vLLM Router: A High-Performance and Prefill/Decode Aware Load Balancer for Large-scale Serving
Efficiently managing request distribution across a fleet of model replicas is a critical requirement for large-scale, production vLLM deployments. Standard load balancers often fall short as they lack awareness of the stateful nature of LLM inference (e.g., KV cache) and cannot manage complex serving patterns like prefill/decode disaggregation.
To address this, we are introducing the vLLM Router (Github repo), a high-performance, lightweight load balancer engineered specifically for vLLM. Built in Rust for minimal overhead, the router acts as an intelligent, state-aware load balancer that sits between clients and a fleet of vLLM workers, either in a K8s or a bare metal GPU cluster.
The vLLM Router is derived from a fork of the SGLang model gateway, modified and simplified to work with vLLM. Further divergence is anticipated as we explore merging this router into the vLLM main repo. On the other hand, the gateway functionalities for large-scale deployment may be unified in collaboration with SGLang model gateway developers.
Core Architecture and Capabilities
The vllm-router is designed to solve two primary challenges in large-scale serving: intelligent load balancing and support for prefill/decode disaggregation.
1. Intelligent Load Balancing Strategies
Unlike a simple round-robin, the vLLM Router provides multiple, sophisticated load balancing algorithms to optimize for performance and stateful affinity. For conversational workloads, routing subsequent requests from the same user to the same worker that holds their KV cache is critical for minimizing latency.
The router supports several policies to this end:
- Consistent Hashing: This is the key policy for maximizing performance. It ensures that requests with the same routing key (e.g., a session ID or user ID) are “sticky” and consistently routed to the same worker replica, maximizing KV cache reuse.
- Power of Two (PoT): A low-overhead random-choice policy that provides excellent load distribution.
- Round Robin & Random: Standard policies for stateless load distribution.
2. Native Support for Prefill/Decode Disaggregation
The router is designed as the orchestration layer for vLLM’s most advanced serving architecture: prefill/decode (P/D) disaggregation.
In this architecture, the compute-intensive prefill step and the memory-intensive decode step are handled by separate, specialized worker groups. The vLLM Router manages this complex workflow:
- It intelligently routes new requests to the prefill worker group.
- Upon completion, it directs the request state to the appropriate decode worker for token generation.
- It supports discovery and routing for both NIXL and NCCL-based (with ZMQ discovery) disaggregation backends.
Enterprise-Grade Resiliency and Observability
The vllm-router is built with production-grade features for maintaining high availability in large-scale environments.
- Kubernetes Service Discovery: The router can operate in a Kubernetes-native mode, automatically discovering, monitoring, and routing to vLLM worker pods using label selectors.
- Fault Tolerance: It includes configurable retry logic (with exponential backoff and jitter) and circuit breakers. If a worker fails health checks, the router immediately removes it from the routing pool and will retry requests, preventing cascading failures.
- Observability: A built-in Prometheus endpoint (
/metrics) exports detailed metrics on request volume, latency, error rates, and the health of individual workers, providing complete visibility into the serving fleet.
Benchmark Analysis: The Most Performant Choice at Scale
We benchmarked the new vLLM Router against two widely used alternatives:
- llm-d: A Kubernetes-native routing framework that utilizes default queue-aware load balancing.
- vLLM-native: The standard K8s native load balancer, which employs a basic round-robin strategy. Crucially, this option is not aware of Prefill/Decode states, treating all pods as identical vLLM replicas.
Note on Exclusion: We excluded the vLLM built-in DP/EP coordinator—the recommended External Load Balancing solution for vLLM clusters—from the benchmark. Its throughput was only 1/8 of the others due to a known performance issue.
