From Monolithic to Modular: Scaling Semantic Routing with Extensible LoRA
Semantic routing systems face a scaling challenge. When each classification request requires running multiple fine-tuned models independently, the computational cost grows linearly with the number of models. This post examines how a recent refactoring of the vLLM Semantic Router’s Rust-based classification layer addresses this problem through architectural modularity, Low-Rank Adaptation (LoRA), and concurrency optimization.
Background: From BERT to a Modular System
The previous implementation relied primarily on BERT and ModernBERT for intent and jailbreak classification. While ModernBERT performs well for English text classification tasks, it has the following limitations:
- Language Coverage: The original ModernBERT’s multilingual support is limited compared to models trained on more diverse datasets. (Note: mmBERT, a massively multilingual variant of ModernBERT supporting 1800+ languages, was released after this refactoring began and represents an alternative approach to the multilingual challenge)
- Context Length: While ModernBERT extends context to 8,192 tokens using RoPE (source), models like Qwen3-Embedding support up to 32,768 tokens, which is beneficial for very long document processing
- Model Coupling: Classification logic was tightly coupled to specific model architectures, making it difficult to add new models
These constraints motivated a broader refactoring that would enable the system to support multiple model types while maintaining performance. The modular architecture means that newer models like mmBERT can be integrated alongside Qwen3-Embedding and EmbeddingGemma, allowing the router to select the most appropriate model for each task.
