Now Serving NVIDIA Nemotron with vLLM
Agentic AI systems, capable of reasoning, planning, and taking autonomous actions, are powering the next leap in developer applications. To build these systems, developers need tools that are open, efficient, and ready to scale. And, as demand for agents grows, open, performant models are the key as they provide transparency, adaptability, and cost-control.
NVIDIA Nemotron is a family of open models, datasets, and technologies that unlock developers to build highly efficient and accurate models for specialized agentic AI.
vLLM Now Supports NVIDIA Nemotron
vLLM provides a seamless path to deploying the open family of NVIDIA Nemotron, letting developers spin up agentic, high-accuracy inference on both data center and edge hardware—optimized for throughput and accuracy. Nemotron models are ready to serve out-of-the-box with vLLM, using open weights and open data for reproducible, production-grade agents.
NVIDIA Nemotron Nano 2
The latest addition to this family is the NVIDIA Nemotron Nano 2, a highly efficient small language reasoning model with a hybrid Transformer–Mamba architecture and a configurable thinking budget. This allows developers to dial accuracy, throughput, and cost to match their real‑world application needs.
-
Open: Available on Hugging Face, this model provides leading accuracy for reasoning, coding, and various agentic tasks including instruction following, tool calling, and long context chat. Over 9T tokens of pre- and post-training data, generated and curated by NVIDIA and available with a very permissible license, is also released on Hugging Face.
-
Efficient: Nemotron Nano 2, thanks to the hybrid architecture, produces critical thinking tokens up to 6 times faster compared to the next best open dense model of a similar size using vLLM. Higher throughput allows the model to think faster, explore larger search space, do better self reflection, and deliver higher accuracy.
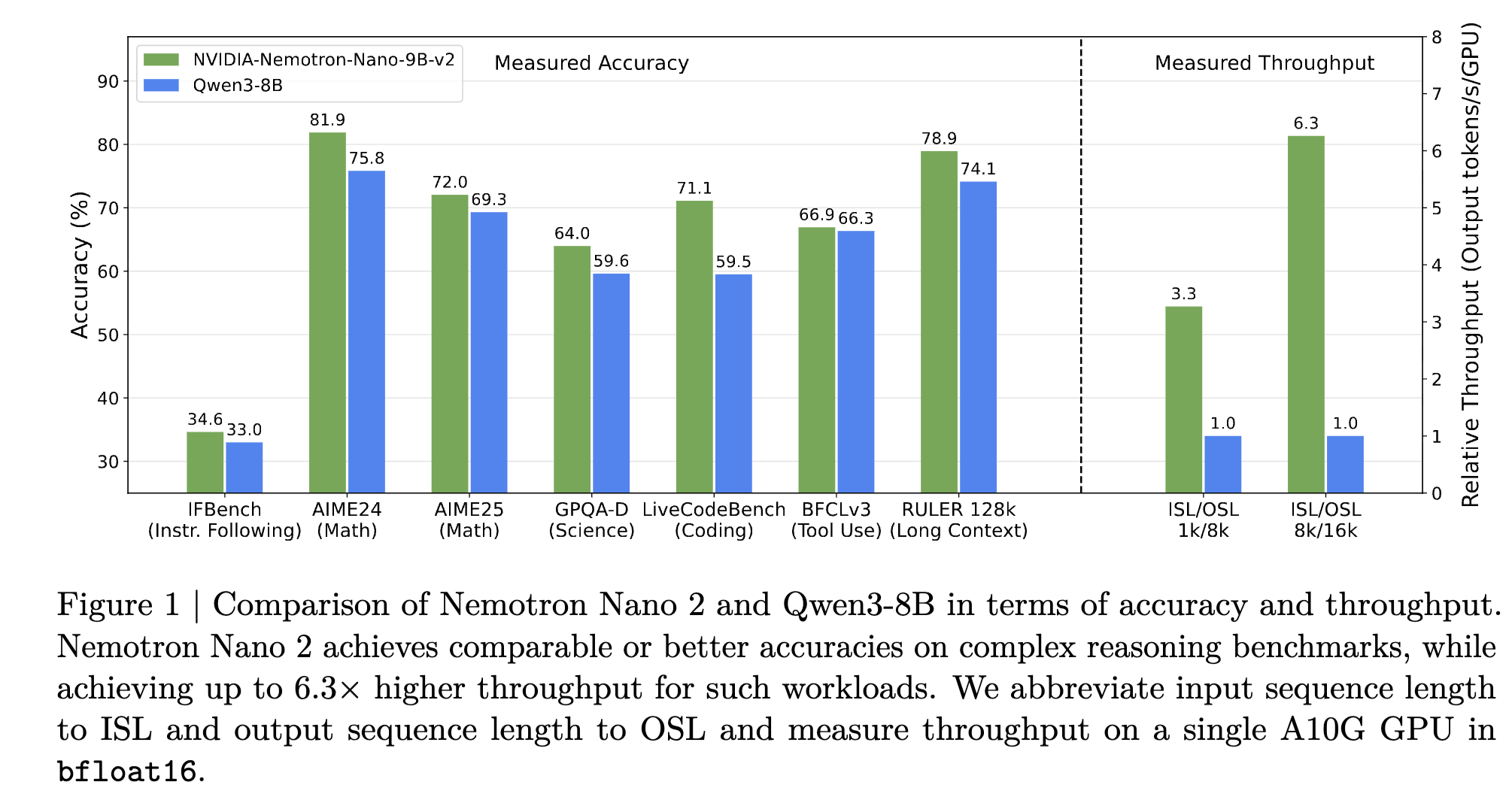
Figure 1: Chart showing accuracy of Nemotron Nano 2 9B on various popular benchmarks
- Optimized Thinking: The model has a new feature called thinking budget which avoids agent overthinking and optimizes for predictable inference cost. The chart below shows that if left alone, models can overthink, increasing inference cost, and in certain cases also reduce accuracy. Thinking budget addresses this challenge by enabling developers to tune the model to achieve the most optimal accuracy-token generation sweetspot for their applications.
