vLLM 2024 Retrospective and 2025 Vision
The vLLM community achieved remarkable growth in 2024, evolving from a specialized inference engine to become the de facto serving solution for the open-source AI ecosystem. This transformation is reflected in our growth metrics:
- GitHub stars grew from 14,000 to 32,600 (2.3x)
- Contributors expanded from 190 to 740 (3.8x)
- Monthly downloads surged from 6,000 to 27,000 (4.5x)
- GPU hours increased approximately 10x over the last six months
- Explore more usage data at https://2024.vllm.ai
vLLM has established itself as the leading open-source LLM serving and inference engine, with widespread adoption in production applications (e.g., powering Amazon Rufus and LinkedIn AI features). Our bi-monthly meetups have become strategic gatherings for partnerships with industry leaders like IBM, AWS, and NVIDIA, marking our progress toward becoming the universal serving solution for the open-source AI ecosystem. Read on for more details about vLLM’s 2024 achievements and 2025 roadmap!
This blog is based on the 16th session of the bi-weekly vLLM Office Hours. Watch the recording here.
2024 Achievements: Scaling Models, Hardware, and Features
Community Contributions and Growth
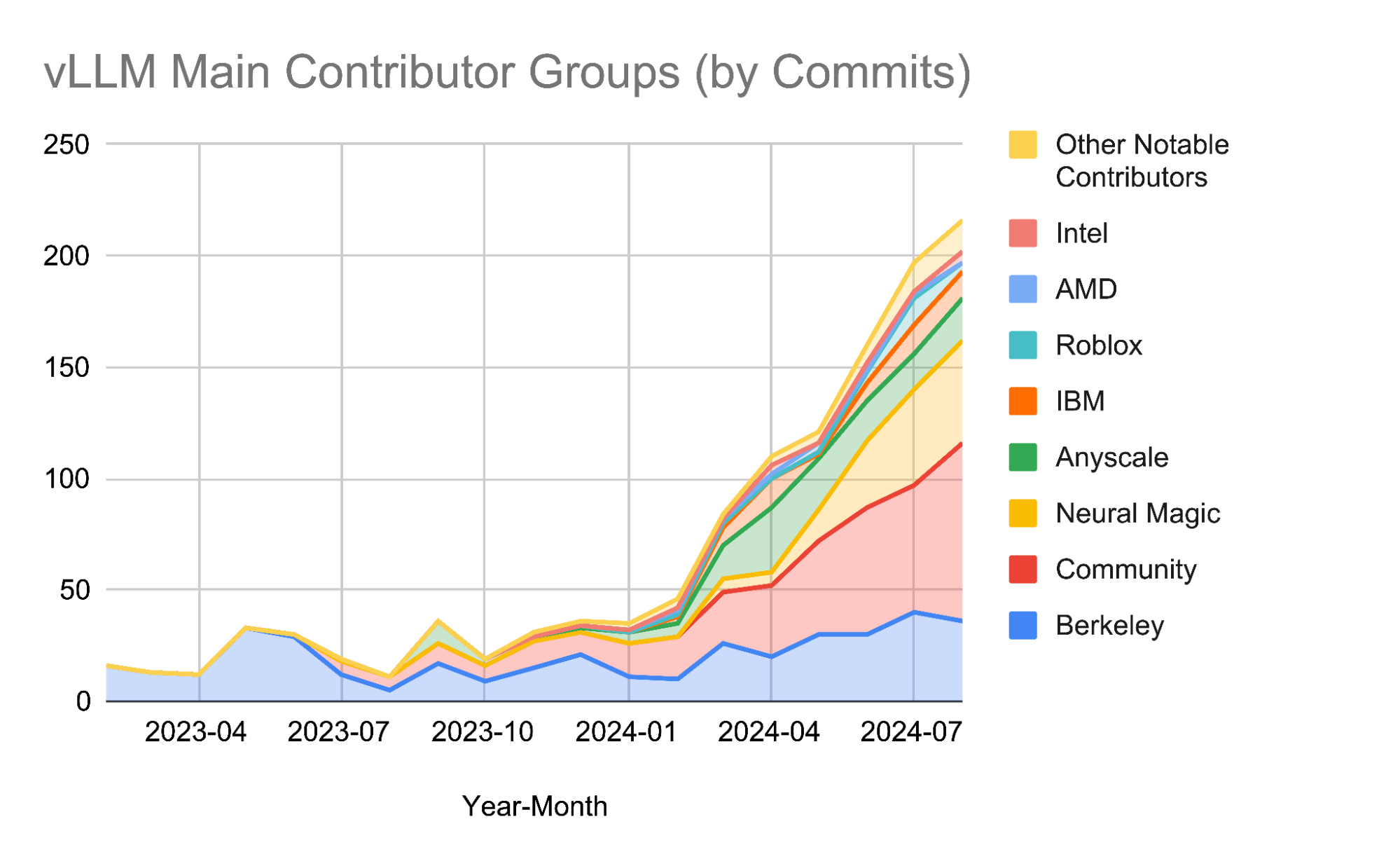
2024 was an exceptional year for vLLM! Our contribution community has expanded dramatically to include:
- 15+ full-time contributors across 6+ organizations
- 20+ active organizations as key stakeholders and sponsors
- Contributions from top institutions including UC Berkeley, Neural Magic, Anyscale, Roblox, IBM, AMD, Intel, and NVIDIA, as well as individual developers worldwide
- A thriving ecosystem connecting model creators, hardware vendors, and optimization developers
