checked the stopping criteria to determine if the request had finished, and then executed the next step. This output processing was often slow, involving de-tokenizing the generated token IDs and performing string matching, with the overhead increasing as batch sizes grew.
To address this inefficiency, we introduced asynchronous output processing, which overlaps the output processing with model execution. Instead of processing the output immediately, vLLM now delays it, performing the processing of the n-th step output while executing the n+1-th step. This approach assumes that no request from the n-th step has met the stopping criteria, incurring a slight overhead of executing one additional step per request. However, the significant boost in GPU utilization more than offsets this cost, leading to improved overall performance.
This improves the time-per-output-token of running Llama 70B models on 4xH100 by 8.7%.
Miscellaneous optimization
To further reduce the CPU overhead, we carefully examined the whole codebase and performed the following optimizations:
- As requests come and finish, Python will allocate new objects and deallocate them again and again. To alleviate this overhead, we create an object cache (#7162) to hold these objects, which significantly improves the end-to-end throughput by 24%.
- When sending data from CPU to GPU, we use non-blocking operations (#7172) as much as possible. The CPU can launch many copy operations while the GPU is copying the data.
- vLLM supports diverse attention backends and sampling algorithms. For commonly used workloads with simple sampling requests (#7117), we introduce a fast code path that skips the complex steps.
Over the last month, the vLLM community has devoted many efforts for such optimizations. And we will continue to optimize the code base to improve the efficiency.
Performance Benchmarks
With the above efforts, we are happy to share that vLLM’s performance has improved a lot compared with last month’s vLLM. And it reaches state-of-the-art performance according to our performance benchmarks.
