Llama 4 in vLLM
We’re excited to announce that vLLM now supports the Llama 4 herd of models: Scout (17B-16E) and Maverick (17B-128E). You can run these powerful long-context, natively multi-modal (up to 8-10 images with good results), mixture-of-experts models in vLLM today by updating to version v0.8.3 or later:
pip install -U vllm
Below, you’ll find sample commands to get started. Alternatively, you can replace the CLI command with docker run (instructions here) or use our Pythonic interface, the LLM class, for local batch inference. We also recommend checking out the demo from the Meta team showcasing the 1M long context capability with vLLM.
Usage Guide
Here’s how you can serve the Llama 4 models using different hardware configurations.
Using 8xH100, vLLM can serve Scout with 1M context and Maverick with about 430K. See more tips below for performance enhancement and leveraging long context.
On 8x H100 GPUs:
- Scout (up to 1M context):
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 8 \
--max-model-len 1000000 --override-generation-config='{"attn_temperature_tuning": true}'
- Maverick (up to ~430K context):
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 \
--tensor-parallel-size 8 \
--max-model-len 430000'
On 8x H200 GPUs:
- Scout (up to 3.6M context):
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 8 \
--max-model-len 3600000'
- Maverick (up to 1M context):
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 \
--tensor-parallel-size 8
--max-model-len 1000000'
Multimodality:
The Llama 4 models excel at image understanding up to 8-10 images. By default, vLLM server accepts 1 image per request. Please pass --limit-mm-per-prompt image=10 to serve up to 10 images per request with OpenAI-compatible API. We also recommend checking out our multi-image offline inference example with Llama-4 here.
Performance:
With the configurations above, we observe the following output tokens/s for Scout-BF16 and Maverick-FP8:
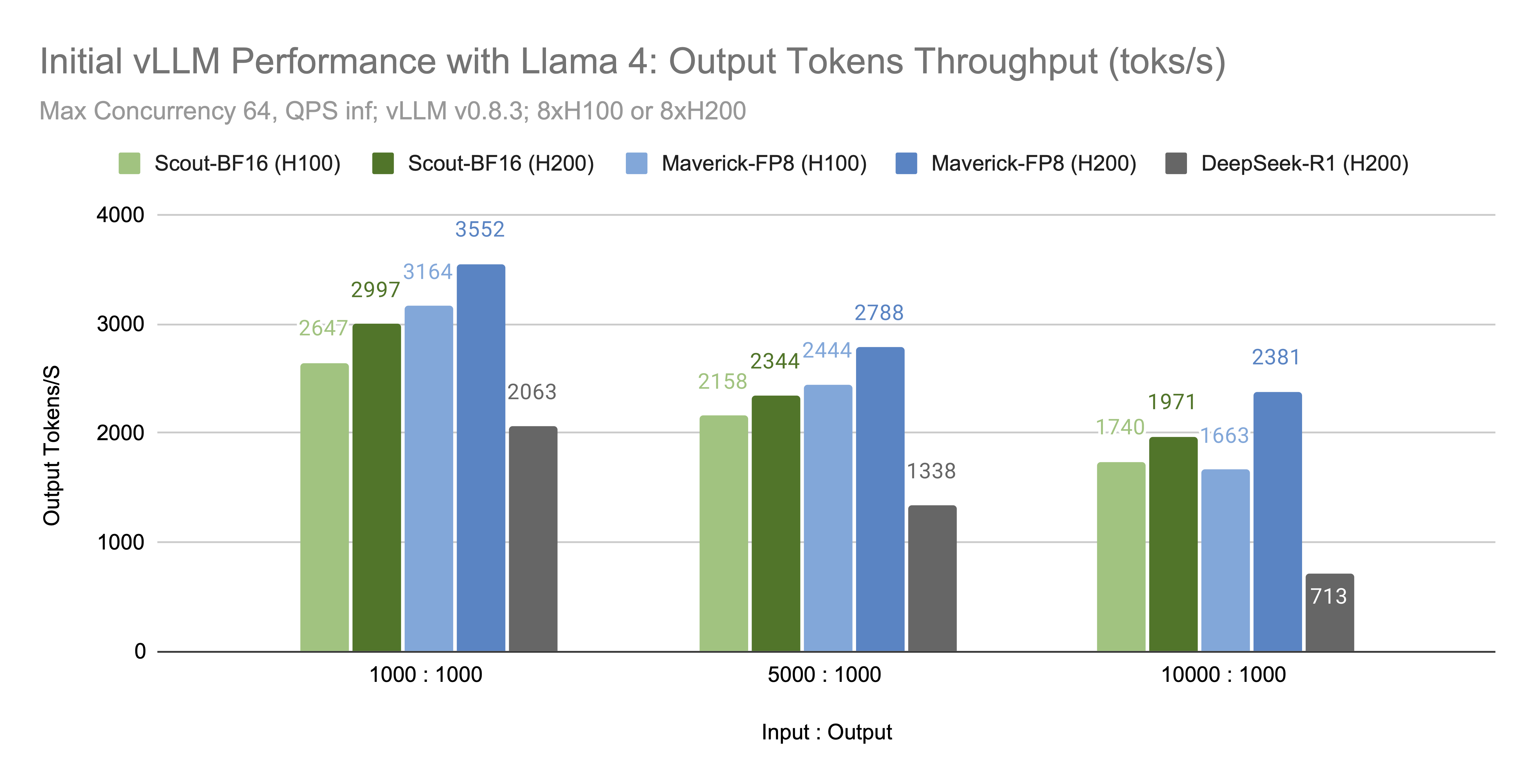
While more performance enhancements are on the way, we believe the Llama 4 models’ efficient architecture and relatively small size make them practical for scaled usage today.
Tips for Performance and Long Context:
- Boost Performance & Context Length: Set
--kv-cache-dtype fp8to potentially double the usable context window and gain a performance boost. We observe little to no accuracy drop in relevant evaluations with this setting. - Maximize Context Window (up to 10M): To fully utilize the maximum context windows (up to 10M for Scout), we recommend serving across multiple nodes using tensor parallelism or pipeline parallelism. Follow our distributed inference guide here.
