Serving Geospatial, Vision, and Beyond: Enabling Multimodal Output Processing in vLLM
Introduction
Until recently, generative AI infrastructure has been tightly coupled with autoregressive text generation models that produce output token-by-token, typically in the form of natural language. vLLM has been following the trend by initially supporting models working with text input and output, the traditional LLMs. The trend has started shifting towards multimodal data with the introduction of MLLMs (Multimodal Large Language Models), capable of reasoning on text as well as data in various modalities (e.g., images, video, audio, etc.). Again, vLLM has followed the trend with support for LLaVA-style MLLMs, reasoning on multimodal input data and generating text.
We are now witnessing a new trend shift with a growing class of non-autoregressive models that generate multimodal outputs in a single inference pass, enabling faster and more efficient generation across a wide range of modalities. These models can be seen as pooling models from the inference standpoint, but require additional support for input and output handling. Applications for this type of models can be found in domains beyond text: from image classification and segmentation, to audio synthesis and structured data generation. We’ve made the next step in vLLM and added support for this class of models.
Our initial integration focuses on geospatial foundation models, a class of convolutional or vision transformer models that requires data beyond RGB channels (e.g. multispectral or radar) and metadata (e.g. geolocation, date of image acquisition) used for, but not limited to, tasks like disaster response or land use classification from satellite imagery. However, the changes are generic and pave the way for serving a wide variety of non text-generating models.
As a concrete example, we’ve integrated all geospatial models from the TerraTorch framework (some of which were developed in collaboration with NASA and ESA) into vLLM via a generic backend, making them first-class citizens in the vLLM ecosystem.
In the sections that follow, we describe the technical changes made to vLLM, starting with the requirements and challenges of serving geospatial foundation models.
Integrating Geospatial Foundation Models in vLLM
Unlike text models, geospatial foundation models (often implemented as vision transformers) don’t need token decoding, i.e., they do not need output tokens to be transformed into text. Instead, given one input image, a single inference generates the raw model output, and then this is post-processed into the output image. In addition, sometimes the input image needs to be partitioned and batched into a number of sub-images, or patches. These patches are then fed to the model for inference, with the resulting output images from each patch being stitched together to form the final output image.
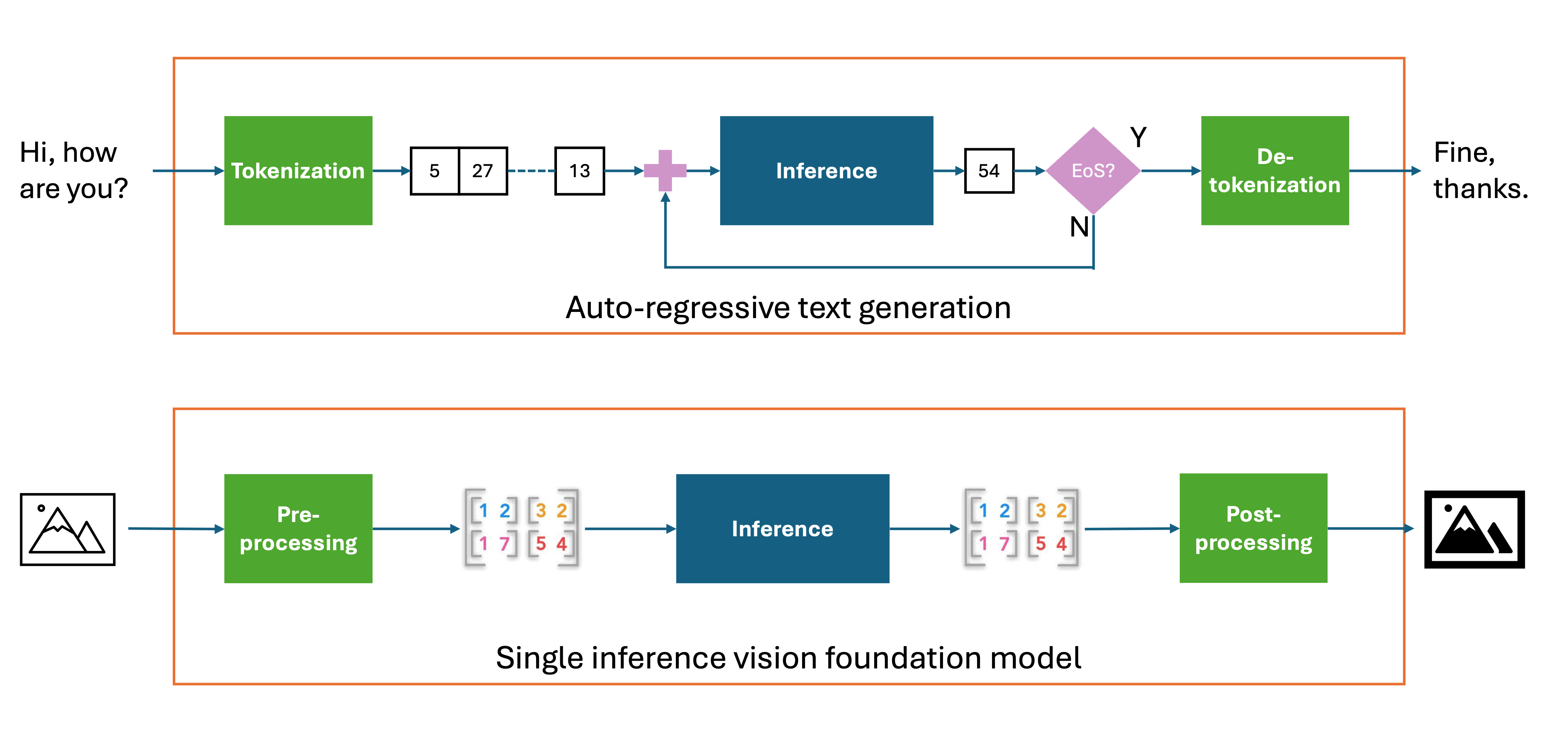
