Encoder Disaggregation for Scalable Multimodal Model Serving
Motivation: Why Disaggregate the Encoder in LMM Serving?
Modern Large Multimodal Models (LMMs) introduce a unique serving-time bottleneck: before any text generation can begin, all images must be processed by a visual encoder (e.g., ViT). This encoder stage has a very different computational profile from text prefill and decode. Running encoder + prefill + decode on the same GPU instance—today’s common approach—creates fundamental inefficiencies.
Problems With Colocating Encoder and Text Generation
1. Encoder–Prefill–Decode Interference
Current pipeline (E+PD on the same GPU):
[E PD] -> [E PD] -> [E PD]- All requests must finish both stages before the next can proceed.
- Encoder work cannot overlap with prefill/decode for other requests.
Effects:
- The encoder is slow and variable (depends on resolution, number of images, complexity).
- When mixed with text-only requests, a single LMM input can stall the entire batch.
- Prefill and streaming decode latencies become jittery and unpredictable.
- Compute-bound encoder and memory-bound decode must share the same hardware and parallelism strategy, which is suboptimal for both.
2. Coupled and Inefficient Resource Allocation
The three phases have different optimal profiles:
- Encoder: one-shot, compute-bound, high parallelism.
- Prefill: high memory bandwidth, large GEMMs.
- Decode: heavily memory-bound, long-lived, sequential.
Colocation forces one parallelism plan and one resource ratio across all stages, meaning:
- You cannot scale encoder throughput without overprovisioning text-generation GPUs.
- Occasional multimodal requests create outsized cost and inefficiency.
Solutions: Encoder Disaggregation
Separating the visual encoder into its own scalable service unlocks major benefits.
1. Pipelined Execution and Elimination of Interference
With disaggregation:
E → P D (Request 1)
......E → P D (Request 2)
..........E → P D (Request 3)
- Encoder for request N can run while request N–1 is already in prefill or decode.
- Text-only requests bypass the encoder entirely and never wait behind image jobs.
- This removes encoder-induced queueing delays.
- The system becomes pipeline-parallel, increasing throughput and smoothing latency.
2. Independent, Fine-Grained Scaling
Each stage can finally scale to its own demand curve:
- Scale encoder GPUs based on multimodal image volume.
- Scale prefill/decode GPUs based on total request rate and output length.
This prevents waste:
- No more buying large decode clusters just to handle rare image spikes.
- Each pool uses the right hardware and parallelism strategy.
3. Encoder Output Caching and Reuse
A centralized encoder service naturally supports a cross-request cache:
- The embedding for a frequently used image (e.g., logos, diagrams, product photos) is computed once and reused across users/requests.
- Cached requests have zero encoder cost, directly reducing TTFT.
- The encoder load decreases substantially as cache hit rates grow.
Design
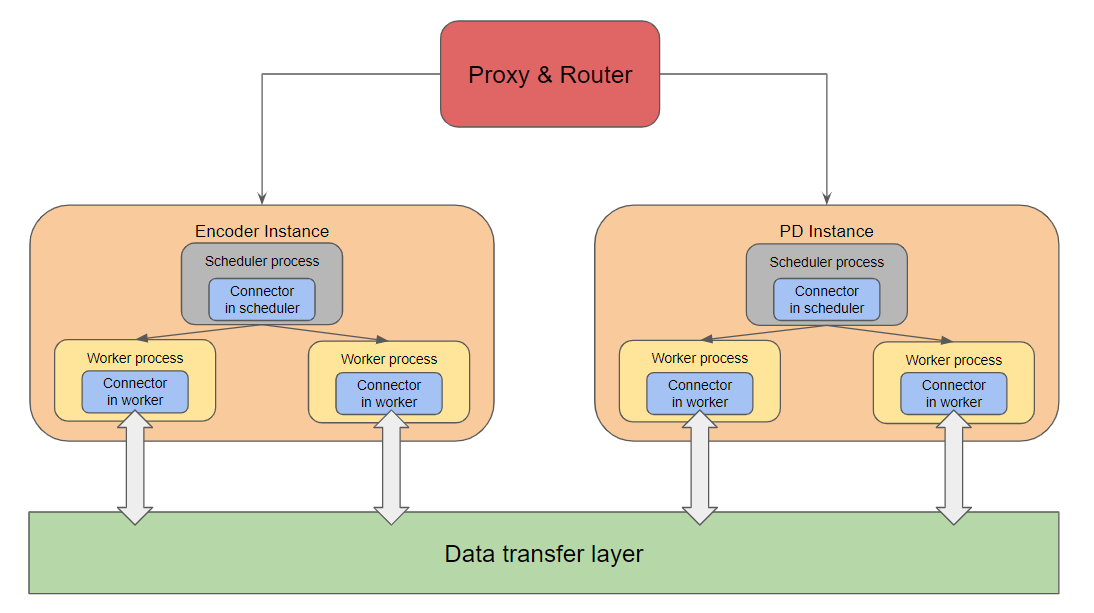
Components
Proxy & Router
- Orchestrates request flow.