Serving engines. We benchmark the vLLM v0.6.0 against TensorRT-LLM r24.07, SGLang v0.3.0, and lmdeploy v0.6.0a0. For other benchmarks, we use their default setting. For vLLM, we have turned on multistep scheduling via setting --num-scheduler-steps 10. We are actively working on making it on by default.
Dataset. We benchmark different serving engines using the following three datasets:
- ShareGPT: 500 prompts randomly sampled from ShareGPT dataset with fixed random seed.
- Average input tokens: 202, average output tokens: 179
- Prefill-heavy dataset: 500 prompts synthetically generated from sonnet dataset with roughly 462 input tokens and 16 output tokens on average.
- Decode-heavy dataset: 500 prompts synthetically generated from sonnet dataset with roughly the same amount of 462 input tokens and 256 output tokens on average.
Models. We benchmark on two models: Llama 3 8B and 70B. We did not use the latest Llama 3.1 models as TensorRT-LLM r24.07 with TensorRT LLM backend v0.11 does not support it (issue link).
Hardware. We use A100 and H100 for benchmarking. They are the major two high-end GPUs used for inference.
Mertics. We evaluate the following metrics:
- Time-to-first-token (TTFT, measured in ms). We show the mean and standard error of the mean in the plots.
- Time-per-output-token (TPOT, measured in ms). We show the mean and standard error of the mean in the plots.
- Throughput (measured in request per second).
- Throughput is measured under QPS inf (meaning that all requests come at once).
Benchmarking results
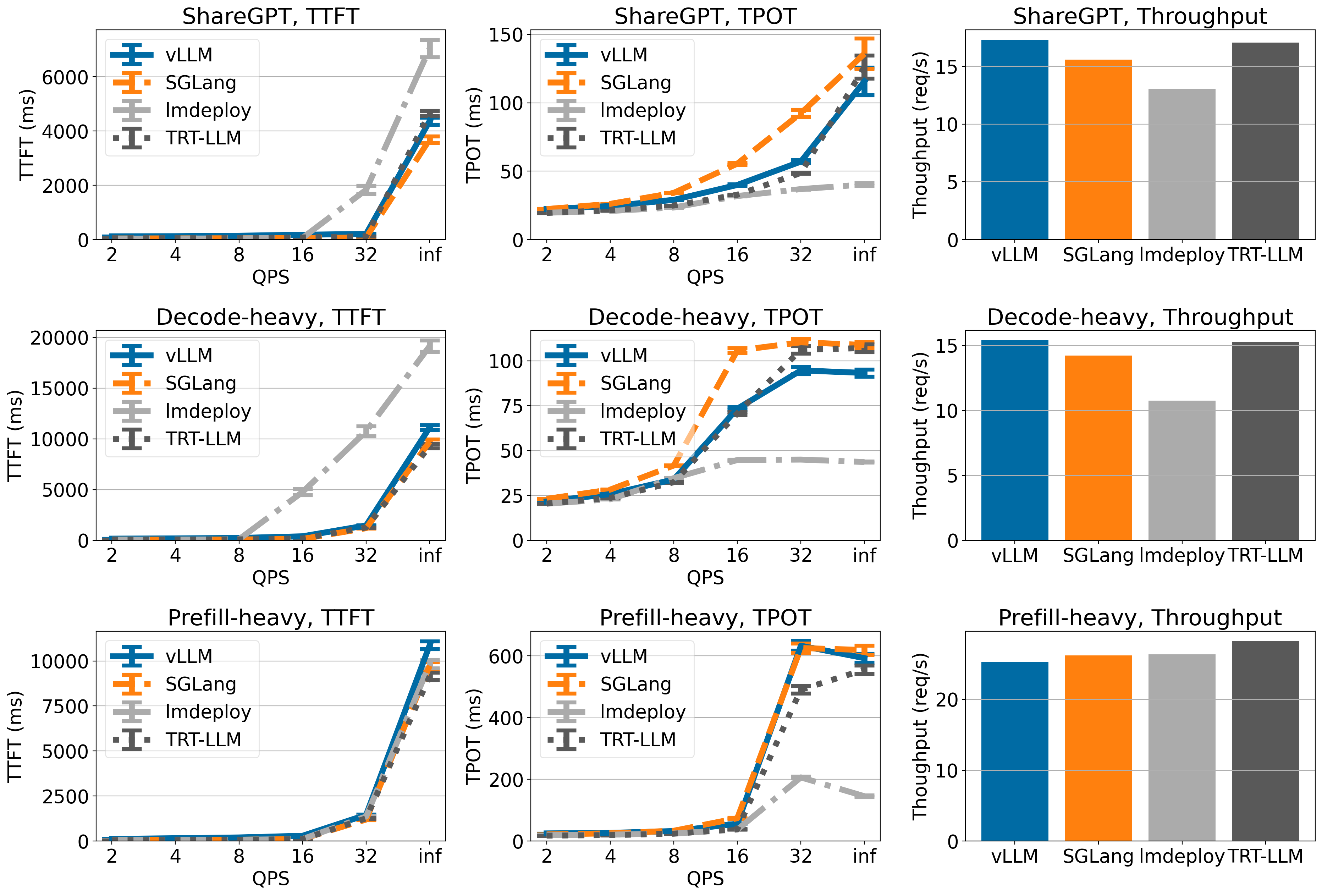
In ShareGPT and Decode-heavy dataset, vLLM achieves highest throughput on H100 when serving Llama-3 models.
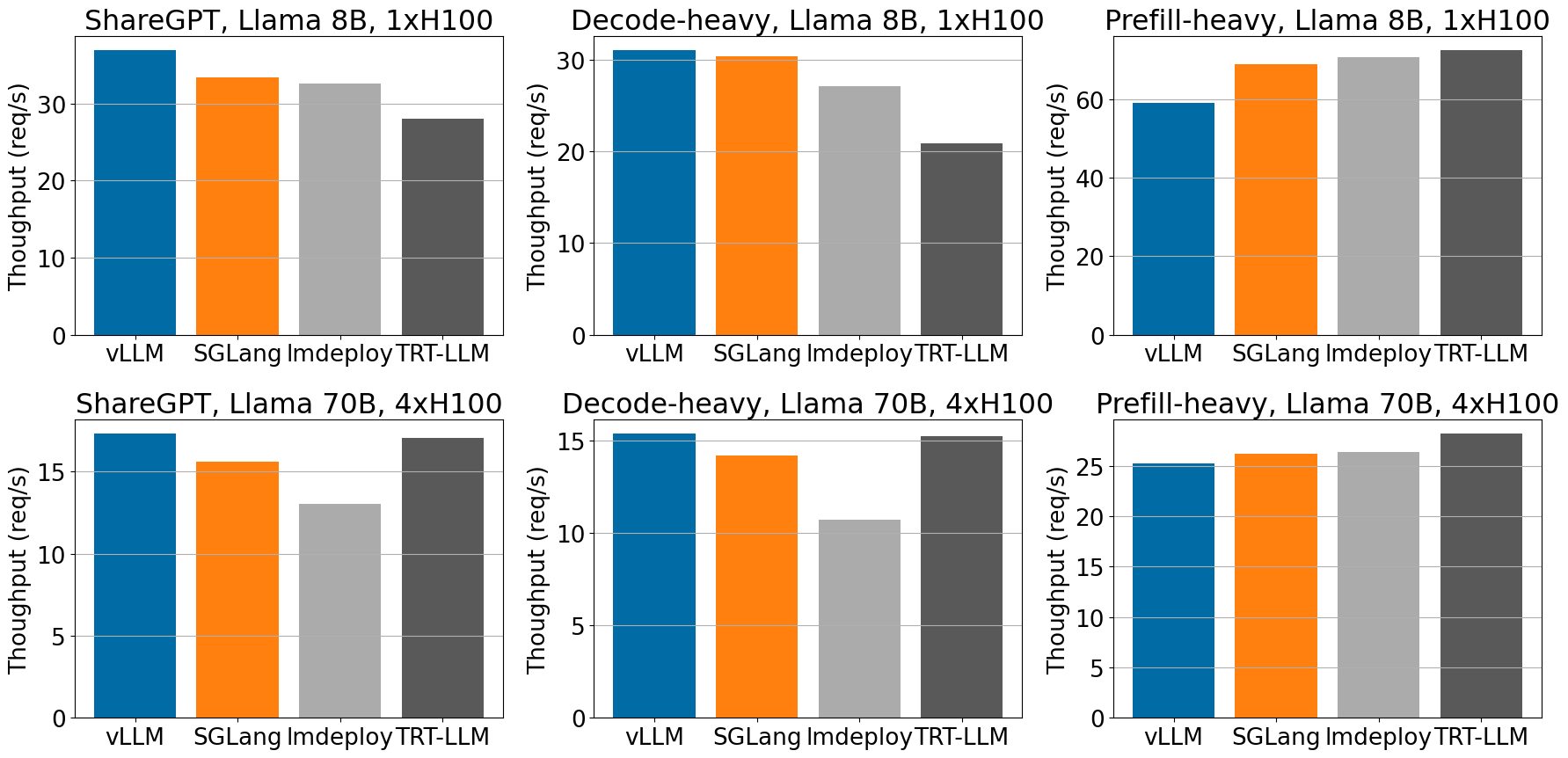
Across different workloads, vLLM achieves high throughput compared to other frameworks, for Llama 8B and 70B on H100.
For the rest of performance benchmarks, as well as captured detailed metrics for time-to-first-token (TTFT) and time-per-output-token (TPOT), please refer to the appendix for more data and analysis. You can follow this github issue to reproduce our benchmark.
Limitation of current optimizations. Although our current optimizations give a significant throughput gain, there are performance trade-offs from our current optimizations, especially from multi-step scheduling:
