vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU

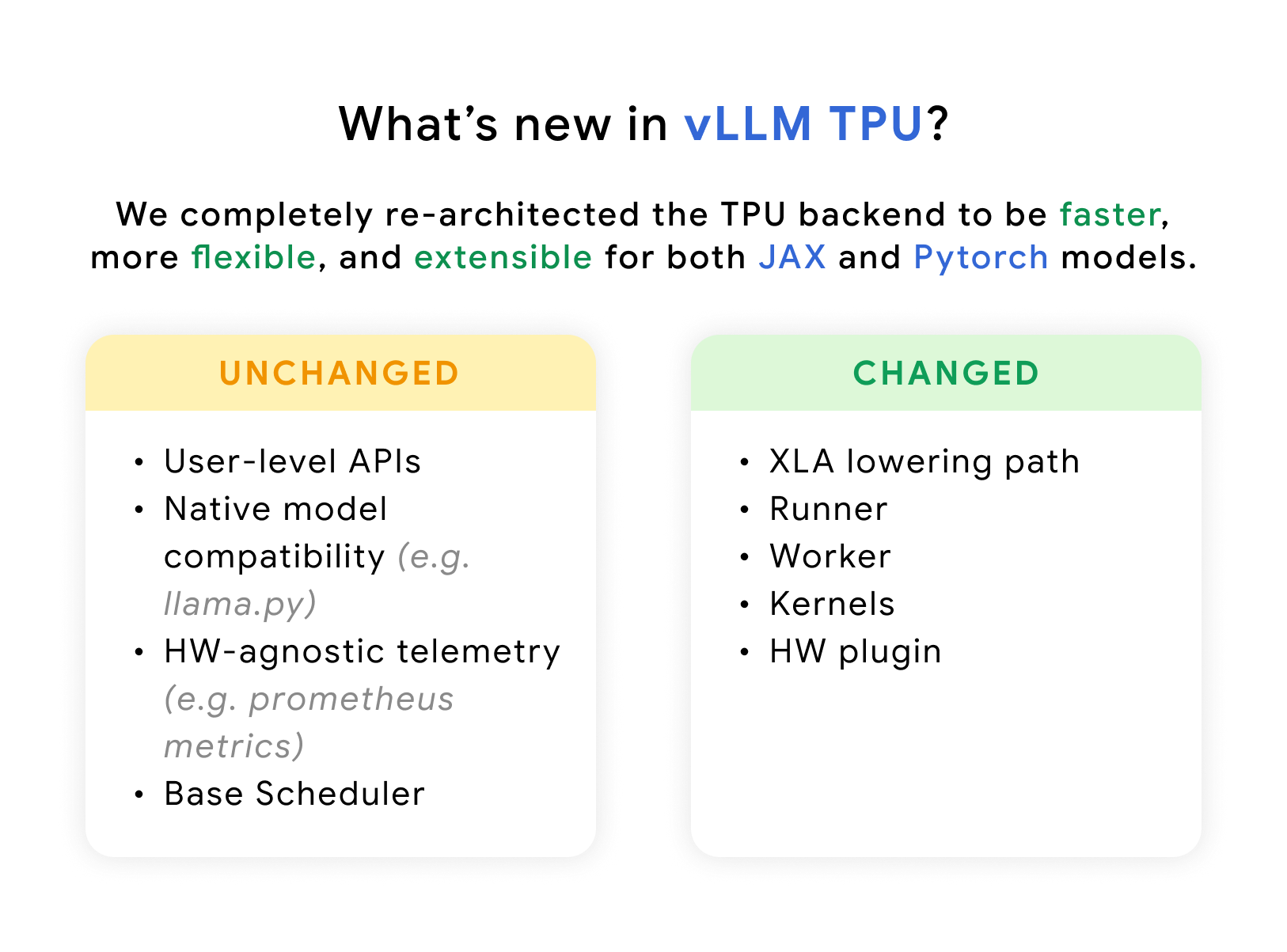
vLLM TPU is now powered by tpu-inference, an expressive and powerful new hardware plugin unifying JAX and PyTorch under a single lowering path. It is not only faster than the previous generation of vLLM TPU, but also offers broader model coverage and feature support. vLLM TPU is a framework for developers to:
- Push the limits of TPU hardware performance in open source.