- Sends multimodal (MM) inputs to encoder instances.
- Waits for encoder completion before forwarding the original request (with image embeddings now available in remote storage) to prefill/decode (PD) instances.
Data Transfer Layer
- Remote storage for encoder-produced multimodal embeddings (Encoder Cache, or EC, embeddings).
- Serves as the shared transport medium between encoder workers and PD workers.
EC Connectors
- Bridge between workers/schedulers and the data transfer layer.
- Handle storing and retrieving encoder caches.
Roles:
- Scheduler-side connector:
- Determines which multimedia embeddings should be loaded or saved in the current scheduling iteration.
- Produces metadata describing required cache operations for downstream workers.
- Worker-side connector:
- Executes actual load/save operations (read/write to remote storage).
- Manages per-worker runtime embedding transfers.
Workflow
Dataflow Graph
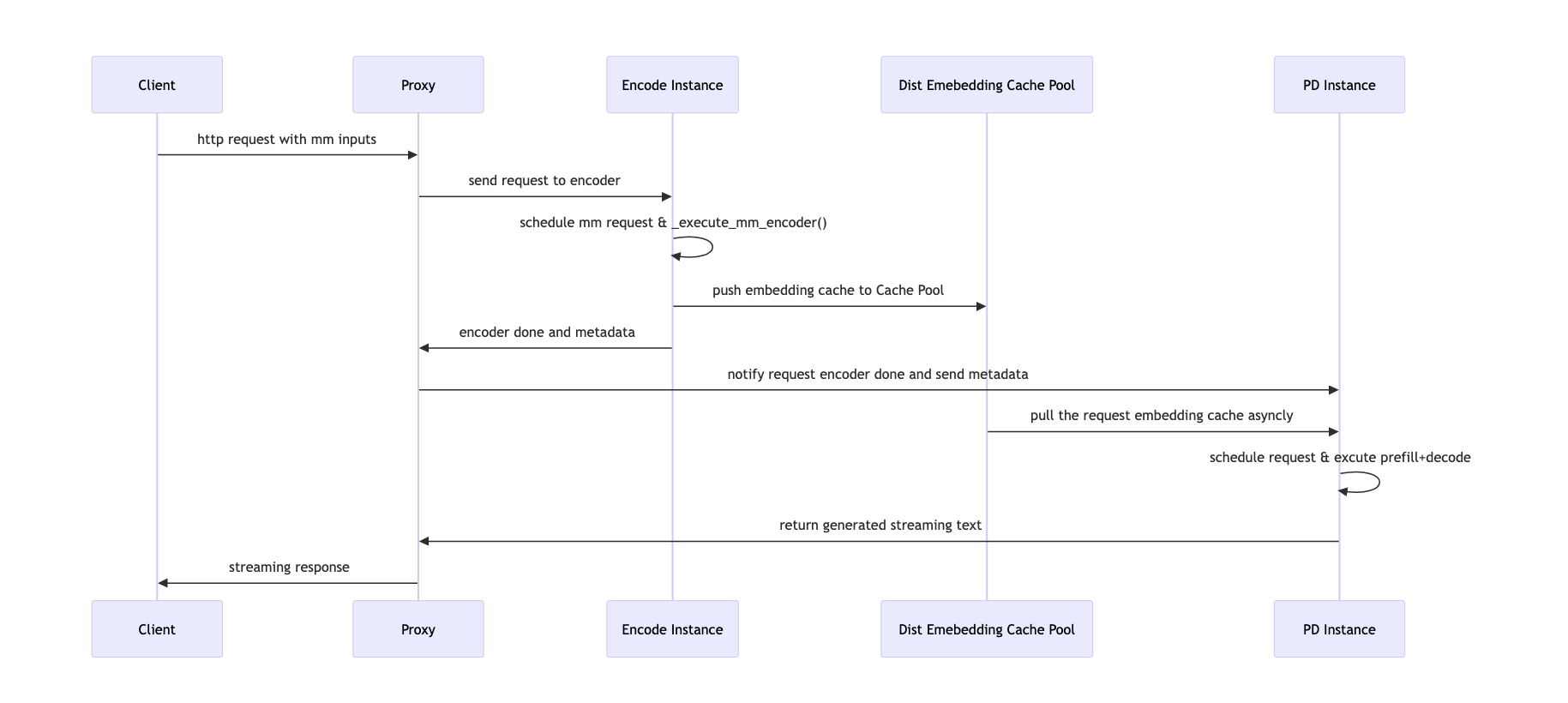
Request Lifecycle
- Proxy receives request
- Extracts multimodal inputs from the original request.