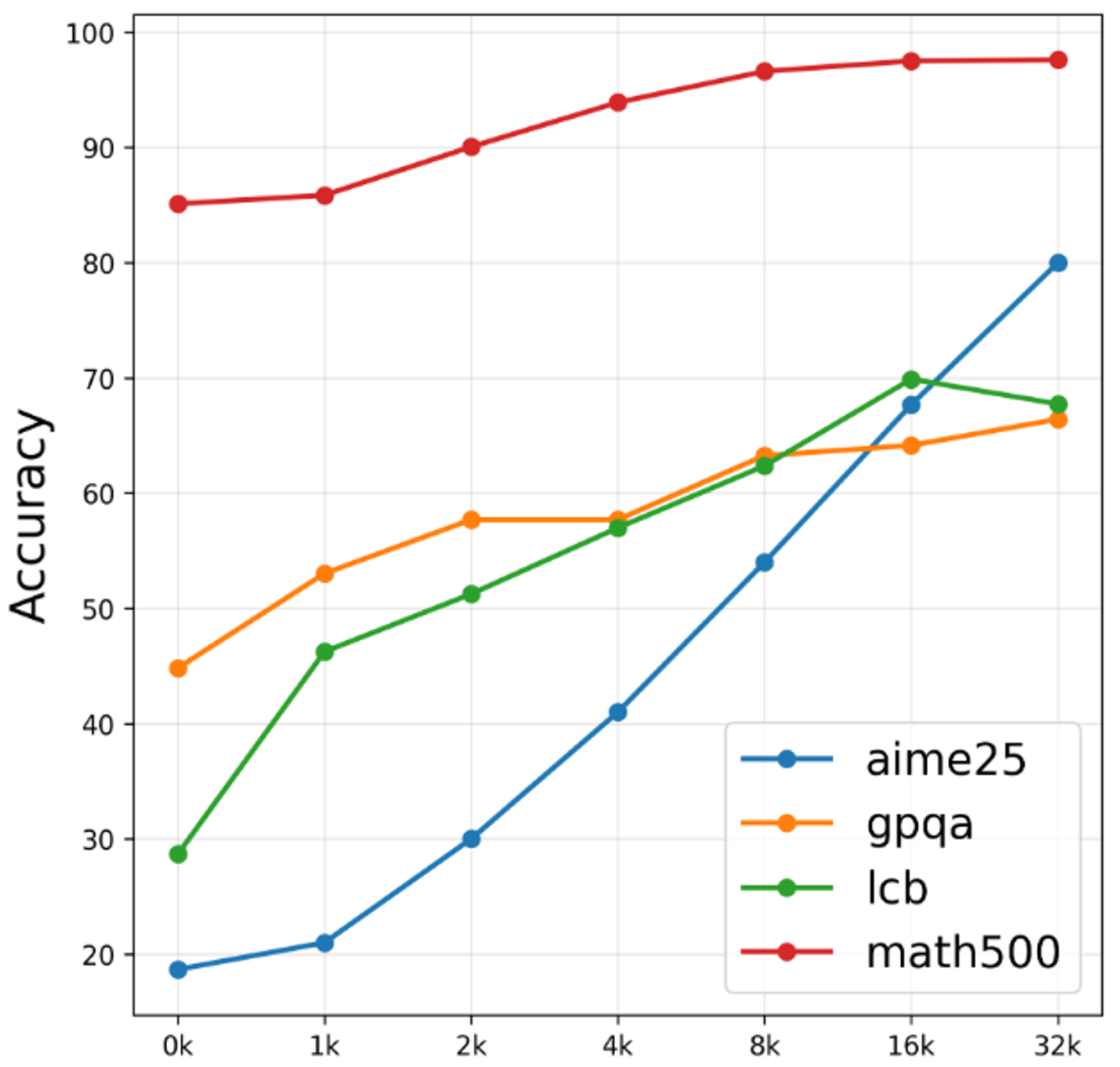
Figure 2: Chart showing the accuracy of Nemotron Nano 2 9B model on popular benchmarks at various “Token Budget” thresholds
Get started w/ Nemotron using vLLM
Let’s deploy the Nemotron Nano 2 model for agentic inference using vLLM:
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32
Now we can create a ThinkingBudgetClient to consume our newly created endpoint. This will help enforce and parse the thinking budget feature described above. With vLLM, this process is very straightforward - let’s dive in!