- Bumpy inter-token latency: In our current implementation of multi-step scheduling, we also return the output tokens for multiple steps in a batch. From an end-user’s perspective, they will receive batches of tokens being replied. We are fixing this by streaming the intermediate tokens back to the engine.
- Higher TTFT at low request rate: A new request can only start execution after the current multi-step execution finishes. Therefore, higher
--num-scheduler-stepswill lead to higher TTFT at low request rates. Our experiments focus on the queueing delay at high QPS so this effect is not significant in the results in the appendix.
Conclusion & Future Work
In this post, we discussed the performance enhancements in vLLM that lead to 1.8-2.7x throughput increase and matching other inference engines. We remain committed to steadily improving the performance, while continuously broadening our model coverages, hardware support, and diverse features. For the features discussed in this post, we will continue to harden them for production readiness.
Importantly, we will also focus on improving the core of vLLM to reduce the complexity so it lowers the barriers for contribution and unlocking even more performance enhancements.
Get Involved
If you haven’t, we highly recommend you to update the vLLM version (see instructions here) and try it out for yourself! We always love to learn more about your use cases and how we can make vLLM better for you. The vLLM team can be reached out via vllm-questions@lists.berkeley.edu. vLLM is also a community project, if you are interested in participating and contributing, we welcome you to check out our roadmap and see good first issues to tackle. Stay tuned for more updates by following us on X.
If you are in the Bay Area, you can meet the vLLM team at the following events: vLLM’s sixth meetup with NVIDIA(09/09), PyTorch Conference (09/19), CUDA MODE IRL meetup (09/21), and the first ever vLLM track at Ray Summit (10/01-02).
Regardless where you are, don’t forget to sign up for the online biweekly vLLM office hours! There are always new topics discussed every two weeks. The next one will be a deep dive into the performance enhancements.