Architectural Restructuring
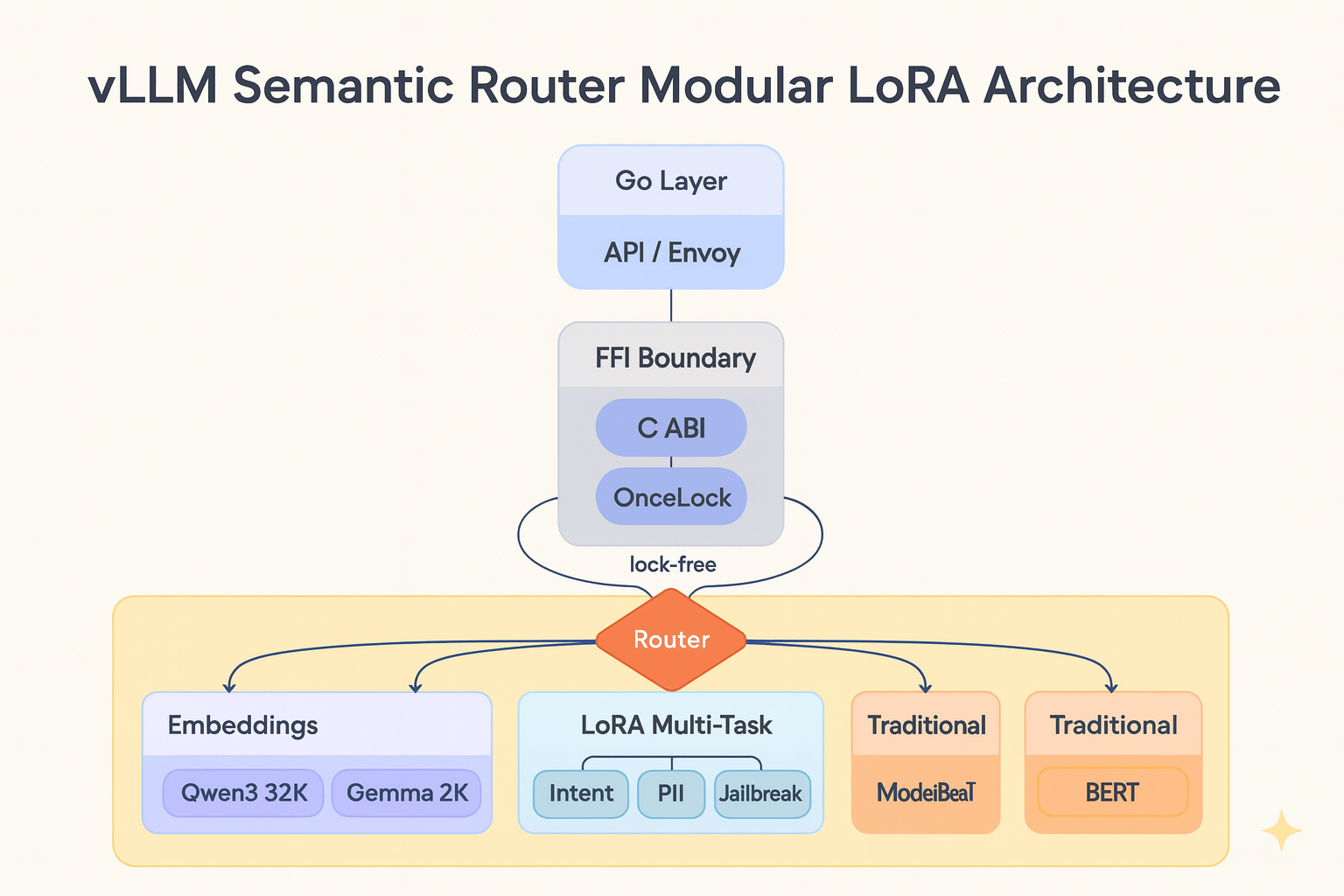
The refactoring introduces a layered architecture in the candle-binding crate. This structure separates concerns: core functionality remains independent of specific models, while new model architectures can be added without modifying existing code. The DualPathUnifiedClassifier implements routing logic that selects between traditional fine-tuned models and LoRA-adapted models based on the task requirements.
Long-Context Embedding Models
Two new embedding models address the context length limitation:
Qwen3-Embedding
Qwen3-Embedding supports context lengths up to 32,768 tokens (Hugging Face model card). The implementation uses a RoPE (Rotary Position Embedding), enabling this extended context handling through improved frequency resolution at longer distances.
Qwen3-Embedding was trained on text from over 100 languages (Hugging Face model card), making it suitable for multilingual routing scenarios where the previous ModernBERT-only approach would struggle.
EmbeddingGemma-300M
Google’s EmbeddingGemma-300M takes a different approach, focusing on smaller model size while maintaining quality. The model supports context lengths of 2,048 tokens and implements Matryoshka representation learning, which means embeddings can be truncated to 768, 512, 256, or 128 dimensions without retraining (Hugging Face model card).