- Provide more flexibility to JAX and PyTorch users by running PyTorch model definitions performantly on TPU without any additional code changes, while also extending native support to JAX.
- Retain vLLM standardization: keep the same user experience, telemetry, and interface.
vLLM TPU
In February 2025, just when vLLM’s V1 integration was first taking shape, a “small but mighty” team composed of Googlers and core vLLM contributors, set themselves a goal of launching a performant TPU backend across a small number of models in time for Cloud Next 2025. They encountered several challenges over the 2 months that followed, namely:
- vLLM V1 Integration: The team had to integrate into the new V1 code path, requiring a new ragged paged attention kernel (RPA v2). This was mainly done to support features like chunked prefill and prefix caching. Although these KV cache management techniques were common for TPU, designing them in conjunction with vLLM’s paged attention in a “TPU-friendly” manner was challenging.
- Multiple Program, Multiple Data (MPMD): At the time, vLLM exclusively used MPMD to coordinate communication across processes. This is in stark contrast to TPU’s compiler-centric programming model, which heavily relies on Single Program, Multi-Data (SPMD) for overlapping multi-device and multi-host communication.
- PyTorch/XLA (PTXLA): Although the use of the PyTorch/XLA framework made integrating into vLLM easier because of its ability to run PyTorch code natively on TPUs, the team encountered a number of challenges when optimizing at lower levels of the stack.
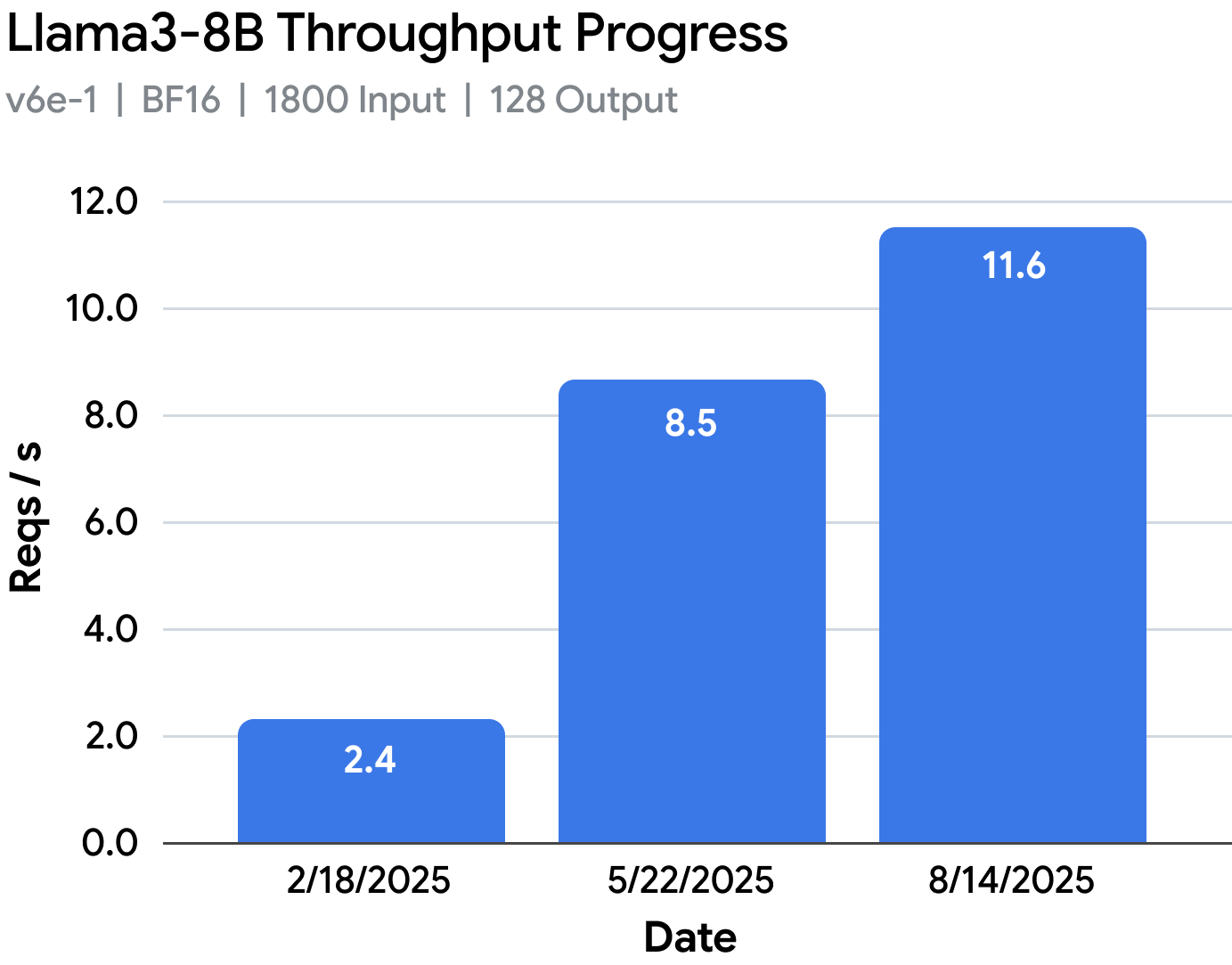
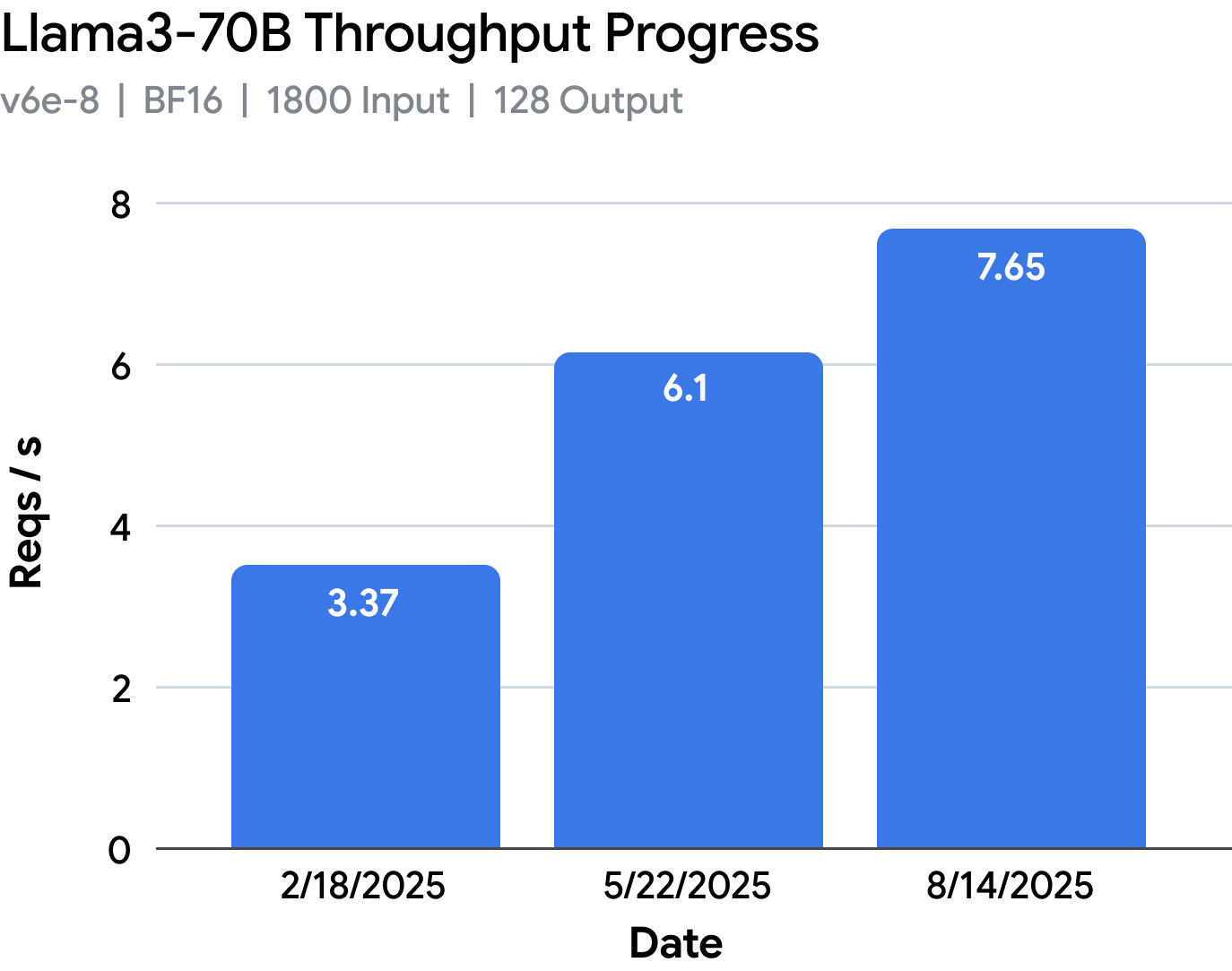
Despite these obstacles, the team improved throughput performance by 3.6x for Llama 3.1-8B on v6e-1 and 2.1x for Llama 3.1-70B in v6e-8. vLLM TPU also made it to the big stage at Cloud Next. You can check out the performance evolution of these workloads here.
vLLM TPU Powered by TPU-inference
Although vLLM TPU with PTXLA was a major accomplishment, we needed to continue to push the limits of TPU performance in open source. We also wanted to bring together TPU and vLLM ecosystems by supporting both PyTorch and JAX models natively on TPU in the most performant way possible.
A Unified Backend for PyTorch and JAX
This new vLLM TPU redesign with tpu-inference aims to optimize performance and extensibility by supporting PyTorch (via Torchax) and JAX within a single unified JAX→XLA lowering path.
Compared to PyTorch/XLA, JAX is a more mature stack, generally offering superior coverage and performance for its primitives, particularly when implementing complex parallelism strategies.
For this reason, vLLM TPU now uses JAX as the lowering path for all vLLM models, benefiting from significant performance improvements, even when the model definition is written in PyTorch. This decision allows us to move faster and smarter, abstracting away higher level frameworks to focus on kernel development and compiler optimizations. Remember, to XLA, Torchax and JAX use the same high performance primitives ahead of compilation. You can read more about it here.
Although this is our current design, we will always strive to achieve the best performance possible on TPU and plan to evaluate a native PyTorch port on TPU in the future for vLLM TPU.
Important
Takeaway #1: vLLM TPU now lowers all models with JAX. Without making any changes to the model code (e.g. llama.py), vLLM TPU now achieves ~20% higher throughput performance, simply because it now leverages JAX’s mature, high-performance primitives to generate the HLO graph that is then compiled by XLA.
A Closer Look
-
Installation
pip install vllm-tpu # a single install pathBecause Torchax and JAX are essentially just JAX under the hood, we can leverage the same install path regardless of whether the model code was written in PyTorch or JAX. This ensures dependencies remain consistent and users don’t have to worry about managing different requirements for different models.
