Accelerating RLHF with vLLM, Best Practice from OpenRLHF
As demand grows for training reasoning-capable large language models (LLMs), Reinforcement Learning from Human Feedback (RLHF) has emerged as a cornerstone technique. However, conventional RLHF pipelines—especially those using Proximal Policy Optimization (PPO)—are often hindered by substantial computational overhead. This challenge is particularly pronounced with models that excel at complex reasoning tasks (such as OpenAI-o1 and DeepSeek-R1), where generating long chain-of-thought (CoT) outputs can account for up to 90% of total training time. These models must produce detailed, step-by-step reasoning that can span thousands of tokens, making inference significantly more time-consuming than the training phase itself. As a pioneering inference framework, vLLM provides a user-friendly interface for generating RLHF samples and updating model weights.
Design of OpenRLHF
To strike a balance between performance and usability in RLHF frameworks, OpenRLHF is designed as a high-performance yet user-friendly solution that integrates key technologies like Ray, vLLM, Zero Redundancy Optimizer (ZeRO-3), and Automatic Tensor Parallelism (AutoTP):
Ray acts as the backbone of OpenRLHF’s distributed architecture. With powerful scheduling and orchestration features, Ray efficiently manages complex data flows and computations, including distributing rule-based reward models across multiple nodes.
vLLM with Ray Executor and AutoTP plays a central role in accelerating inference. With built-in support for Ray Executors and integration with HuggingFace Transformers, it enables efficient weight updates through AutoTP, resulting in high-throughput and memory-efficient LLM generation.
ZeRO-3 with HuggingFace Transformers, a memory optimization approach from DeepSpeed, empowers OpenRLHF to train large models without requiring heavyweight frameworks like Megatron. This seamless integration with HuggingFace allows for simple loading and fine-tuning of pre-trained models.
Together, Ray, vLLM, ZeRO-3, and HuggingFace Transformers create a cutting-edge yet streamlined solution for accelerating RLHF training. The architecture has also influenced other frameworks such as veRL, which adopt similar paradigms for scalable and efficient RLHF training. OpenRLHF is also the first open-source RLHF framework developed based on Ray, vLLM and ZeRO-3, and has been used by Google, Bytedance, Alibaba, Meituan, Berkeley Starling Team etc.
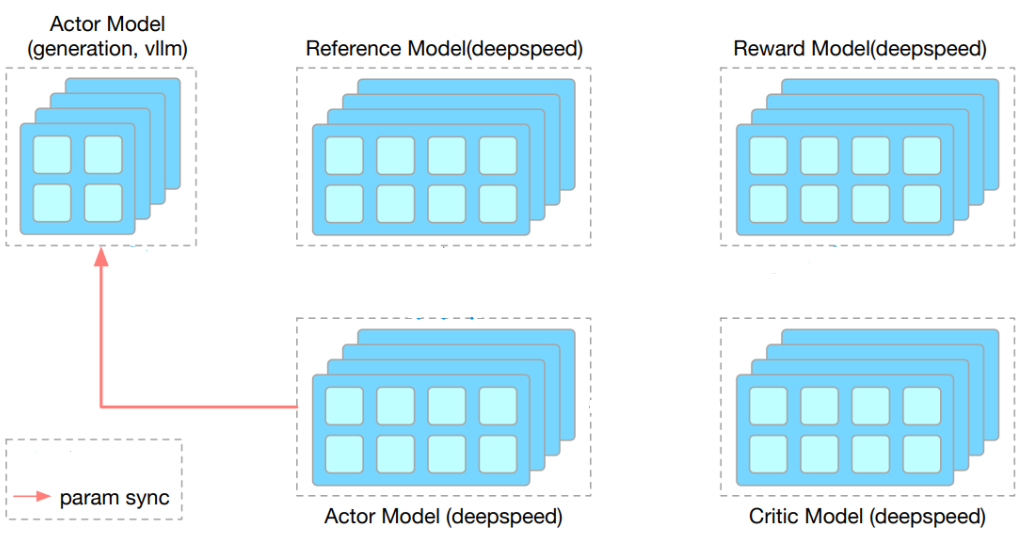
As illustrated above, OpenRLHF uses Ray’s Placement Group API to flexibly schedule components of the RLHF pipeline, including the vLLM engine, Actor, Critic, Reference, and Reward models. Although represented separately, these components can be colocated in shared Ray placement groups to maximize resource efficiency. For example, all modules can operate within the same GPU group in a hybrid engine configuration, or specific components—such as the Actor and Critic—can be grouped together. All modules are orchestrated by a central Ray Actor, which manages the entire training lifecycle. Weight synchronization between the Actor and the vLLM engine is handled via high-performance communication methods, such as NVIDIA Collective Communications Library (NCCL) or CUDA Inter-Process Communication (IPC) memory transfers in hybrid engine settings.