- Well-attended bi-weekly office hours facilitating transparency, community growth, and strategic partnerships
These numbers reflect more than growth—they demonstrate vLLM’s role as critical infrastructure in the AI ecosystem, supporting everything from research prototypes to production systems serving millions of users.
Expanding Model Support
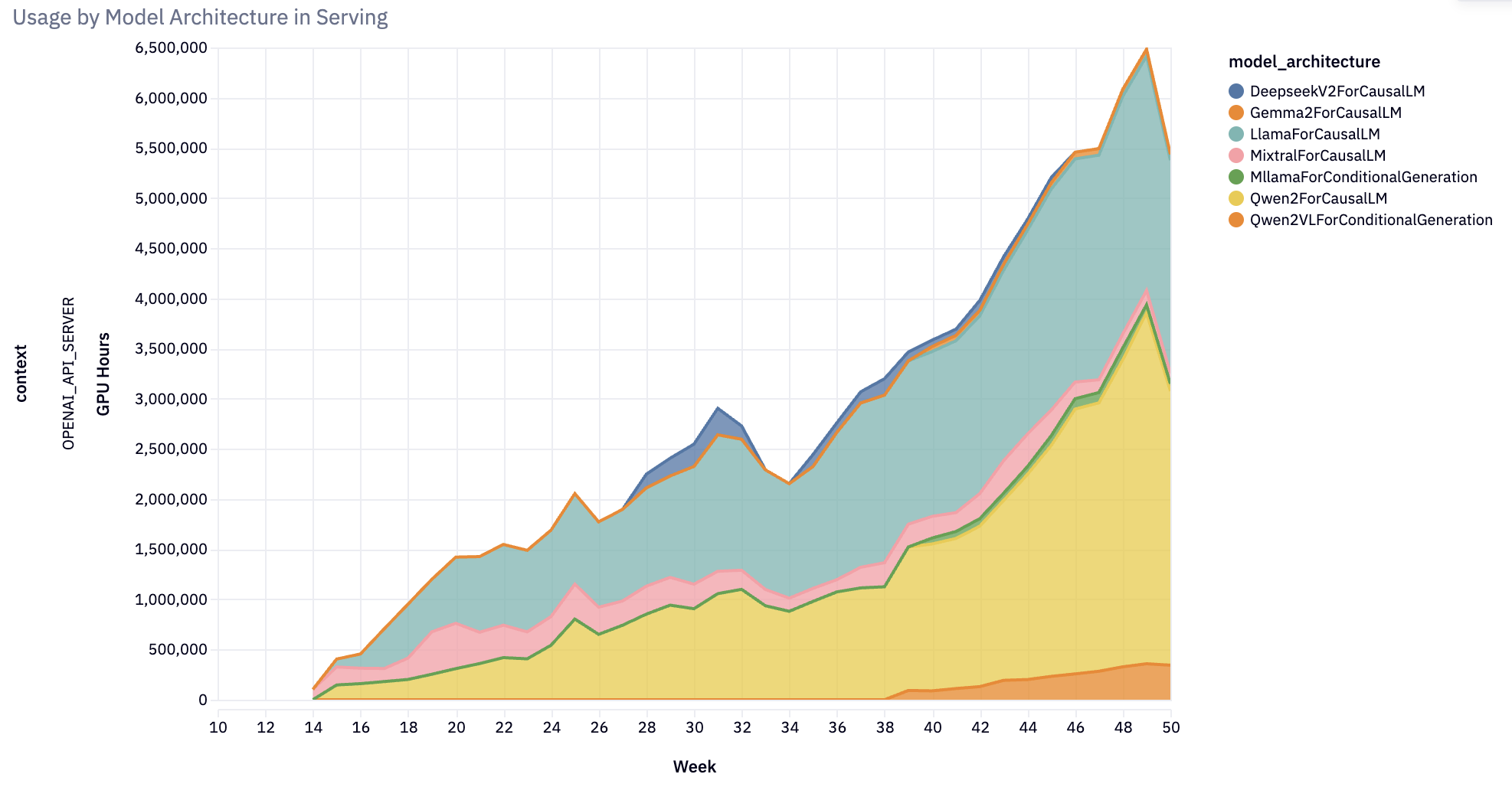
At the beginning of 2024, vLLM supported only a handful of models. By year’s end, the project had evolved to support performant inference for almost 100 model architectures: spanning nearly every prominent open-source large language model (LLM), multimodal (image, audio, video), encoder-decoder, speculative decoding, classification, embedding, and reward models. Notably, vLLM introduced production support for state-space language models, exploring the future of non-transformer language models.
Broadening Hardware Compatibility