Other Hardware Support & Quantizations:
- A100: We have verified that the bf16 versions of the models work well on A100 GPUs.
- INT4: An INT4-quantized version of the Scout model checkpoint that fits on a single H100 GPUis currently a work in progress. Stay tuned for updates.
- AMD MI300X: You can run Llama 4 on AMD MI300X GPUs by building vLLM from source and using the same commands as above.
Inference Accuracy Validation: We validated inference accuracy against the official Meta report using lm-eval-harness. Here are the results for meta-llama/Llama-4-Maverick-17B-128E-Instruct:
| MMLU Pro | ChartQA | |
|---|---|---|
| Reported | 80.5 | 90 |
| H100 FP8 | 80.4 | 89.4 |
| AMD MI300x BF16 | 80.4 | 89.4 |
| H200 BF16 | 80.2 | 89.3 |
Efficient Architecture and Cluster Scale Serving
Llama 4’s model architecture is particularly well-suited for efficient long-context inference, thanks to features like:
- Mixture of Experts (MoE): Scout uses 16 experts (17B activated parameters), and Maverick uses 128 experts (17B activated parameters). Only one expert is activated per token, maintaining efficiency.
- Interleaved RoPE (iRoPE): Llama 4 interleaves global attention (without RoPE) with chunked local attention (with RoPE) in a 1:3 ratio. The local attention layer attends to tokens in non-overlapping chunks, significantly reducing the quadratic complexity of attention as context length scales.
vLLM recently launched the V1 engine, delivering major performance speedups on single nodes, along with native torch.compile support. Our Q2 roadmap focuses on enhancing vLLM’s multi-node scaling capabilities, aiming for disaggregated, cluster-scale serving. We are actively adding support for efficient expert parallelism, multi-node data parallelism, and cluster-wide prefill disaggregation.
Acknowledgement
We extend our sincere thanks to the Meta team for their implementation of the model architecture, extensive accuracy evaluation, and performance benchmarking: Lucia (Lu) Fang, Ye (Charlotte) Qi, Lu Fang, Yang Chen, Zijing Liu, Yong Hoon Shin, Zhewen Li, Jon Swenson, Kai Wu, Xiaodong Wang, Shiyan Deng, Wenchen Wang, Lai Wei, Matthias Reso, Chris Thi, Keyun Tong, Jinho Hwang, Driss Guessous, Aston Zhang.
We also thank the AMD team for their support in enabling these models on MI300X: Hongxia Yang and Weijun Jiang.
The vLLM team’s performance benchmarks were run on hardware generously provided by Nebius and NVIDIA.