The architecture uses Multi-Query Attention (MQA) with 3 query heads and 1 key-value head, reducing memory bandwidth requirements. A distinctive feature is the dense bottleneck layer (768 → 3072 → 768) applied after the transformer blocks, which improves embedding quality based on the Matryoshka training approach.
Low-Rank Adaptation for Multi-Task Classification
LoRA addresses a fundamental inefficiency in the previous system. When a classification system needs to determine intent, detect PII, and check for security issues, the naive approach runs three separate fine-tuned models:
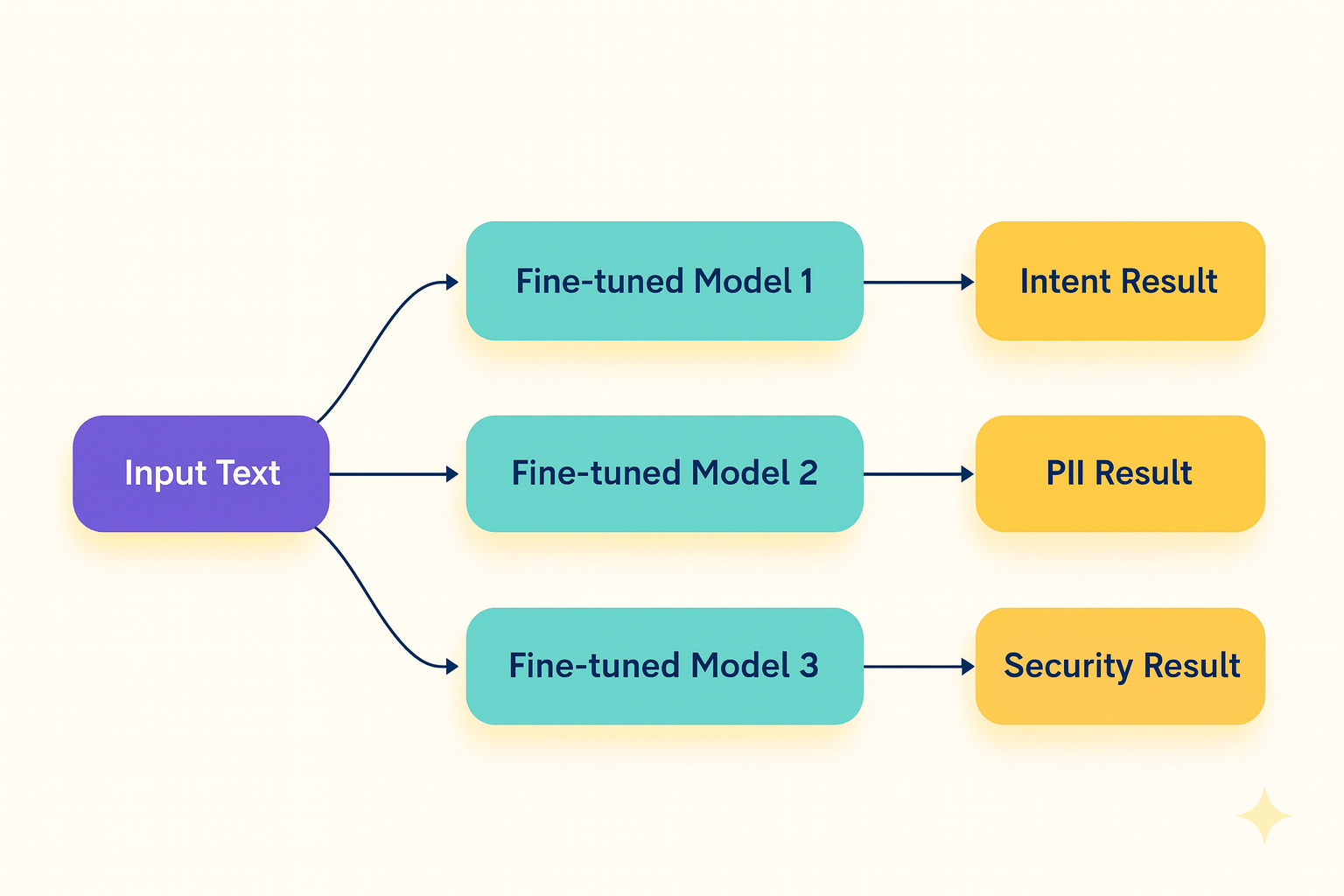
Each model processes the input through its entire network, including the expensive base transformer layers. This results in O(n) complexity where n is the number of classification tasks.
LoRA changes this by sharing the base model computation:
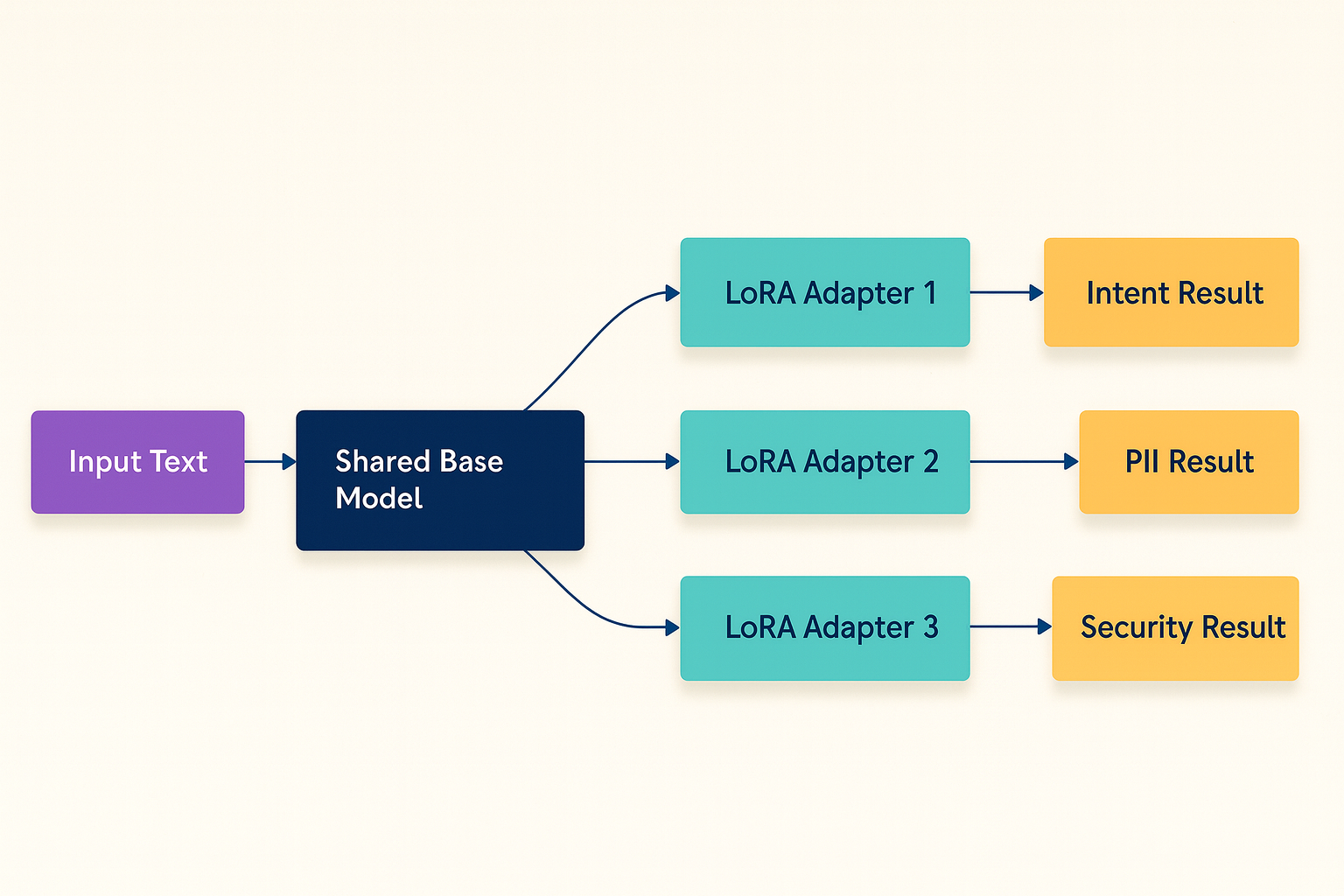
The base model runs once, producing intermediate representations. Each LoRA adapter then applies task-specific low-rank weight updates to specialize the output. Since LoRA adapters typically modify less than 1% of the model’s parameters, this final step is much faster than running complete models.
The implementation in parallel_engine.rs uses Rayon for data parallelism, processing multiple LoRA adapters concurrently. For a request requiring three classifications, this changes the workload from three full forward passes to one full pass plus three lightweight adapter applications.
Concurrency Through OnceLock
The previous implementation used lazy_static for managing global classifier state, which introduced lock contention under concurrent load. The refactoring replaces this with OnceLock from the Rust standard library.