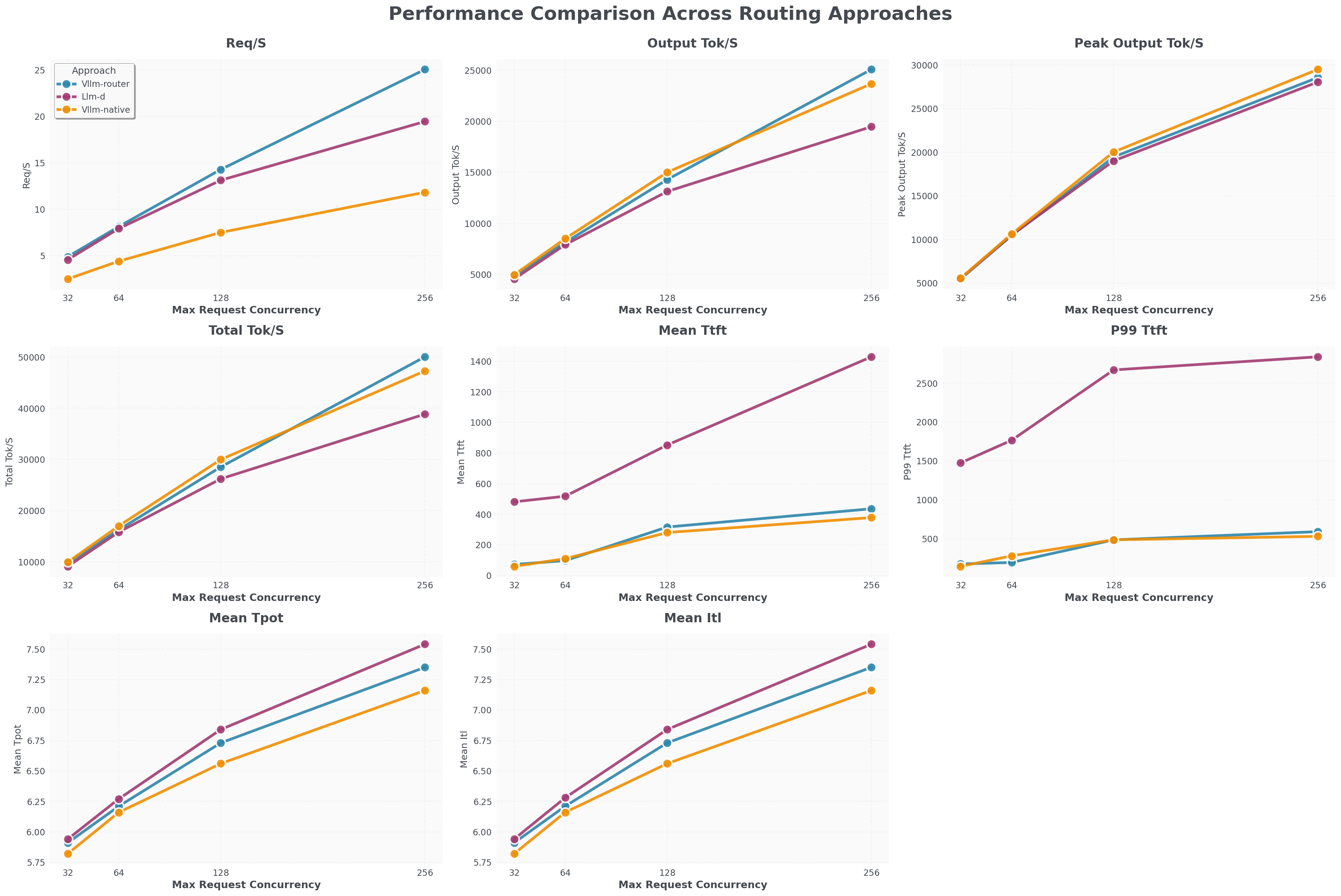
Llama 3.1 8B with 8 Prefill pods and 8 Decode pods
- vLLM Router (blue line) Req/S throughput is 25% higher than llm-d (purple line) and 100% higher than K8s-native load balancer (orange line).
- vLLM Router’s TTFT is close to K8s-native load balancer and 1200 ms faster than llm-d.