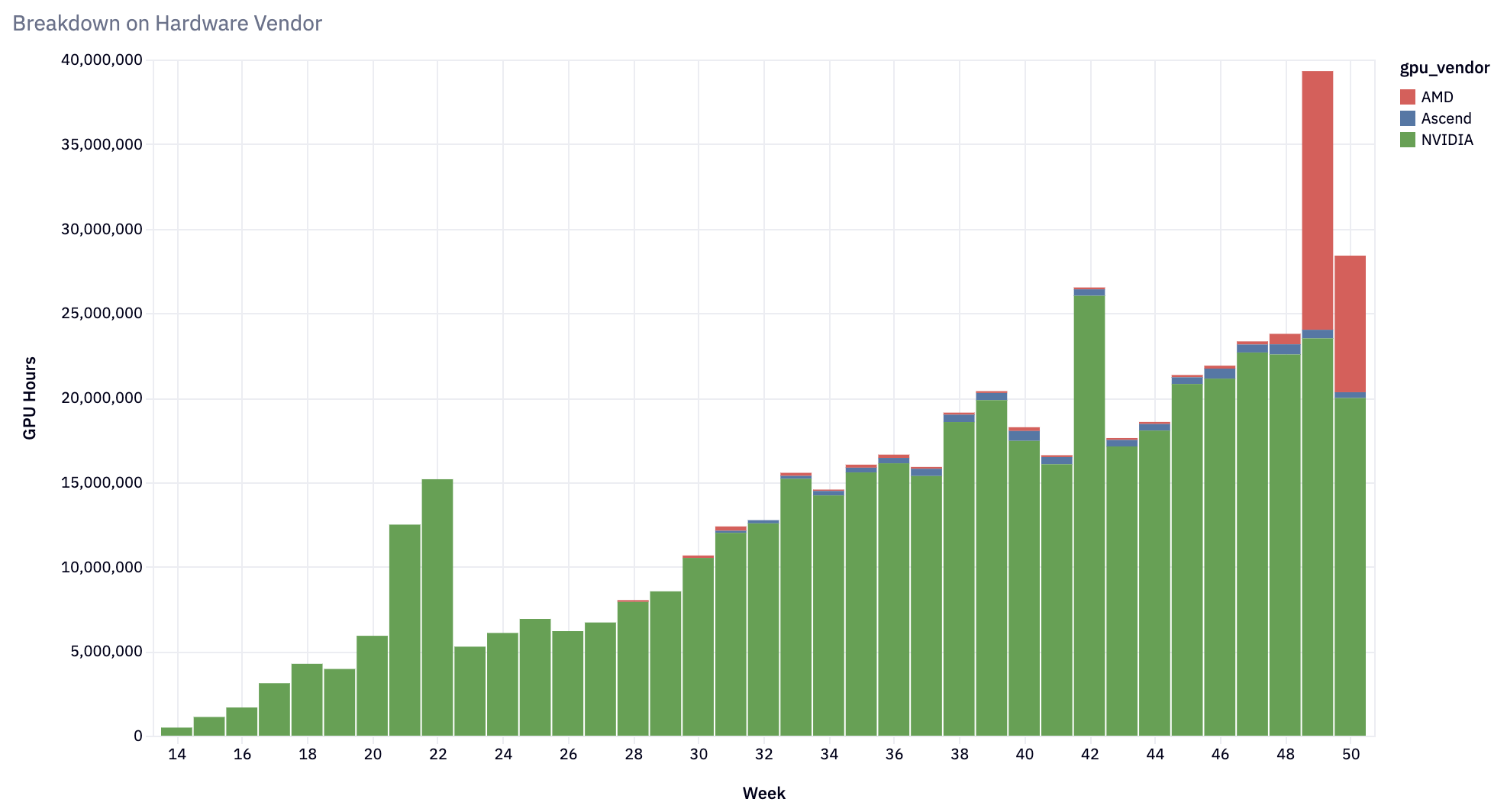
From the initial hardware target of NVIDIA A100 GPUs, vLLM has expanded to support:
- NVIDIA GPUs: First-class optimizations for H100, with support for every NVIDIA GPU from V100 and newer.
- AMD GPUs: Support for MI200, MI300, and Radeon RX 7900 series - with rapidly growing adoption for MI300X.
- Google TPUs: Support for TPU v4, v5p, v5e, and the latest v6e.
- AWS Inferentia and Trainium: Supports for trn1/inf2 instances.
- Intel Gaudi (HPU) and GPU (XPU): Leveraging Intel GPU and Gaudi architectures for AI workloads.
- CPUs: Featuring support for a growing list of ISAs - x86, ARM, and PowerPC.
vLLM’s hardware compatibility has broadened to address diverse user requirements while incorporating performance improvements. Importantly, vLLM is on the path to ensure that all models work on all hardware platforms, with all the optimizations enabled.