OnceLock provides lock-free reads after initialization. After the first initialization, all subsequent accesses are simple pointer reads with no synchronization overhead. Tests in oncelock_concurrent_test.rs verify this with 10 concurrent threads performing 30 total classifications, confirming that throughput scales linearly with thread count.
This matters when the router processes multiple incoming requests. With lazy_static, concurrent requests would queue behind a mutex. With OnceLock, they execute in parallel without contention.
Flash Attention for GPU Acceleration
Flash Attention 2 support is available as an optional feature for CUDA builds, though it requires Ampere-generation or newer GPUs (compute capability ≥ 8.0). Flash Attention optimizes the attention mechanism by processing computations in blocks that fit in fast on-chip SRAM memory, avoiding repeated reads from slower GPU DRAM.
Both ModernBERT and Qwen3 benefit from Flash Attention integration:
-
ModernBERT: Achieves up to 3× faster self-attention computations with significantly reduced memory usage (source). The model also uses alternating attention patterns (global attention every third layer, local sliding-window attention otherwise) to balance efficiency with context retention (source).
-
Qwen3: Integration of FlashAttention-2 provides up to 4× speedup in attention operations. For the 14B variant, this translates to 70-110 tokens/second during inference compared to 30-35 tokens/second without it—a performance improvement that becomes more pronounced with longer contexts (source).