Acknowledgment
The blogpost is drafted by the vLLM team at Berkeley. The performance boost comes from collective efforts in the vLLM community: Robert Shaw from Neural Magic and Nick Hill, Joe Runde from IBM lead the API server refactoring, Will Lin from UCSD and Antoni Baum, Cody Yu from Anyscale lead the multi-step scheduling effort, Megha Agarwal from Databricks and Alexander Matveev from Neural Magic lead the async output processing, and many contributors from the vLLM community contribute various optimizations. All these efforts bring us together to get a huge performance boost.
Appendix
We include the detailed experiment results in this section.
Llama 3 8B on 1xA100
On Llama 3 8B, vLLM achieves comparable TTFT and TPOT on ShareGPT and decode-heavy dataset as TensorRT-LLM and SGLang. LMDeploy has lower TPOT compared to other engines but has higher TTFT in general. Throughput-wise, TensorRT-LLM has the highest throughput among all engines, and vLLM has the second highest throughput on ShareGPT and decode-heavy dataset.
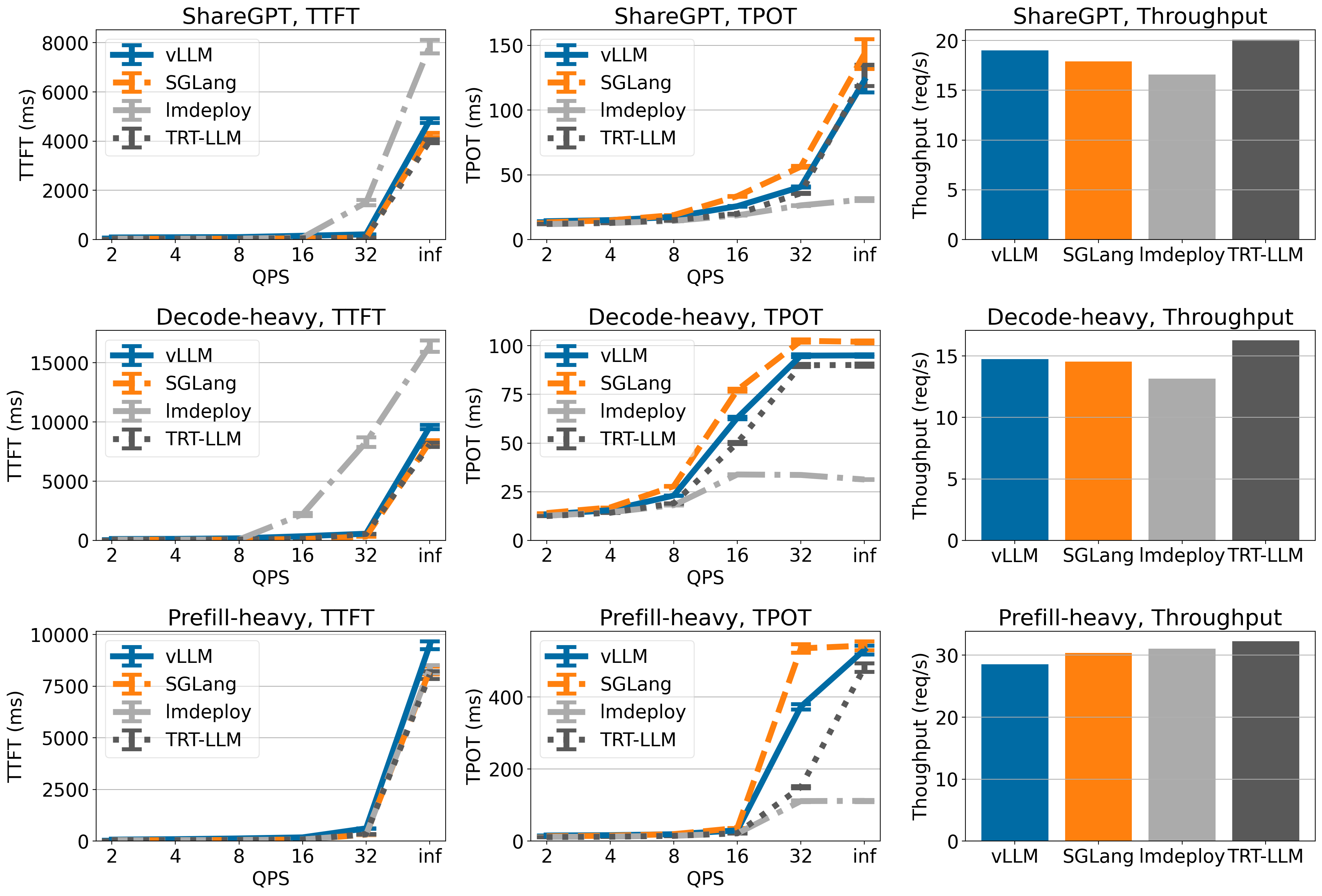
Llama 3 70B on 4xA100
On Llama 3 70B, vLLM, SGLang and TensorRT-LLM have similar TTFT and TPOT (LMDeploy has lower TPOT but higher TTFT). Throughput-wise, vLLM achieves highest throughput on ShareGPT dataset and comparable throughput compared to other engines on other datasets.