-
Serving a Model
MODEL_ID="google/gemma3-27b-it" # model registered in tpu-inference or vllm vllm serve $MODEL_IDWhen serving a model on TPU, there are 2 model registries to pull model code from:
1) tpu-inference (default, list)
2) vllm (maintained in vLLM upstream, list)
Let’s take a closer look at what’s happening under the hood:
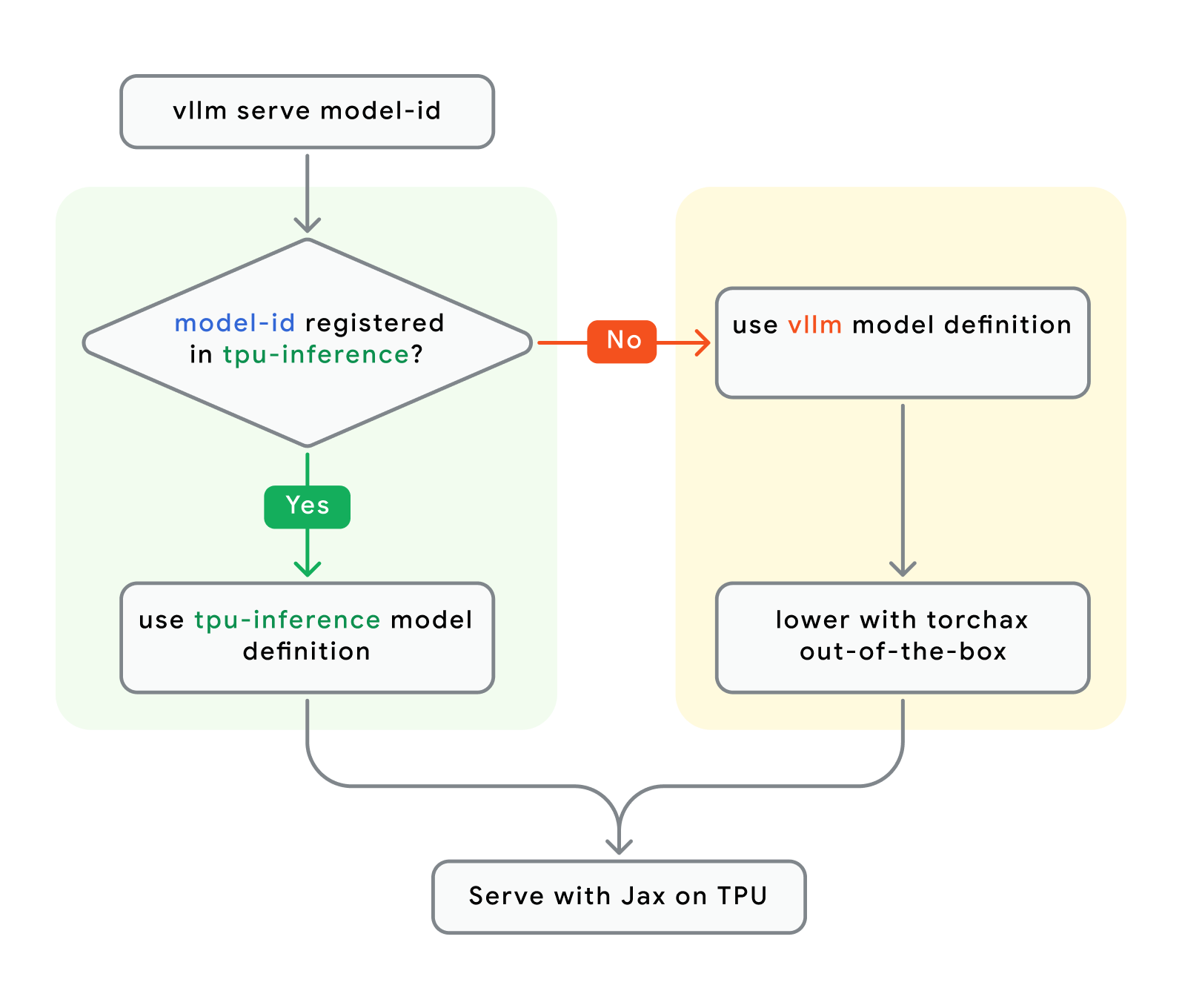
This unification effort reduces duplication by leveraging existing work from the vLLM community, leaving more time to optimize TPU kernels and the XLA compiler. For PyTorch (via Torchax) and JAX models, all kernels and compilers are shared.