Given these requirements, the obvious choice was to integrate geospatial foundation models in vLLM as pooling models. Pooling is a technique that is commonly used in deep learning models to reduce the spatial dimensions of feature maps. Common types include max pooling, average pooling and global pooling, each using different strategies to aggregate information. In vLLM, pooling can be applied to tasks such as embedding vector calculation and classification. In addition, vLLM supports identity poolers, returning the model’s hidden states without applying any transformations - exactly what we need. For the input, we pre-process images into tensors that are then fed to the model for inference, exploiting the existing multimodal input capabilities of vLLM.
Since we wanted to support multiple geospatial foundation models out-of-the-box in vLLM, we have also added a model implementation backend for TerraTorch models, following the same pattern as the backend for the HuggingFace Transformers library.
Getting this to work was no easy task, though. Enabling these model classes required changes to various parts of vLLM such as:
- adding support for attention free models
- improving support for models that do not require a tokenizer
- enabling processing of raw input data as opposed to the default multimodal input embeddings
- extending the vLLM serving API.
Meet IO Processor: Flexible Input/Output Handling for Any Model
So far so good! Well, this brings us only halfway towards our goal.
With the above integration, we can indeed serve geospatial foundation models – though only in tensor-to-tensor format. Users still have to pre-process their image to a tensor format, before sending the tensors to the vLLM instance. Similarly, post-processing of the raw tensor output has to happen outside vLLM. The impact: there is no endpoint that users can send an image to and get an image back.
This problem existed because, before our changes, pre-processing of input data and post-processing of the model output was only partially supported in vLLM. Specifically, pre-processing of multimodal input data was only possible via the processors available in the Transformers library. However, the transformers processors usually support only standard data types and do not handle more complex data formats such as GeoTIFF, which are image files with enriched geospatial metadata. Also, on the output processing side, vLLM only supported de-tokenization into text or the application of poolers to the model hidden states - no other output processing was possible.
This is where the new IO Processor plugin framework we introduced comes in. The IO Processor framework allows developers to customize how model inputs and outputs are pre- and post-processed, all within the same vLLM serving instance. Whether your model returns a string, a JSON object, an image tensor, or a custom data structure, an IO Processor can translate it into the desired format before returning it to the client.