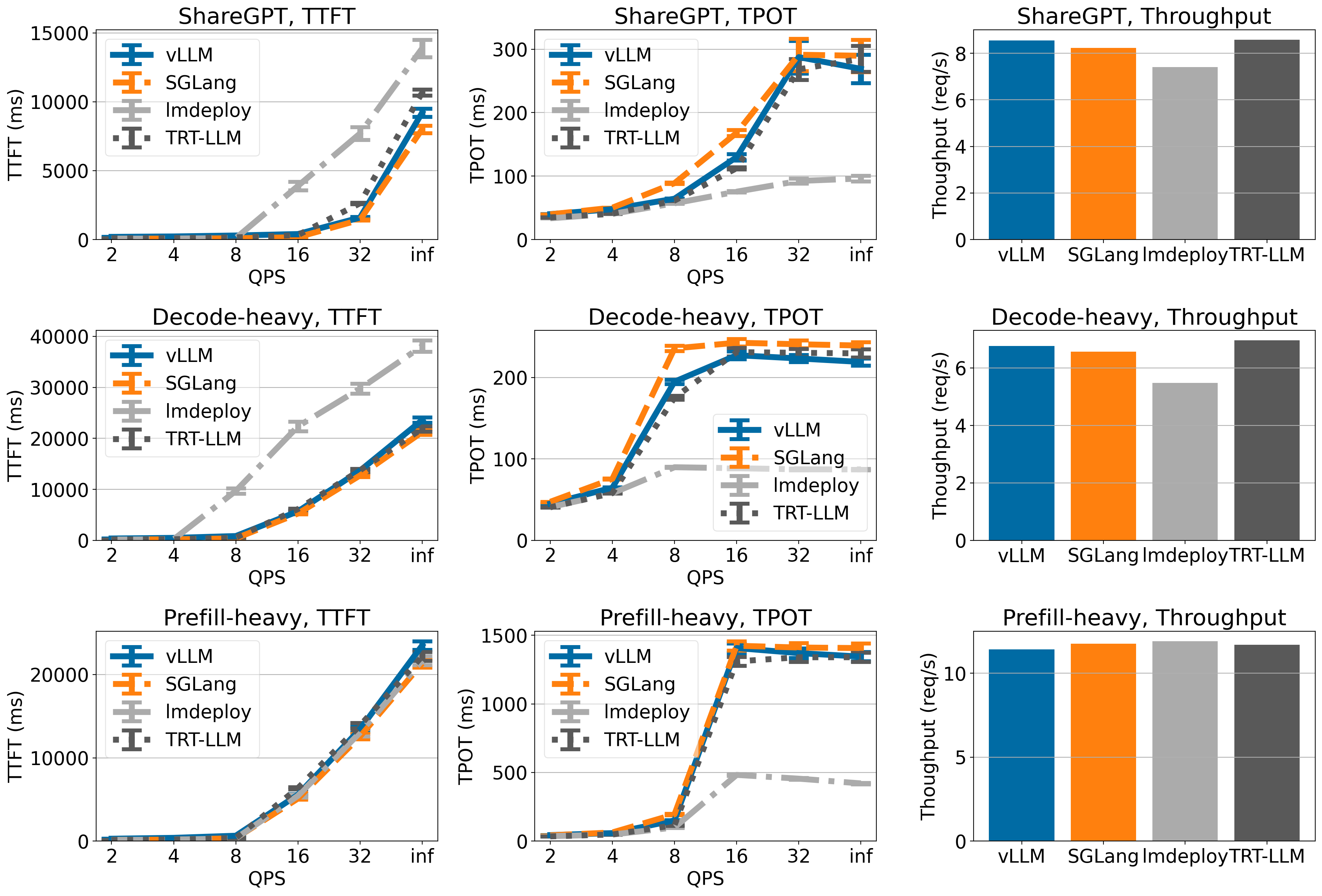
Llama 3 8B on 1xH100
vLLM achieves state-of-the-art throughput on ShareGPT and Decode-heavy dataset, though it has lower throughput on Prefill-heavy dataset.