Important
Takeaway #2: vLLM TPU will now default to running the TPU-optimized model code in tpu-inference if it exists, otherwise, it will fallback to the PyTorch model code from vLLM upstream (lowered using JAX via Torchax). For most users, this is an implementation detail.
If Torchax can run PyTorch model code out-of-the-box on TPU but still compiles using JAX JIT, why did we rewrite some models in tpu-inference? Isn’t that duplicative?
We provide a few reference models for developers to reduce the ramp-up curve before they can begin optimizing their models for TPU (see here). Interestingly, we observed that torchax-lowered and naive-reimplemented JAX models had roughly the same performance, demonstrating how efficient torchax is at converting high level models.
The real performance benefit and the reason why we support reimplemented models comes from optimizing the JAX code for TPU and leveraging the strengths of the TPU architecture directly.
The reason we need this flexibility is because logical design choices of a vLLM developer when implementing a model do not always favor TPU. This makes them different, not because of JAX vs Torchax, but because GPUs are different from TPUs, requiring different strategies for optimizing.
Important
Takeaway #3: For any model, it’s all JAX under the hood! Unless logical differences in the implementation cause TPU performance to suffer, models will likely not benefit from being rewritten natively in JAX. That said, it’s important to retain the flexibility of reimplementing models if it means we can get the best out of TPUs.
Ragged Paged Attention V3: The Most Flexible and High Performance Attention Kernel for TPU Inference in OSS
Although the Ragged Paged Attention v2 kernel provided a major uptick in performance, in order to support more models and use cases OOTB, it needed to become much more flexible.
- RPA v2 could only support model specs with a head dim of 128.
- More Models: RPA v3 is much more flexible, supporting arbitrary model specs, quantization dtypes, and arbitrary tensor-parallelism (TP), unlocking more models out-of-the-box.
- RPA v2 suffered from pipeline inefficiency due to performing the KV cache update and attention op sequentially.
- Better Performance: RPA v3 improves pipeline efficiency by fusing the kv cache update (scatter) to the RPA kernel. This design now completely hides scatter latency during kernel execution.
- RPA v2 could incur significant waste during decode-heavy or varied length prefill tasks.
- Improved Deployment Flexibility: RPA v3 will compile to 3 sub-kernels, unlocking support for prefill-only, decode-only, and mixed batch processing. This design significantly saves on direct-memory-access (DMA) and compute by pairing the correct sub-kernel to the appropriate request at runtime.
- This also has the added benefit of unlocking more complex deployment patterns, like disaggregated serving.
- Although RPA v2 achieved significant throughput improvements over the first TPU prototype, it lacked flexibility.
- No Compromises: RPA v3 does not sacrifice performance for flexibility, in fact, it increases throughput by ~10% over RPA v2 on Trillium (v6e). Models can now also run on v5p (although additional tuning is needed).
We will be writing a technical deep dive on RPA v3 soon, so please look out for it in our docs.
Important
Takeaway #4: RPA v3 is both flexible and performant and serves as an excellent reference for production-grade Pallas kernel development in OSS. We are excited for TPU-friendly MoE and MLA kernels to land in OSS in similar fashion soon.
Single Program, Multi-Data (SPMD)
This release introduces Single Program, Multi-Data (SPMD) as the default programming model for vLLM TPU. Unlike the previous multi-worker model (adapted from GPU paradigms), SPMD is native to the XLA compiler. Developers write code for a single, massive device, and the XLA compiler automatically partitions models and tensors, inserting communication operations for optimal execution.