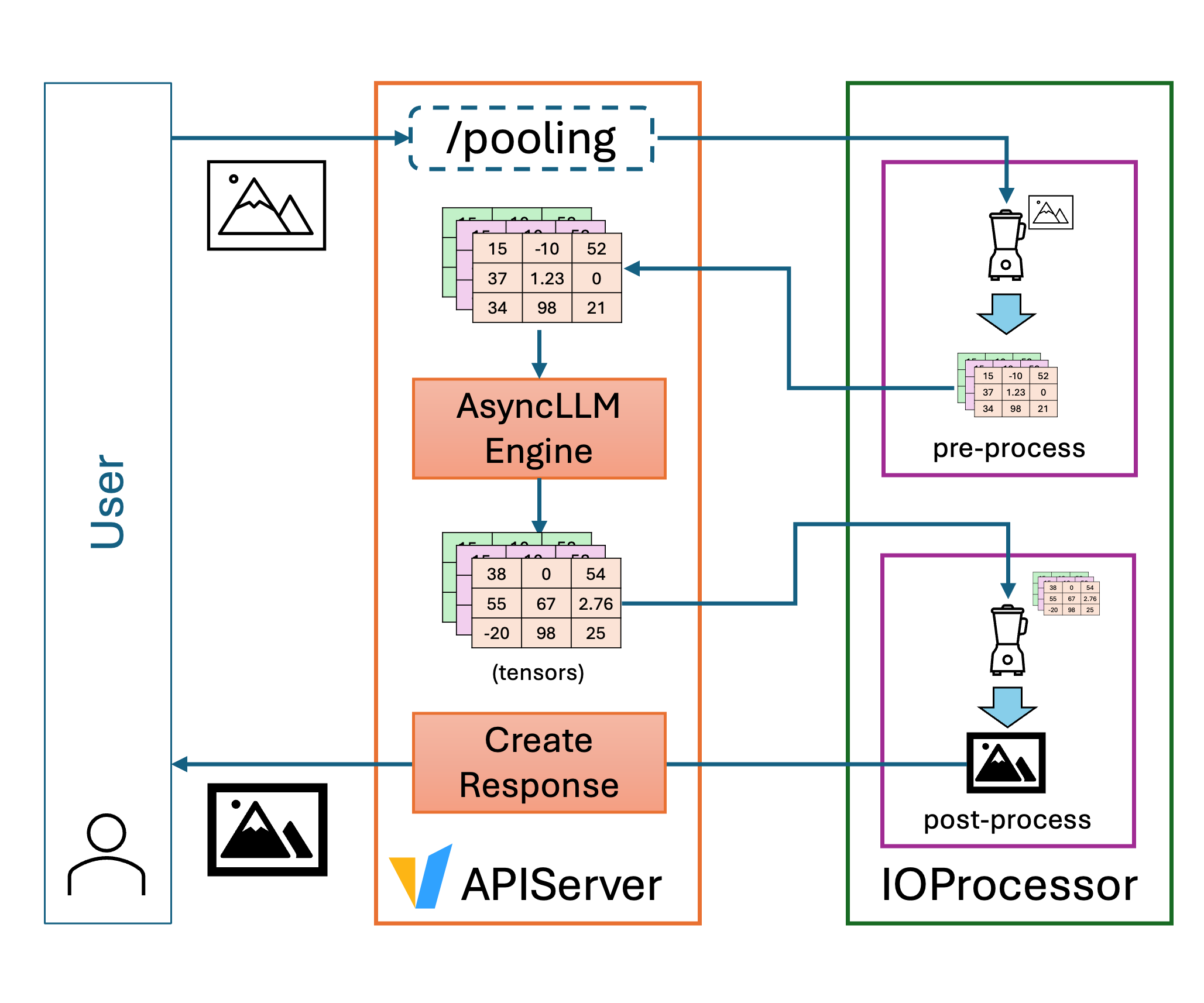
The IO Processor framework unlocks a new level of flexibility for vLLM users. It means non-text models (e.g., image generators, image to segmentation mask, tabular to classification, etc.) can be served using standard vLLM infrastructure. Via IO Processors users can plug in custom logic to transform or enrich outputs such as decoding model outputs into images, or formatting responses for downstream systems. This maintains a unified serving stack, reducing operational complexity and improving maintainability.
Using vLLM IO Processor Plugins
Each IO Processor plugin implements a pre-defined IO Processor interface and resides outside the vLLM source code tree.
At installation time, each plugin registers one or more entrypoints in the vllm.io_processor_plugins group.
This allows vLLM to automatically discover and load plugins at engine initialization time.
Using an IO Processor plugin is as easy as installing it in the same Python environment with vLLM, and adding the --io-processor-plugin <plugin_name> parameter when starting the serving instance.
Currently, each vLLM instance can load one IO Processor plugin.
Once the serving instance is started, pre- and post-processing is automatically applied to the model input and output when serving the /pooling endpoint.
At this stage, IO Processors are only available for pooling models, but in the future we expect other endpoints to be integrated too.
Step-by-Step: Serving the Prithvi Model in vLLM
One example of a model class that can be served with vLLM using the TerraTorch backend is Prithvi for flood detection. A full plugin example for the Prithvi geospatial foundation model is available here.