from typing import Any, Dict, List
import openai
from transformers import AutoTokenizer
class ThinkingBudgetClient:
def __init__(self, base_url: str, api_key: str, tokenizer_name_or_path: str):
self.base_url = base_url
self.api_key = api_key
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path)
self.client = openai.OpenAI(base_url=self.base_url, api_key=self.api_key)
def chat_completion(
self,
model: str,
messages: List[Dict[str, Any]],
max_thinking_budget: int = 512,
max_tokens: int = 1024,
**kwargs,
) -> Dict[str, Any]:
assert (
max_tokens > max_thinking_budget
), f"thinking budget must be smaller than maximum new tokens. Given {max_tokens=} and {max_thinking_budget=}"
# 1. first call chat completion to get reasoning content
response = self.client.chat.completions.create(
model=model, messages=messages, max_tokens=max_thinking_budget, **kwargs
)
content = response.choices[0].message.content
reasoning_content = content
if not "</think>" in reasoning_content:
# reasoning content is too long, closed with a period (.)
reasoning_content = f"{reasoning_content}.n</think>nn"
reasoning_tokens_len = len(
self.tokenizer.encode(reasoning_content, add_special_tokens=False)
)
remaining_tokens = max_tokens - reasoning_tokens_len
assert (
remaining_tokens > 0
), f"remaining tokens must be positive. Given {remaining_tokens=}. Increase the max_tokens or lower the max_thinking_budget."
# 2. append reasoning content to messages and call completion
messages.append({"role": "assistant", "content": reasoning_content})
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
continue_final_message=True,
)
response = self.client.completions.create(
model=model, prompt=prompt, max_tokens=remaining_tokens, **kwargs
)
response_data = {
"reasoning_content": reasoning_content.strip().strip("</think>").strip(),
"content": response.choices[0].text,
"finish_reason": response.choices[0].finish_reason,
}
return response_data
Now that we’ve set up our ThinkingBudgetClient we can fire-off a request and look at the response!
tokenizer_name_or_path = "nvidia/NVIDIA-Nemotron-Nano-9B-v2"
client = ThinkingBudgetClient(
base_url="http://localhost:8000/v1", # Nano 9B v2 deployed in thinking mode
api_key="EMPTY",
tokenizer_name_or_path=tokenizer_name_or_path,
)
result = client.chat_completion(
model="nvidia/NVIDIA-Nemotron-Nano-9B-v2",
messages=[
{"role": "system", "content": "You are a helpful assistant. /think"},
{"role": "user", "content": "What is 2+2?"},
],
max_thinking_budget=32,
max_tokens=512,
temperature=0.6,
top_p=0.95,
)
print(result)
We see the response as:
{'reasoning_content': 'Okay, the user asked "What is 2+2?" Let me think. This is a basic arithmetic question. The answer should be straightforward. I need.', 'content': '2 + 2 equals **4**. nnLet me know if you need help with anything else! 😊n', 'finish_reason': 'stop'}
vLLM as a tool helps improve Nemotron Nano 2 deployment by making it faster, more memory-efficient, and easier to scale for real-time agentic use-cases. Additionally, vLLM’s focus on efficient KV-cache management, and long context use-cases works well with the hybrid transformer-Mamba architecture of Nemotron Nano 2.
If you’d like to learn more about how to leverage the Nemotron Nano 2, you can check out the model card. And if you’re looking to get started with vLLM, check out the Quickstart Documentation.
Run Anywhere
Nemotron models are configured to run across all GPU-accelerated systems so you can seamlessly transition from development to production.
Try the model on the NVIDIA-hosted endpoint at build.nvidia.com or download from Hugging Face.
Share your ideas and vote on what matters to help shape the future of Nemotron.
Stay up to date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, YouTube, and the Nemotron channel on Discord.