Implementing RLHF Acceleration with vLLM Ray Executor
OpenRLHF and vLLM provide a clean and efficient set of APIs to simplify interaction within RLHF pipelines. By implementing a custom WorkerExtension class, users can handle weight synchronization between training and inference components. The environment variables VLLM_RAY_PER_WORKER_GPUS and VLLM_RAY_BUNDLE_INDICES allows fine-grained GPU resource allocation per worker, enabling hybrid engine configurations where multiple components share a GPU group:
# rlhf_utils.py
class ColocateWorkerExtension:
"""
Extension class for vLLM workers to handle weight synchronization.
This class ensures compatibility with both vLLM V0 and V1.
"""
def report_device_id(self) -> str:
"""Report the unique device ID for this worker"""
from vllm.platforms import current_platform
self.device_uuid = current_platform.get_device_uuid(self.device.index)
return self.device_uuid
def update_weights_from_ipc_handles(self, ipc_handles):
"""Update model weights using IPC handles"""
handles = ipc_handles[self.device_uuid]
device_id = self.device.index
weights = []
for name, handle in handles.items():
func, args = handle
list_args = list(args)
list_args[6] = device_id # Update device ID for current process
tensor = func(*list_args)
weights.append((name, tensor))
self.model_runner.model.load_weights(weights=weights)
torch.cuda.synchronize()
# main.py
class MyLLM(LLM):
"""
Custom LLM class to handle GPU resource allocation and bundle indices.
This ensures proper GPU utilization and placement group management.
"""
def __init__(self, *args, bundle_indices: list, **kwargs):
# Prevent Ray from manipulating CUDA_VISIBLE_DEVICES at the top level
os.environ.pop("CUDA_VISIBLE_DEVICES", None)
# Configure GPU utilization per worker
os.environ["VLLM_RAY_PER_WORKER_GPUS"] = "0.4"
os.environ["VLLM_RAY_BUNDLE_INDICES"] = ",".join(map(str, bundle_indices))
super().__init__(*args, **kwargs)
# Create Ray's placement group for GPU allocation
pg = placement_group([{"GPU": 1, "CPU": 0}] * 4)
ray.get(pg.ready())
# Create inference engines
inference_engines = []
for bundle_indices in [[0, 1], [2, 3]]:
llm = ray.remote(
num_gpus=0,
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg
)
)(MyLLM).remote(
model="facebook/opt-125m",
tensor_parallel_size=2,
distributed_executor_backend="ray",
gpu_memory_utilization=0.4,
worker_extension_cls="rlhf_utils.ColocateWorkerExtension",
bundle_indices=bundle_indices
)
inference_engines.append(llm)
The complete RLHF example walks through initializing Ray with a specified GPU count, creating a placement group to manage resources, and defining both training actors and inference engines. The training actors manage model initialization and weight updates, while the inference engines serve models via vLLM. Weight synchronization is carried out using CUDA IPC or NCCL, ensuring coherence and efficiency throughout the RLHF pipeline.
Acknowledgements
We would like to express our sincere gratitude to the vLLM contributors, including Kaichao You, Cody Yu, Rui Qiao, and many others, without which the OpenRLHF integration with vLLM will not be possible. Kaichao You from the vLLM team leads the RLHF integration.
The OpenRLHF project is the first open-source RLHF framework based on Ray and vLLM. We would like to thank Jian Hu, Songlin Jiang, Zilin Zhu, Xibin Wu and many others for their significant contributions to the Ray, vLLM Wrapper and Hybrid Engine components of the OpenRLHF project. Jian Hu leads the development.