Shared Memory IPC Caching: Accelerating Data Transfer in LLM Inference Systems
Note
Originally posted on the Cohere blog.
Introducing Shared Memory IPC Caching — a high-performance caching mechanism contributed by Cohere to the vLLM project. By bypassing redundant inter-process communication and keeping large multimodal inputs in shared memory, it dramatically reduces data-transfer overhead, unlocking faster, more efficient LLM inference at scale.
Modern LLM inference often involves multiple processes working together, communicating through inter-process communication. As parallelism scales and inputs become richer (think multimodal data), IPC overhead can quickly turn into a major performance bottleneck.
With Shared Memory IPC Caching, we can significantly reduce redundant data transfers between processes on a single node. Our benchmarks show:
- First-time requests: Prefill throughput improved by 11.5%, and TTFT decreased by 10.5%
- Cached requests (where both KV and image inputs are reused): Prefill throughput increased by 69.9%, and TTFT dropped by 40.5% These gains come primarily from eliminating redundant IPC transfers between processes.
Moreover, the benefits scale with input size and tensor parallel (TP) size: larger inputs and wider TP configurations involve heavier IPC traffic, making shared memory caching even more impactful for large multimodal workloads.
Inter-process communication in LLM inference
In a typical multi-process LLM inference stack, there are three main components: the front-end, which handles and preprocesses user requests; the coordinator, which manages scheduling and orchestration; and the inference worker, which runs the model computation.
The diagram below shows how processes coordinate in an LLM inference system with four GPUs. The front-end sends input data to the coordinator, which then routes it to four workers, one per GPU, to perform inference.
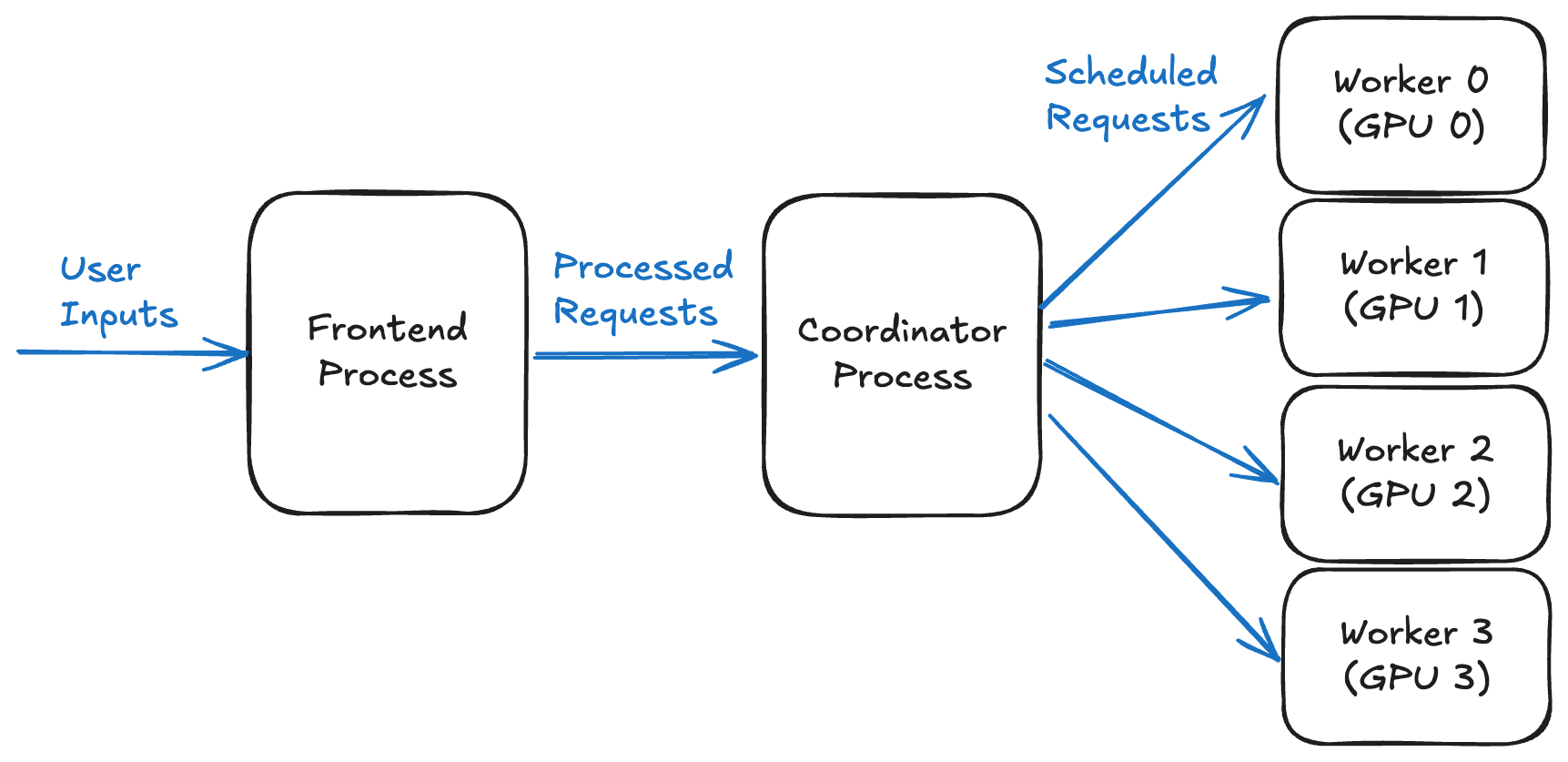
Figure 1. Overview of process coordination in an LLM inference system using four GPUs
Each stage usually runs in a separate process to enable scalability and asynchronous execution. As a result, data must flow between these processes via IPC. For small inputs, this overhead is negligible, but as inputs grow, IPC time can become a major bottleneck.