The Prithvi IO Processor Plugin
To illustrate the flexibility of the IO Processor plugin approach, the pseudocode below shows the main steps of the Prithvi IO Processor pre- and post-processing. What we want to highlight is the decoupling between the data-specific transformations with the model inference data. This makes room for ideally any model and any input/output data type, or even multiple plugins applied to the same model output, depending on the downstream task that consumes the data.
def pre_process(request_data: dict):
# Downloads geotiff
# In this example the input image has 7 bands
image_url = request_data["url"]
image_obj = download_image(image_url)
# Extract image data:
# - pixel_values([n, 6, 512, 512])
# - 6 input bands R, G, B, +3 multispectral wavelengths
# - n > 1 if the size of the input image is > [512, 512]
# - metadata
# - GPS coordinates
# - date
pixel_values, metadata = process_image(image_obj)
# Process the image data into n vLLM prompts
model_prompts = pixels_to_prompts(pixel_values)
return model_prompts
def post_process(model_outputs: list[PoolingRequestOutput]):
# Uses the previously extracted metadata to guarantee the output
# contains the same georeferences and date.
return image_object(model_outputs, metadata)
Install the Python Requirements
Install the terratorch (>=1.1rc3) and vllm packages in your Python environment.
At the time of writing this article, the changes required for replicating this example are not yet part of a vLLM release (current latest is v0.10.1.1) and we recommend users install the latest code.
Download and install the IO Processor plugin for flood detection with Prithvi.
git clone git@github.com:christian-pinto/prithvi_io_processor_plugin.git
cd prithvi_io_processor_plugin
pip install .
This installs the prithvi_to_tiff plugin.
Start a vLLM Serving Instance
Start a vLLM serving instance that loads the prithvi_to_tiff plugin and the Prithvi model for flood detection.
vllm serve \
--model=ibm-nasa-geospatial/Prithvi-EO-2.0-300M-TL-Sen1Floods11 \
--model-impl terratorch \
--task embed --trust-remote-code \
--skip-tokenizer-init --enforce-eager \
--io-processor-plugin prithvi_to_tiff
Once the instance is running, it is ready to serve requests with the selected plugin.
The log entries below confirm that your vLLM instance is up and running and that it is listening on port 8000.
INFO: Starting vLLM API server 0 on http://0.0.0.0:8000
...
...
INFO: Started server process [409128]
INFO: Waiting for application startup.
INFO: Application startup complete.
Send Requests to the Model
The Python script below sends a request to the vLLM /pooling endpoint with a specific JSON payload where the model and softmax arguments are pre-defined, while the data field is defined by the user and depends on the plugin in use.
Note
Setting the softmax field to False is required to ensure the plugin receives the raw model output.
In this case, we send the input image to vLLM as a URL, and we request the response to be a GeoTIFF image in base64 encoding. The script decodes the image and writes it to disk as a tiff (GeoTIFF) file.
import base64
import os
import requests
def main():
image_url = "https://huggingface.co/christian-pinto/Prithvi-EO-2.0-300M-TL-VLLM/resolve/main/valencia_example_2024-10-26.tiff"
server_endpoint = "http://localhost:8000/pooling"
request_payload = {
"data": {
"data": image_url,
"data_format": "url",
"image_format": "tiff",
"out_data_format": "b64_json",
},
"model": "ibm-nasa-geospatial/Prithvi-EO-2.0-300M-TL-Sen1Floods11",
"softmax": False,
}
ret = requests.post(server_endpoint, json=request_payload)
if ret.status_code == 200:
response = ret.json()
decoded_image = base64.b64decode(response["data"]["data"])
out_path = os.path.join(os.getcwd(), "online_prediction.tiff")
with open(out_path, "wb") as f:
f.write(decoded_image)
else:
print(f"Response status_code: {ret.status_code}")
print(f"Response reason:{ret.reason}")
if __name__ == "__main__":
main()
Below is an example of the input and the expected output. The input image (left) is a satellite picture of Valencia, Spain during the 2024 flood. The output image (right) shows the areas predicted as flooded (in white) by the Prithvi model.

What’s Next
This is just the beginning. We plan to expand IO Processor plugins across more TerraTorch models and modalities and beyond, making installation seamless. Longer-term, we envision IO Processors powered vision-language systems, structured reasoning agents, and multimodal pipelines, all served from the same vLLM stack. We’re also excited to see how the community uses IO Processors to push the boundaries of what’s possible with vLLM. We also plan to continue working with and contributing to the vLLM community to enable more multimodal models and end-to-end use cases.
Contributions, feedback, and ideas are always welcome!
To get started with IO Processor plugins, check the documentation and explore the examples. More information on IBM’s TerraTorch is available here.
Acknowledgement
We would like to thank the members of the vLLM community for their help with improving our contribution. In particular, we would like to thank Cyrus Leung for his support in helping shape the overall concept of extending vLLM beyond text generation. Finally, we would like to thank the TerraTorch team at IBM, especially Paolo Fraccaro and Joao Lucas de Sousa Almeida, for their help with integrating the generic TerraTorch backend in vLLM.