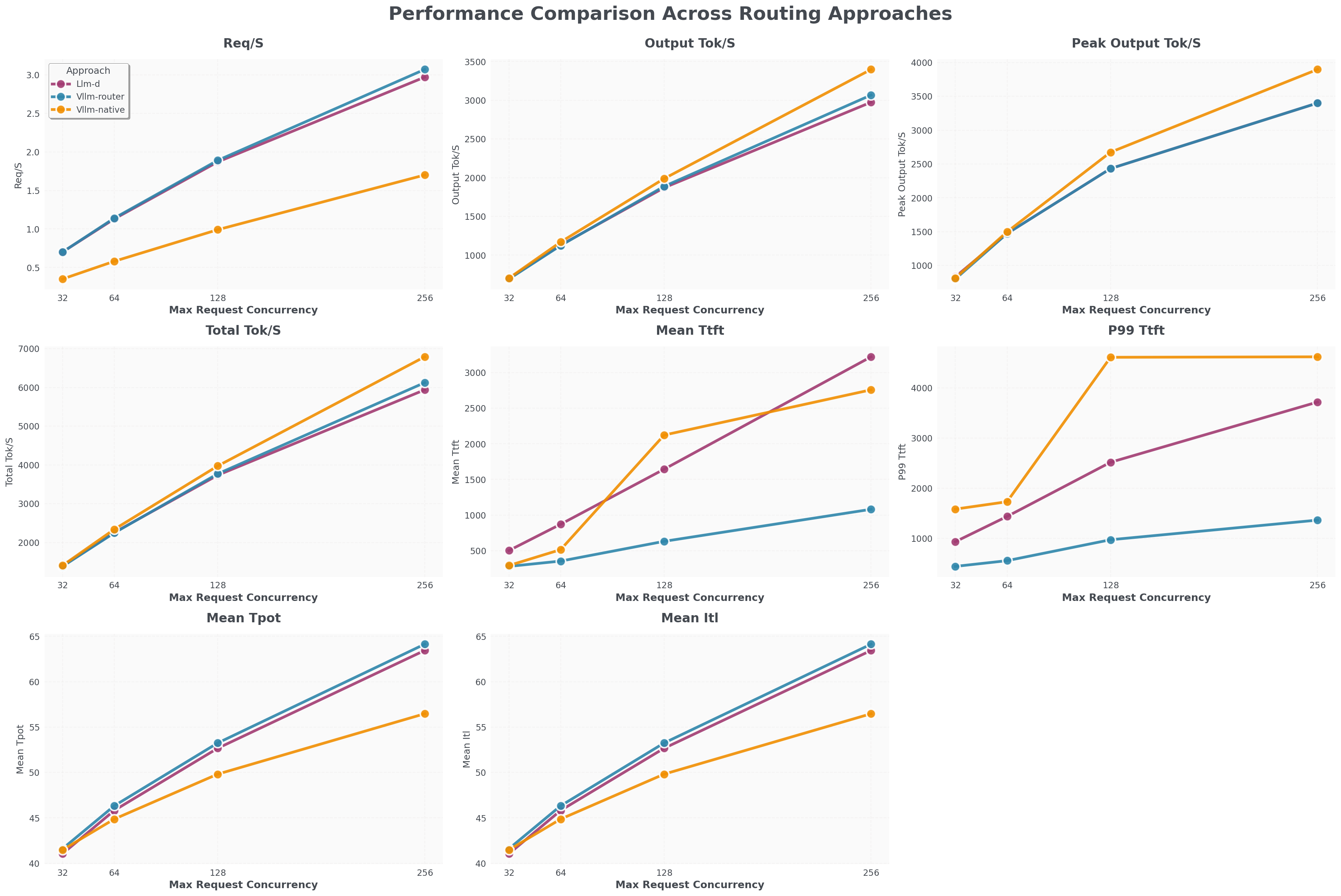
Deepseek V3 with 1 Prefill pod (TP8) and 1 Decode pod (TP8)
- vLLM Router (blue line) Req/S throughput is close to llm-d (purple line) and 100% higher than K8s-native load balancer (orange line).
- vLLM Router’s TTFT is 2000 ms faster than llm-d and K8s-native.
Summary
The vLLM Router is an essential component for operating vLLM at production scale. It transitions the serving architecture from a collection of individual instances to a single, unified, and resilient fleet. By providing intelligent load balancing and native support for prefill/decode disaggregation, it unlocks new levels of performance and operational efficiency.
Acknowledgements
- Thanks to Phi and the AWS team for providing technical support and the test clusters.
- Special thanks to Naman Lalit for driving the comprehensive performance and correctness benchmarking efforts.
- We also acknowledge the SGLang Model Gateway team. By forking their established API implementation and service framework, we were able to significantly accelerate our design and implementation process while maintaining alignment with open standards.
- Finally, we thank Tyler Michael Smith and Robert Shaw for sharing llm-d expertise and receipts which unblocked performance optimizations and benchmarks.