Delivering Key Features
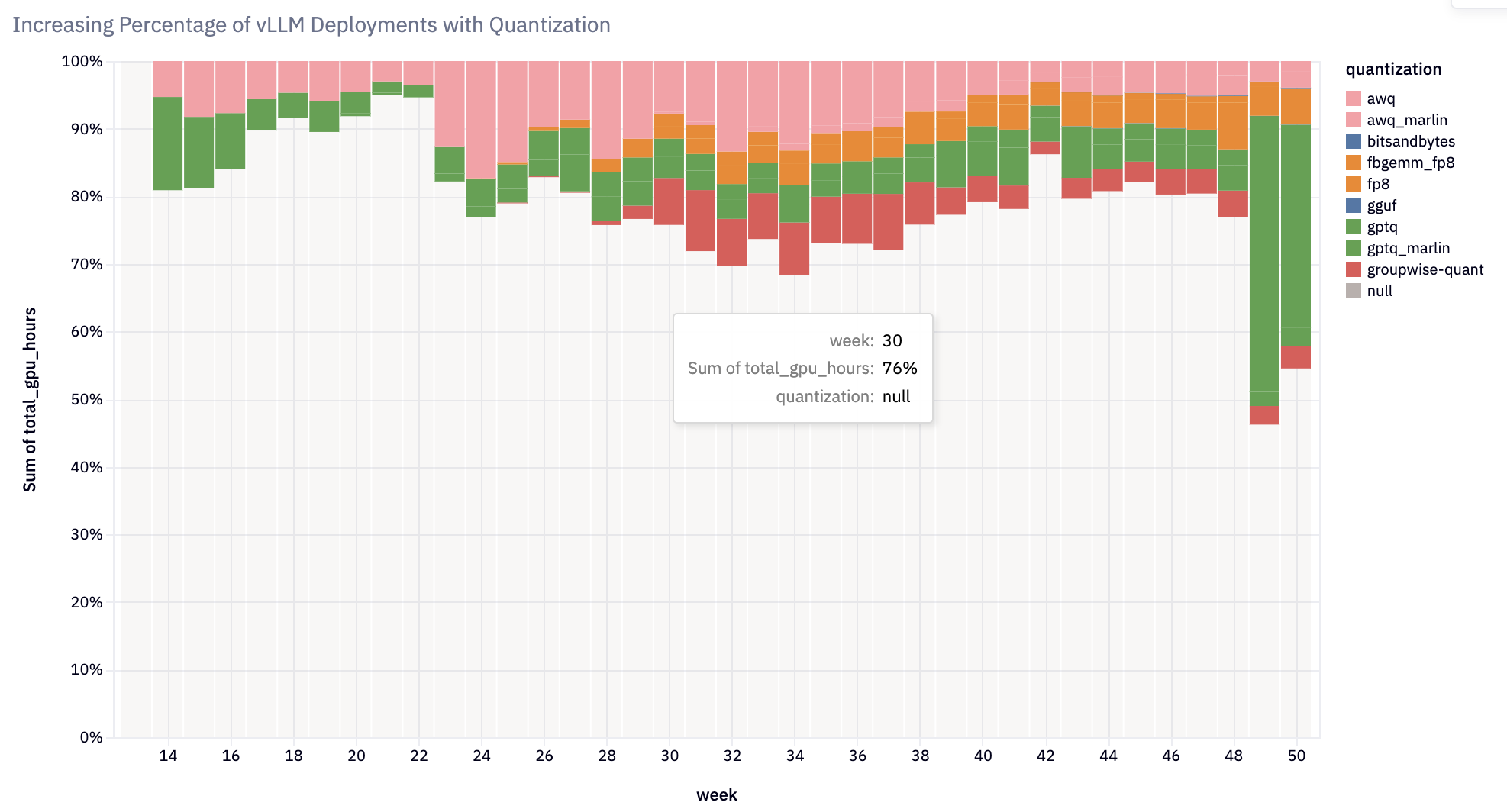
vLLM’s 2024 development roadmap emphasized performance, scalability, and usability:
- Weight and Activation Quantization: Added support for diverse quantization methods and kernels, enabling efficient inference across hardware platforms. Notable integrations include activation quantization for FP8+INT8, Marlin+Machete kernels for GPTQ/AWQ/wNa16, FP8 KV Cache, AQLM, QQQ, HQQ, bitsandbytes, and GGUF. Over 20% of vLLM deployments now use quantization.
- Automatic Prefix Caching: Reduced costs and improved latency for context-heavy applications.
- Chunked Prefill: Enhanced stability of inter-token latency for interactive applications.