The Rust implementation makes Flash Attention optional via Cargo features, allowing deployment on systems without compatible GPUs while enabling substantial performance gains when hardware supports it.
Cross-Language Integration for Cloud-Native Ecosystems
The choice of Rust for the core classification engine combined with Go FFI (Foreign Function Interface) bindings addresses a practical deployment challenge in cloud-native environments.
Why Rust for ML Inference
Rust provides several advantages for the classification layer:
- Performance: Near-C performance with zero-cost abstractions, critical for low-latency inference
- Memory Safety: Compile-time guarantees prevent common bugs like buffer overflows and use-after-free errors
- Concurrency: The ownership system prevents data races, enabling safe parallel processing with Rayon
- No Garbage Collection: Predictable latency without GC pauses that affect request processing
The Candle framework leverages these Rust strengths while providing a familiar API for ML model development.
Why Go FFI Bindings Matter
While Rust excels at compute-intensive ML inference, Go dominates the cloud-native infrastructure ecosystem. The FFI layer bridges these worlds. This integration enables deployment in environments where Go is the primary language:
- Envoy Proxy Integration: The semantic router runs as an Envoy external processing filter, written in Go. The FFI allows the Go filter to leverage high-performance Rust classification without rewriting the entire Envoy integration layer.
- Kubernetes Operators: Cloud-native operators are typically written in Go using controller-runtime. The FFI enables these operators to embed classification logic directly rather than making network calls to separate services.
- Service Meshes: Projects like Istio, Linkerd, and Consul are Go-based. The FFI allows routing decisions to use ML-based classification while maintaining compatibility with existing mesh control planes.
- API Gateways: Many API gateways (Kong, Tyk) have Go components. The FFI enables semantic routing at the gateway layer without introducing additional microservices.
Deployment Flexibility
The dual-language architecture provides deployment options:
- Embedded Mode: The Go service links directly to the Rust library via CGO, minimizing latency and deployment complexity
- Process Isolation: The classification layer can run as a separate process, communicating via gRPC or Unix sockets for additional fault isolation
- Mixed Workloads: Services can combine Go’s networking and orchestration strengths with Rust’s ML inference performance
The semantic router leverages this pattern extensively. The main routing logic, configuration management, and cache implementations are in Go, while the compute-intensive classification runs in Rust. This separation allows each component to use the most appropriate language while maintaining clean interfaces through the FFI layer.
Performance Characteristics
The benefits of this architecture vary by workload:
- Single vs multi-task classification: LoRA provides minimal benefit since there’s no base model sharing. Traditional fine-tuned models may be faster. LoRA shows clear advantages when performing multiple classifications on the same input. Since the base model runs once and only LoRA adapters execute for each task, the overhead is substantially reduced compared to running separate full models. The actual speedup depends on the ratio of base model computation to adapter computation.
- Long-context inputs: Qwen3-Embedding enables routing decisions on documents up to 32K tokens without truncation, extending beyond ModernBERT’s 8K limit for very long documents. With Flash Attention 2 enabled on compatible GPUs, the performance advantage becomes more substantial as context length increases.
- Multilingual routing: Models can now handle routing decisions for languages where ModernBERT has limited training data.
- High concurrency:
OnceLockeliminates lock contention, allowing throughput to scale with CPU cores for classification operations. - GPU acceleration: When Flash Attention 2 is enabled, attention operations run 3-4× faster, with the speedup becoming more pronounced at longer sequence lengths. This makes GPU deployment particularly advantageous for high-throughput scenarios.
Future Directions
The modular architecture enables several extensions:
- Additional embedding models can be added by implementing the
CoreModeltrait - Flash Attention 3 support when available in Candle
- Quantization support (4-bit, 8-bit) for reduced memory footprint
- Custom LoRA adapters for domain-specific routing
- FFI bindings for additional languages (Python, Java, C++) to expand integration possibilities
The system now has a foundation for incorporating new research advances without requiring architectural changes. The FFI layer provides a stable interface that allows the Rust implementation to evolve independently while maintaining compatibility with existing Go-based deployments.