MiniMax-M1 Hybrid Architecture Meets vLLM: Long Context, Fast Inference
This article explores how MiniMax-M1’s hybrid architecture is efficiently supported in vLLM. We discuss the model’s unique features, the challenges of efficient inference, and the technical solutions implemented in vLLM.
Introduction
The rapid advancement of artificial intelligence has led to the emergence of increasingly powerful large language models (LLMs). MiniMax-M1, a popular open-source large-scale mixture-of-experts (MoE) inference model, has attracted significant attention since its release. Its innovative hybrid architecture points to the future of LLMs, enabling breakthroughs in long-context reasoning and complex task processing. Meanwhile, vLLM, a high-performance LLM inference and serving library, provides robust support for MiniMax-M1, making efficient deployment possible.
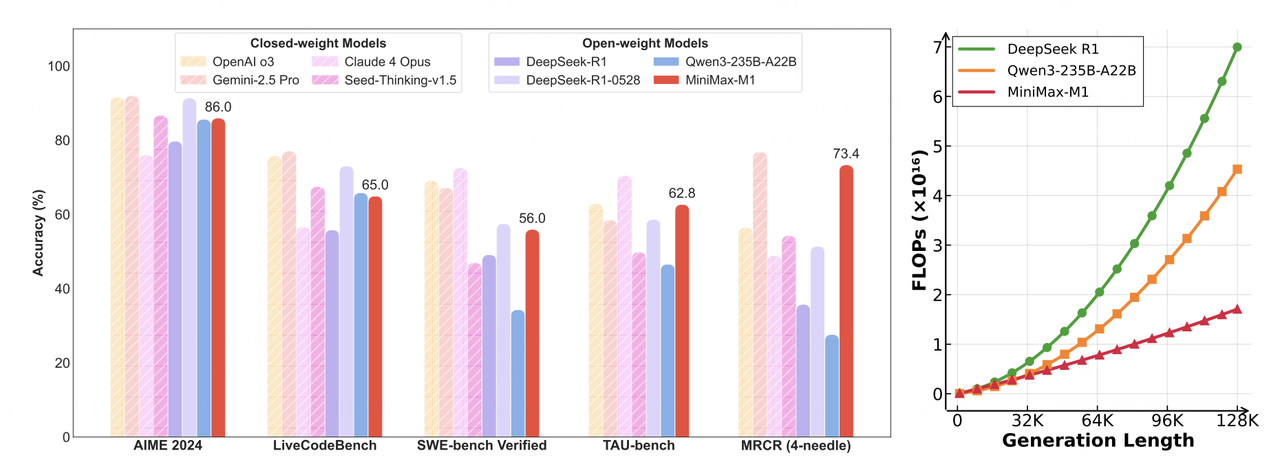
- Left: Benchmark comparison of leading commercial and open-source models on tasks such as math, code, software engineering, tool use, and long-context understanding. MiniMax-M1 leads among open-source models.
- Right: Theoretical inference FLOPs scaling with token length. Compared to DeepSeek R1, MiniMax-M1 uses only 25% of the FLOPs when generating sequences of 100k tokens.
Deploying MiniMax-M1 with vLLM
We recommend deploying MiniMax-M1 using vLLM for optimal performance. Our tests demonstrate the following key benefits:
- Outstanding throughput
- Efficient and intelligent memory management
- Robust support for batched requests
- Deeply optimized backend performance
Model Download
You can download the models from Hugging Face:
# Install the Hugging Face Hub CLI
pip install -U huggingface-hub
# Download the MiniMax-M1-40k model
huggingface-cli download MiniMaxAI/MiniMax-M1-40k
# For the 80k version, uncomment the following line:
# huggingface-cli download MiniMaxAI/MiniMax-M1-80k
Deployment
Below is a quick guide to deploying MiniMax-M1 with vLLM and Docker:
# Set environment variables
IMAGE=vllm/vllm-openai:latest
MODEL_DIR=<model storage path>
NAME=MiniMaxImage
# Docker run configuration
DOCKER_RUN_CMD="--network=host --privileged --ipc=host --ulimit memlock=-1 --rm --gpus all --ulimit stack=67108864"
# Start the container
sudo docker run -it \
-v $MODEL_DIR:$MODEL_DIR \
--name $NAME \
$DOCKER_RUN_CMD \
$IMAGE /bin/bash
# Launch MiniMax-M1 Service
export SAFETENSORS_FAST_GPU=1
export VLLM_USE_V1=0
vllm serve \
--model <model storage path> \
--tensor-parallel-size 8 \
--trust-remote-code \
--quantization experts_int8 \
--max_model_len 4096 \
--dtype bfloat16
MiniMax-M1 Hybrid Architecture Highlights
Mixture-of-Experts (MoE)
MiniMax-M1 utilizes a Mixture-of-Experts (MoE) architecture with 456 billion total parameters. During inference, a dynamic routing algorithm activates a sparse subset of experts (~45.9B parameters, or 10% of the total), based on the semantic characteristics of input tokens. This sparse activation is managed by a gating network that computes expert selection probabilities.
This approach significantly improves computational efficiency: in classification tasks, it reduces computational cost by up to 90% while maintaining accuracy comparable to dense models.