- Speculative Decoding: Accelerated token generation through simultaneous token prediction and validation, supporting draft models, n-gram matching in prompts, and MLP speculators like Medusa or EAGLE.
- Structured Outputs: Provided high-performance capabilities for applications requiring specific formats like JSON or pydantic schemas.
- Tool Calling: Enabled models with supported chat templates to generate tool calls autonomously, facilitating data processing and agentic flows.
- Distributed Inference: Introduced pipeline parallelism and disaggregated prefill to effectively scale workloads across GPUs and nodes.
Our 2025 Vision
In 2025, we anticipate a significant push in the boundaries of scaling for both pretraining and inference-time scaling. We believe that open-source models are rapidly catching up to proprietary ones, and through distillation, these massive models are becoming smaller, more intelligent, and more practical for production deployment.
Emerging Model Capabilities: GPT-4o Class Models served on single node
Our vision is ambitious yet concrete: enabling GPT-4o level performance on a single GPU, GPT-4o on a single node, and next generation scale capabilities on a modest cluster. To achieve this, we’re focusing on three key optimization frontiers:
-
KV cache and attention optimization with sliding windows, cross-layer attention, and native quantization
-
MoE optimizations targeting architecture with shared experts and large numbers of fine-grained experts
-
Extended long context support through alternative architectures like state space models
Beyond raw performance, we’re tailoring vLLM for specialized vertical applications. Each use case demands specific optimizations: reasoning applications need custom tokens and flexible reasoning steps, coding requires fill-in-the-middle capabilities and prompt lookup decoding, agent frameworks benefit from tree-based caching, and creative applications need diverse sampling strategies including beam search variants and contrastive decode.
We’re also expanding vLLM’s role in the model training process. Recent adoption by prominent researchers like John Schulman signals our growing importance in post-training workflows. We’ll provide tight integration with data curation and post-training processes, making vLLM an essential tool across the full AI development lifecycle.
Practical Scale: Powering Thousands of Production Clusters
As LLMs become the backbone of modern applications, we envision vLLM powering thousands of production clusters running 24/7. These aren’t experimental deployments—they’re mission-critical systems handling constant traffic for product features, maintained by dedicated platform teams.
To support this scale, we’re making vLLM truly battery-included for production applications. Quantization, prefix caching, and speculative decoding will become default features rather than optional optimizations. Structured output generation will be standard rather than exceptional. We’re developing comprehensive recipes for routing, caching, and auto-scaling that span the full lifecycle of production deployments.
As deployments scale beyond single replicas, we’re creating stable interfaces for cluster-level solutions. This includes robust default configurations tuned for popular models and hardware platforms, along with flexible optimization paths for diverse use cases. We’re fostering a community dedicated to pushing the boundaries of vLLM efficiency, ensuring our platform evolves to meet new challenges.
Open Architecture: The Foundation of Our Future
The key to vLLM’s continued success lies in its open architecture. We’re shipping a ground-up rearchitecture with our V1 release that exemplifies this philosophy. Every component – from model architectures to scheduling policies, memory management to sampling strategies – is designed to be modified and extended in both research and private forks.
Our commitment to openness extends beyond just code. We’re introducing:
-
Pluggable architectures for seamless integration of new models, hardware backends, and custom extensions
-
First-class
torch.compilesupport, enabling custom operation fusion passes and rapid experimentation -
A flexible component system that supports private extensions while maintaining core stability
We’re doubling down on community development, coordinating engineering efforts across organizations while celebrating ecosystem projects. This includes growing our core team through a clear recruitment process and organizational structure. The goal isn’t just to make vLLM the best choice technically – it’s to ensure that everyone who invests in vLLM finds themselves better off for having done so.
Our architecture is more than just a technical choice; it’s a commitment to creating a connected ecosystem through extensibility and modification rather than lock-in. By making vLLM both powerful and customizable, we ensure its place at the heart of the AI inference ecosystem.