The problem: Repeated large data transfers
Multimodal inputs, like images, audio, or long context sequences, can be huge. For example, in the CohereLabs/command-a-vision-07-2025 model, a single max-size input image of 1024×3072 pixels is around 9 MB when represented as an int8 array. The model can also accept multiple images as input, so the total size per request can easily reach tens of megabytes.
Transferring such large inputs between processes via IPC isn’t free. In multi-turn conversations or batch processing, the same inputs may be transmitted multiple times, further compounding the overhead.
The existing solution: Mirrored caching
vLLM already uses mirrored caching to reduce redundant IPC transfers. In this approach, both the sender and receiver maintain replicated caches that follow the same insertion order and eviction policy. When the sender detects a cache hit for a particular input, it assumes that the receiver’s cache is in the same state and skips the IPC transfer.
However, this approach has a key limitation: it relies on strict input ordering, where the sender and receiver must process inputs in the exact same sequence. In a typical front-end–coordinator–worker setup, for example, if mirrored caches are placed on the workers, the coordinator may reorder inputs based on its scheduling policy, causing the caches to fall out of sync and potentially leading to incorrect behavior.
As a result, in vLLM, mirrored caching is applied only to front-end–coordinator communication. For the coordinator–worker path, when there is only a single worker, vLLM places it in the same process as the coordinator, eliminating the need for extra IPC. When multiple workers are involved, however, vLLM falls back to socket-based IPC, which incurs additional overhead from serialization, transmission, and deserialization.
A new approach: Shared Memory IPC Caching
To overcome the limitations of traditional IPC caching, we are introducing Shared Memory IPC Caching. A single shared cache is now directly accessible by the sender and receivers, eliminating ordering assumptions and redundant data copies.
Shared Memory Object Store