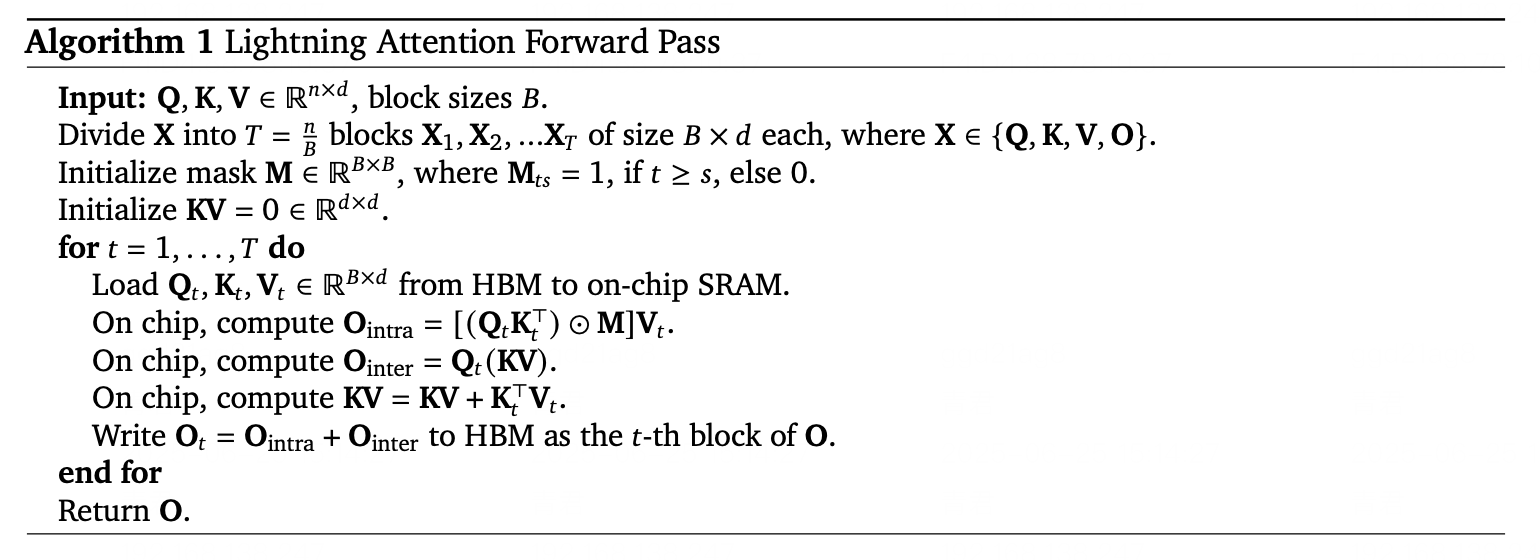
Lightning Attention
Lightning Attention addresses the quadratic complexity bottleneck of traditional attention by introducing linearized approximation techniques. It transforms softmax attention into a linear combination of matrix multiplications, aided by dynamic memory tiling and gradient approximation.
In code completion benchmarks, Lightning Attention reduces memory usage by 83% and inference latency by 67% for 100k-token sequences.
Efficient Computation & Activation Strategy
Thanks to its hybrid architecture, MiniMax-M1 enables efficient computation and scalable inference. The Lightning Attention mechanism dramatically improves runtime performance, while the sparse expert activation strategy avoids unnecessary computation. This makes it feasible to achieve strong performance even with limited hardware resources.
To learn more about MiniMax-M1 please refer to this paper.
Efficient Inference with vLLM
Advanced Memory Management
vLLM introduces PagedAttention, a technique for managing attention key-value caches more efficiently. Instead of storing the kv-cache contiguously, vLLM divides it into multiple memory pages, greatly reducing fragmentation and over-allocation. This allows vLLM to minimize memory waste to under 4%, compared to 60%-80% with traditional approaches.
Such efficient memory handling is crucial for models like MiniMax-M1 that support ultra-long context lengths, ensuring smooth and stable inference without running into memory bottlenecks.
Deep Kernel-Level Optimizations
vLLM incorporates a wide range of CUDA kernel optimizations, including integrations with FlashAttention, FlashInfer, and support for quantization formats such as GPTQ, AWQ, INT4, INT8, and FP8.
These enhancements further boost the low-level computation efficiency of MiniMax-M1 inference. Quantization reduces memory and compute overhead with minimal accuracy loss, while FlashAttention accelerates the attention computation itself—resulting in significantly faster inference in real-world applications.
Lightning Attention in vLLM
As a cutting-edge attention mechanism, Lightning Attention is implemented in vLLM via Triton, leveraging its flexibility and high-performance computing features. A Triton-based execution framework fully supports Lightning Attention’s core computation logic, enabling seamless integration and deployment within the vLLM ecosystem.
Future Work
Looking ahead, further optimizations for hybrid architecture support are actively being explored within the vLLM community. Notably, the development of a hybrid allocator is expected to enable even more efficient memory management tailored to the unique requirements of models like MiniMax-M1.
In addition, full support for vLLM v1 is planned, with the hybrid model architecture expected to be migrated into the v1 framework. These advancements are anticipated to unlock further performance improvements and provide a more robust foundation for future developments.
Conclusion
The hybrid architecture of MiniMax-M1 paves the way for the next generation of large language models, offering powerful capabilities in long-context reasoning and complex task inference. vLLM complements this with highly optimized memory handling, robust batch request management, and deeply tuned backend performance.
Together, MiniMax-M1 and vLLM form a strong foundation for efficient and scalable AI applications. As the ecosystem evolves, we anticipate this synergy will power more intelligent, responsive, and capable solutions across a wide range of use cases, including code generation, document analysis, and conversational AI.
Acknowledgement
We would like to express our sincere gratitude to the vLLM community for their invaluable support and collaboration. In particular, we thank Tyler Michael Smith, Simon Mo, Cyrus Leung, Roger Wang, Zifeng Mo and Kaichao You for their significant contributions. We also appreciate the efforts of the MiniMax engineering team, especially Gangying Qing, Jun Qing, and Jiaren Cai, whose dedication made this work possible.