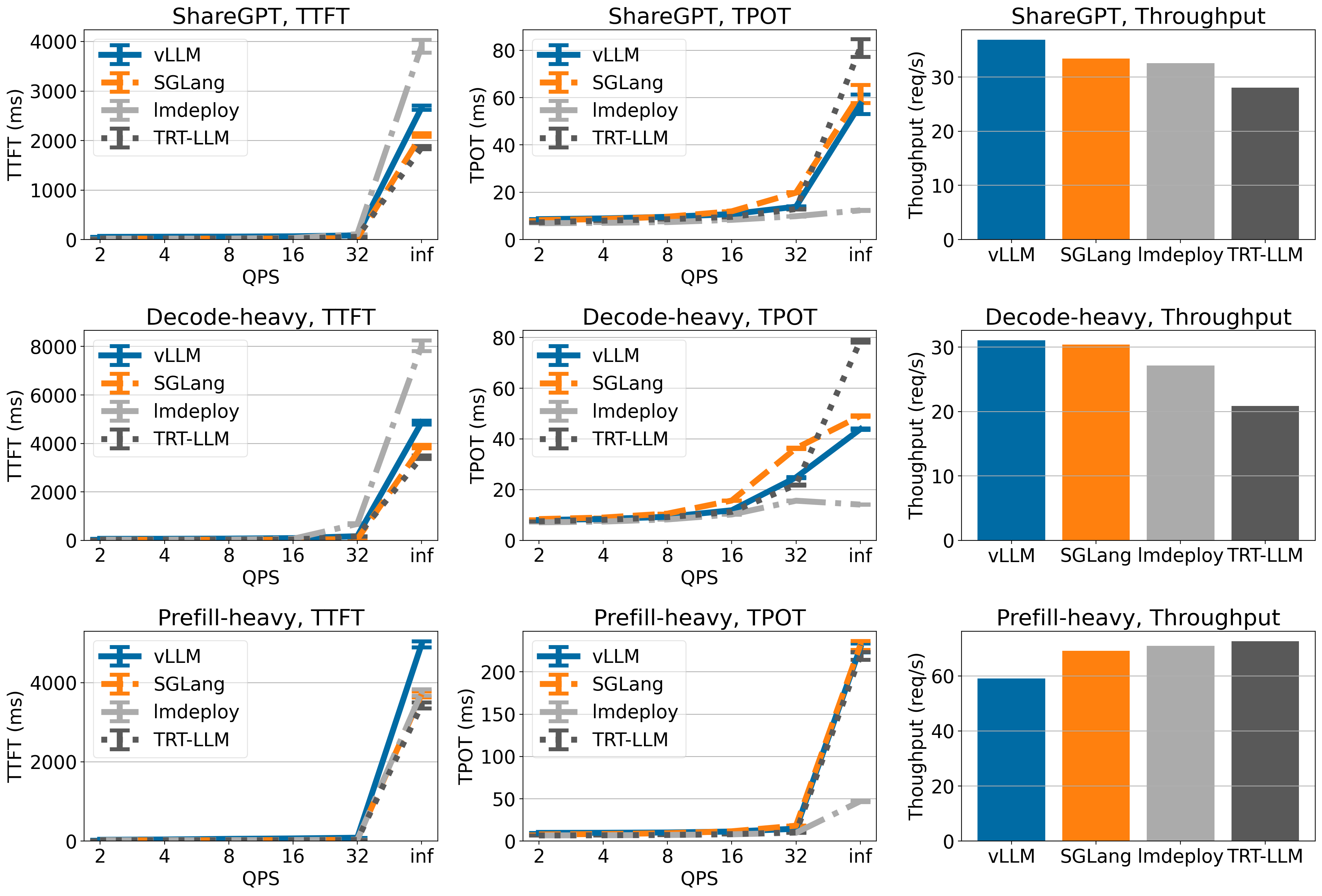
Llama 3 70B on 4xH100
vLLM has highest throughput on ShareGPT and Decode-heavy dataset (though the throughput is only marginally higher than TensorRT-LLM), but the throughput of vLLM is lower on Prefill-heavy dataset.