We implemented a Shared Memory Object Store data structure to enable this caching, allowing one writer instance and multiple reader instances to efficiently share the same memory buffer.
Design
- Writer: Inserts the input object into a shared ring buffer, updates an address index, and broadcasts the address to all interested readers
- Reader: Uses the provided address to access objects directly from shared memory
The diagram below shows IPC caching using a Shared-Memory Object Store. The sender process maintains a writer instance, while each receiver process has a corresponding reader instance.
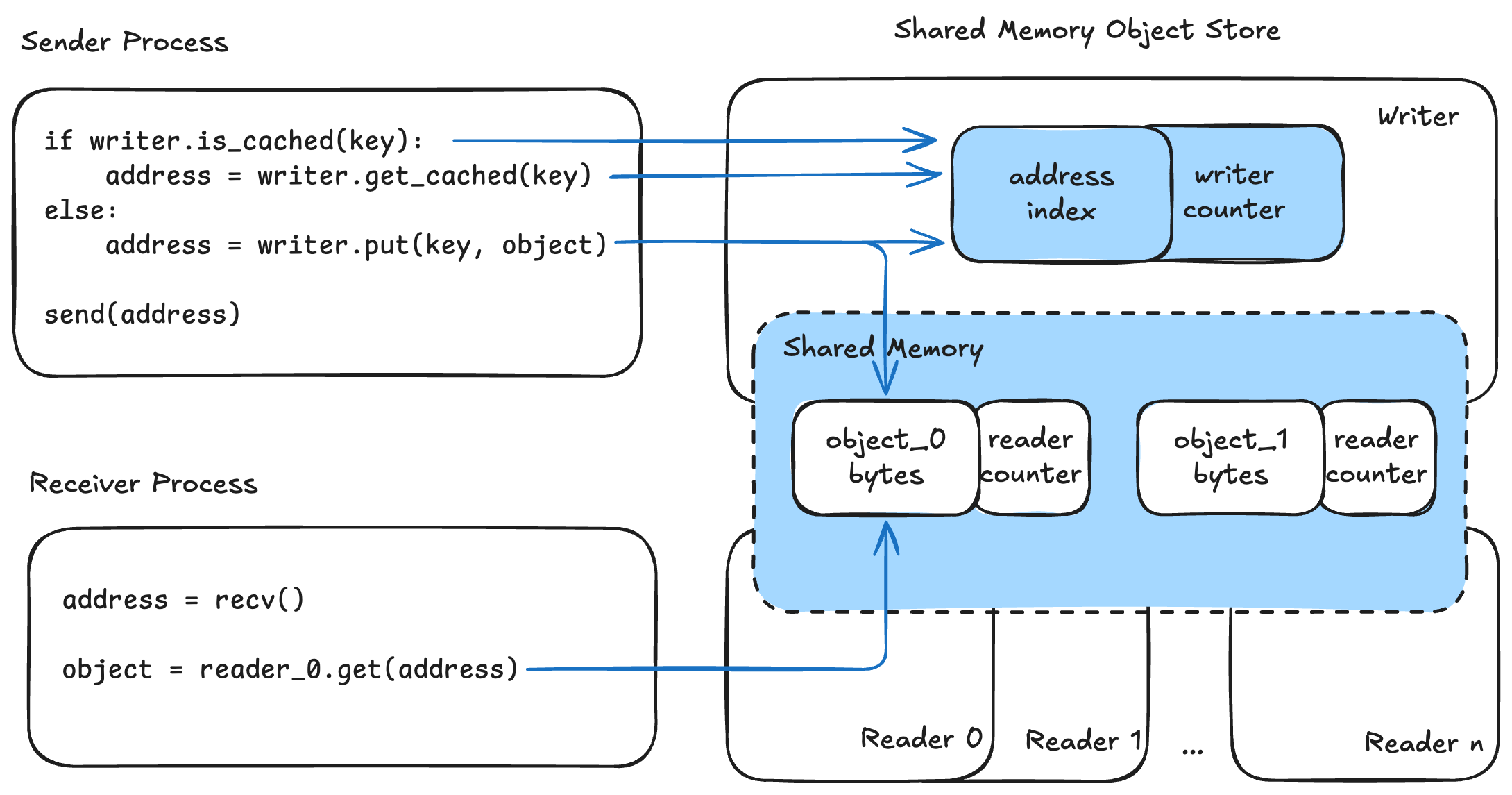
Figure 2. Diagram of IPC caching using a shared-memory object store
When sending a key–object pair, the sender first checks whether the key is cached via is_cached(key). If cached, the writer retrieves the buffer address using get_cached(key); otherwise, it stores the object in shared memory with put(key, object) and obtains the buffer address. The sender then broadcasts this address to all receivers through default IPC.
On the receiver side, the address is received, and the object is fetched from shared memory using get(address). Serialization and deserialization steps are omitted for simplicity.
Eviction and safety
When space runs low, the writer evicts from the ring buffer head.
Reader counters (shared) and writer counters (local) coordinate to prevent premature eviction while data is still in use. An entry is evicted only when the condition writer_counter × n_readers == reader_counter is satisfied.
Benefits
- No ordering assumptions: Processes can consume inputs in any order
- Single shared cache: Shared memory usage remains constant regardless of the number of readers.
- Efficient concurrent access: Multiple readers can read the same input simultaneously with minimal synchronization overhead and without extra copies.
Applying the Shared Memory Object Store to our previous front-end–coordinator–worker setup, we place the writer in the front-end process and a dedicated reader in each worker process. This allows us to bypass intermediate IPC, especially for large input data.