Important
Takeaway #5: SPMD enables advanced optimizations like overlapping communication with computation. SPMD represents a strategic shift towards deeper, native TPU integration, promising higher performance through a TPU-centric, compiler-first operating model.
Bringing it All Together
|
|
vLLM TPU has come a very long way from the prototype performance in February 2025, reaching nearly 2x-5x performance on those same workloads, while also improving model coverage and usability.
Important
Takeaway #6: Today, vLLM TPU is nearly 5x more performant than the first TPU prototype back in Feb 2025. With this new foundation in place, developers and researchers will now be able to push the boundaries of TPU inference performance further than ever before in open source.
Models, Features, and What’s Next
We can view this release as foundational, as vLLM TPU will now be cutting releases on a regular basis in OSS. With every new release, CI/CD will publish documented tables of vetted vLLM-native models. We will also maintain a list of stress tested tpu-inference models primarily as a reference for JAX users. All features will also undergo rigorous testing ahead of releases.
Supported Model Families
- Dense
- Multimodal (tpu-inference models only)
Note
Note on Model Support: Until we land more capabilities, we recommend starting from the list of stress tested models here. We are still landing components in tpu-inference that will improve performance for larger scale, higher complexity models (XL MoE, +vision encoders, MLA, etc.). If you’d like us to prioritize something specific, please submit a GitHub feature request here.
Supported/Verified TPU generations
- Trillium (v6e), v5e
Features
- Prefix caching
- Chunked Prefill
- Multimodal Inputs
- Single Program Multi Data (SPMD)
- Structured Decoding
- Speculative decoding: Ngram
- Out-of-tree model support
- Optimized Runtime Sampling (top k, top p, temperature, logit output)
- Quantization (weights, activations, and KV cache)
TPU-Friendly Kernels
- Ragged Paged Attention V3
- Collective Communication Matmul
- Quantized Matmul, Attention and KV Cache
Experimental
- v5p
- Multimodal (through Torchax)
- Multi-lora
- Speculative decoding: tree-based Eagle 3
- Single-host P/D disaggregated serving
What’s Next?
- Sparsecore offloading
- Speculative decoding: Eagle 3, MTP
- TPU-friendly Kernels:
- XL MoE
- MLA
- Integrations
- RL:
- Single-host and Multi-host
- Colocated and disaggregated set up
- Single-controller via Pathways
- Multi-sampling via prefix caching
- Weight sync and resharding
- Throughput-optimized rollout via Data Parallelism
- LoRA
- Support for tool calls, multi-turn rollout
- Check out our partner projects: Tunix, MaxText, SkyRL
- Distributed
- Multihost dynamic P/D disaggregated serving
- Prefix Cache offloading to CPU and remote stores
- Optimized Data Parallel Attention load balancing
- Check out our partner project: llm-d
- RL:
- Contributions welcome!
Try it out!
You can try it out on Google Cloud, including Google Kubernetes Engine (GKE), Compute Engine, and Vertex AI. For installation instructions and developer guides, check out the following resources:
- Contribution Guide
- Quick Start Guide
- vLLM TPU: Trillium (v6e) Recipes
- Developer Guide: JAX
- Developer Guide: Torchax
Google Cloud Tutorials: GKE: here, Vertex AI: here
Acknowledgment
We would like to extend our sincerest gratitude to the vLLM community for their ongoing support in this work. Special thanks to Woosuk Kwon for spearheading TPU’s V0 implementation and continuing to support our growing team. We’d also like to give a big shoutout to Simon Mo, Robert Shaw, Michael Goin, Yanping Huang for their invaluable guidance throughout this work. Special thanks as well to Nicolo Lucchesi, Alexander Matveev, Akshat Tripathi, and Saheli Bhattacharjee, for being an integral part of the V1 integration and the push for Cloud Next.