A Bit of Reflection
As we reflect on vLLM’s journey, some key themes emerge that have shaped our growth and continue to guide our path forward.
Building Bridges in the AI Ecosystem
What started as an inference engine has evolved into something far more significant: a platform that bridges previously distinct worlds in the AI landscape. Model creators, hardware vendors, and optimization specialists have found in vLLM a unique amplifier for their contributions. When hardware teams develop new accelerators, vLLM provides immediate access to a broad application ecosystem. When researchers devise novel optimization techniques, vLLM offers a production-ready platform to demonstrate real-world impact. This virtuous cycle of contribution and amplification has become core to our identity, driving us to continuously improve the platform’s accessibility and extensibility.
Managing Growth While Maintaining Excellence
Our exponential growth in 2024 brought both opportunities and challenges. The rapid expansion of our codebase and contributor base created unprecedented velocity, enabling us to tackle ambitious technical challenges and respond quickly to community needs. However, this growth also increased the complexity of our codebase. Rather than allowing technical debt to accumulate, we made the decisive choice to invest in our foundation. The second half of 2024 saw us undertake an ambitious redesign of vLLM’s core architecture, culminating in what we now call our V1 architecture. This wasn’t just a technical refresh – it was a deliberate move to ensure that our platform remains maintainable and modular as we scale to meet the needs of an expanding AI ecosystem.
Pioneering a New Model of Open Source Development
Perhaps our most unique challenge has been building a world-class engineering organization through a network of sponsored volunteers. Unlike traditional open source projects that rely on funding from a single organization, vLLM is charting a different course. We’re creating a collaborative environment where multiple organizations contribute not just code, but resources and strategic direction. This model brings novel challenges in coordination, planning, and execution, but it also offers unprecedented opportunities for innovation and resilience. We’re learning – and sometimes inventing – best practices for everything from distributed decision-making to remote collaboration across organizational boundaries.
Our Unwavering Commitment
Through all these changes and challenges, our fundamental mission remains clear: building the world’s fastest and easiest-to-use open-source LLM inference and serving engine. We believe that by lowering the barriers to efficient AI inference, we can help make advanced AI applications more practical and accessible for everyone. This isn’t just about technical excellence – it’s about creating a foundation that enables the entire AI community to move forward faster, together.
Usage Data Collection
The metrics and insights throughout this post are powered by vLLM’s usage system, which collects anonymized deployment data. Each vLLM instance generates a UUID and reports technical metrics including:
- Hardware specs (GPU count/type, CPU architecture, available memory)
- Model configuration (architecture, dtype, tensor parallelism degree)
- Runtime settings (quantization type, prefix caching enabled)
- Deployment context (cloud provider, platform, vLLM version)
This telemetry helps prioritize optimizations for common hardware configurations and identify which features need performance improvements. The data is collected locally in ~/.config/vllm/usage_stats.json. Users can opt out by setting VLLM_NO_USAGE_STATS=1, DO_NOT_TRACK=1, or creating ~/.config/vllm/do_not_track. The implementation details and full schema are available in our usage stats documentation.
Join the Journey
vLLM’s 2024 journey demonstrates the transformative potential of open-source collaboration. With a clear vision for 2025, the project is poised to redefine AI inference, making it more accessible, scalable, and efficient. Whether through code contributions, attending vLLM Office Hours, or adopting vLLM in production, every participant helps shape the future of this fast-moving project.
As we enter 2025, we continue to encourage community participation through:
- Contributing Code: Help refine vLLM’s core functionality or extend its capabilities—many RFCs and features need additional support
- Providing Feedback: Share insights on features and use cases to shape vLLM’s roadmap via GitHub, Slack, Discord, or events
- Building with vLLM: Adopt the platform in your projects, develop your expertise, and share your experience
Join the vLLM Developer Slack to get mentored by project leaders and work at the forefront of AI inference innovation.
Together, we’ll advance open-source AI innovation in 2025!