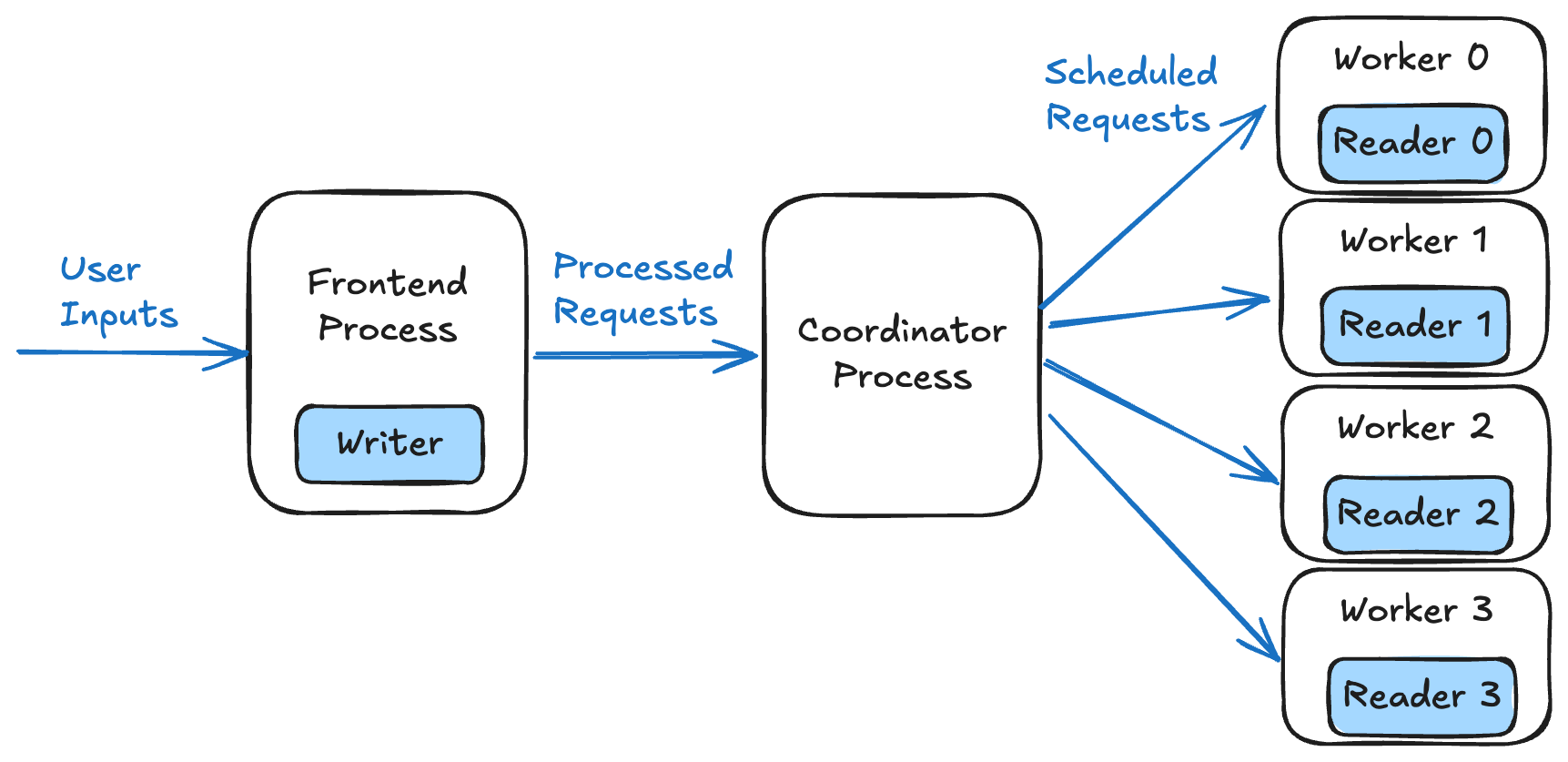
Figure 3. Overview of process coordination in an LLM inference system backed by a Shared-Memory Object Store
vLLM benchmark results
We implemented Shared Memory IPC Caching for multimodal inputs in vLLM via a PR. To evaluate its impact, we ran benchmarks using:
- Model:
CohereLabs/command-a-vision-07-2025 - Hardware: 4× A100 (80GB, TP=4)
- Dataset: VisionArena-Chat
Here are the results:
First-time requests
| Metric | Baseline | Shared Memory IPC Cache | Difference |
|---|---|---|---|
| Prefill throughput | 581.34 tok/s | 648.22 tok/s | +11.5% |
| Mean TTFT | 3898.98 ms | 3491.15 ms | −10.5% |
The speedup comes from writing once in the front-end and letting workers read concurrently, eliminating both redundant transfers and IPC queuing delays.
Cached requests
| Metric | Baseline | Shared Memory IPC Cache | Difference |
|---|---|---|---|
| Prefill throughput | 2894.03 tok/s | 4917.57 tok/s | +69.9% |
| Mean TTFT | 790.18 ms | 470.60 ms | −40.5% |
In this scenario, both KV and image inputs are cached, making the benefits of reduced IPC overhead especially visible.
Get started today
Shared Memory IPC Caching accelerates data movement in LLM systems, making them leaner and more scalable — especially for workloads with large multimodal inputs or multiple concurrent GPU workers. Beyond LLM inference, it can boost performance wherever IPC caching helps reduce redundant data transfers, making it a versatile tool for a wide range of applications.
This feature is now available on the vLLM main branch. To enable it for multimodal caching, set mm_processor_cache_type = "shm". Learn more on vLLM User Guide.
Acknowledgments
Special thanks to Bharat Venkitesh at Cohere and members of the vLLM community: Cyrus Leung, for valuable feedback on code reviews and integration; Nick Hill and Roger Wang, for early-stage concept verification; and Kero Liang for reporting and helping to fix a bug.