- Creates N encoder jobs (one per MM input) and dispatches them to encoder instances.
- Encoder scheduling
- Encoder scheduler runs the jobs, computes embeddings.
- Stores computed embeddings into remote storage via EC connectors.
- Encoder completion
- Encoder workers notify the proxy when all embeddings have been stored.
- Proxy forwards request to PD instance
- Original request (with image hashes but no pixel data) is sent to prefill/decode nodes.
- PD execution
- PD instance loads MM embeddings from remote storage using EC connectors.
- Executes prefill and decode normally, injecting embeddings directly into the model runner cache.
Implementation
Core Components
1. ECConnectorRole
Defines where the connector instance runs:
class ECConnectorRole(enum.Enum):
SCHEDULER = 0 # in scheduler process
WORKER = 1 # in worker process
2. ECConnectorMetadata
Abstract synchronization/state object shared between scheduler-side and worker-side connectors:
class ECConnectorMetadata(ABC):
pass
3. ECConnectorBase
Abstract interface for all connectors.
Key fields:
role: scheduler or workerconfig: connector-specific configmetadata: ECConnectorMetadata
Key methods:
has_caches(request): check if remote embeddings already existbuild_connector_meta(sched_output): determine which caches workers must loadupdate_state_after_alloc(request, item): update cache allocation based on cache hit/misssave_caches(encoder_cache): push encoder outputs to remote storagestart_load_caches(metadata): load caches on the PD side before prefill/decode execution
Scheduler-Side Behavior
1. Connector Initialization
Scheduler:
if self.vllm_config.ec_transfer_config is not None:
self.ec_connector = ECConnectorFactory.create_connector(
config=self.vllm_config,
role=ECConnectorRole.SCHEDULER,
)
Worker:
def ensure_ec_transfer_initialized(vllm_config):
global _EC_CONNECTOR_AGENT
if vllm_config.ec_transfer_config is None:
return
if vllm_config.ec_transfer_config.is_ec_transfer_instance and _EC_CONNECTOR_AGENT is None:
_EC_CONNECTOR_AGENT = ECConnectorFactory.create_connector(
config=vllm_config,
role=ECConnectorRole.WORKER,
)
2. Remote Cache Check
When scheduling media items:
remote_cache_has_item = self.ec_connector.has_caches(request)
3. Cache State Updates
After scheduling:
for i in external_load_encoder_input:
self.encoder_cache_manager.allocate(request, i)
if self.ec_connector:
self.ec_connector.update_state_after_alloc(request, i)
4. Metadata Construction
At the end of a scheduler iteration:
ec_meta = self.ec_connector.build_connector_meta(scheduler_output)
scheduler_output.ec_connector_metadata = ec_meta
Worker-Side Behavior
Workers use ECConnectorModelRunnerMixin to integrate connector operations into GPU model runners.
Execution Integration
Encoder Side (Saving to Remote Storage)
After computing embeddings:
for (mm_hash, pos_info), output in zip(mm_hashes_pos, encoder_outputs):
self.encoder_cache[mm_hash] = scatter_mm_placeholders(...)
self.maybe_save_ec_to_connector(self.encoder_cache, mm_hash)
Prefill/Decode Side (Loading Remote Embeddings)
The media encoder path is wrapped with a loader that injects cached embeddings before running the local encoder:
with self.maybe_get_ec_connector_output(
scheduler_output,
encoder_cache=self.encoder_cache,
) as ec_connector_output:
self._execute_mm_encoder(scheduler_output)
mm_embeds, is_mm_embed = self._gather_mm_embeddings(scheduler_output)
Performance Results
Environment: 4×A100 80G
Dataset: Random multimodal dataset (vllm bench serve --dataset-name random-mm)
Inputs: 400 / 2000 text tokens; 1–4 images per request (640×640 → ~400 visual tokens each)
Outputs: 150 tokens
QPS range: 4–24
Model: Qwen3‑VL‑4B‑Instruct
Baseline: 1 Encoder + 3 PD instances (1E3PD) vs Data Parallel (--data-parallel-size 4)
Production‑grade LMM serving systems require strict tail‑latency guarantees—typically P99 TTFT and P99 TPOT—for worst‑case reliability. We define goodput as the maximum sustainable request rate at which both SLOs are met (20000 ms TTFT, 100 ms TPOT in our evaluation).
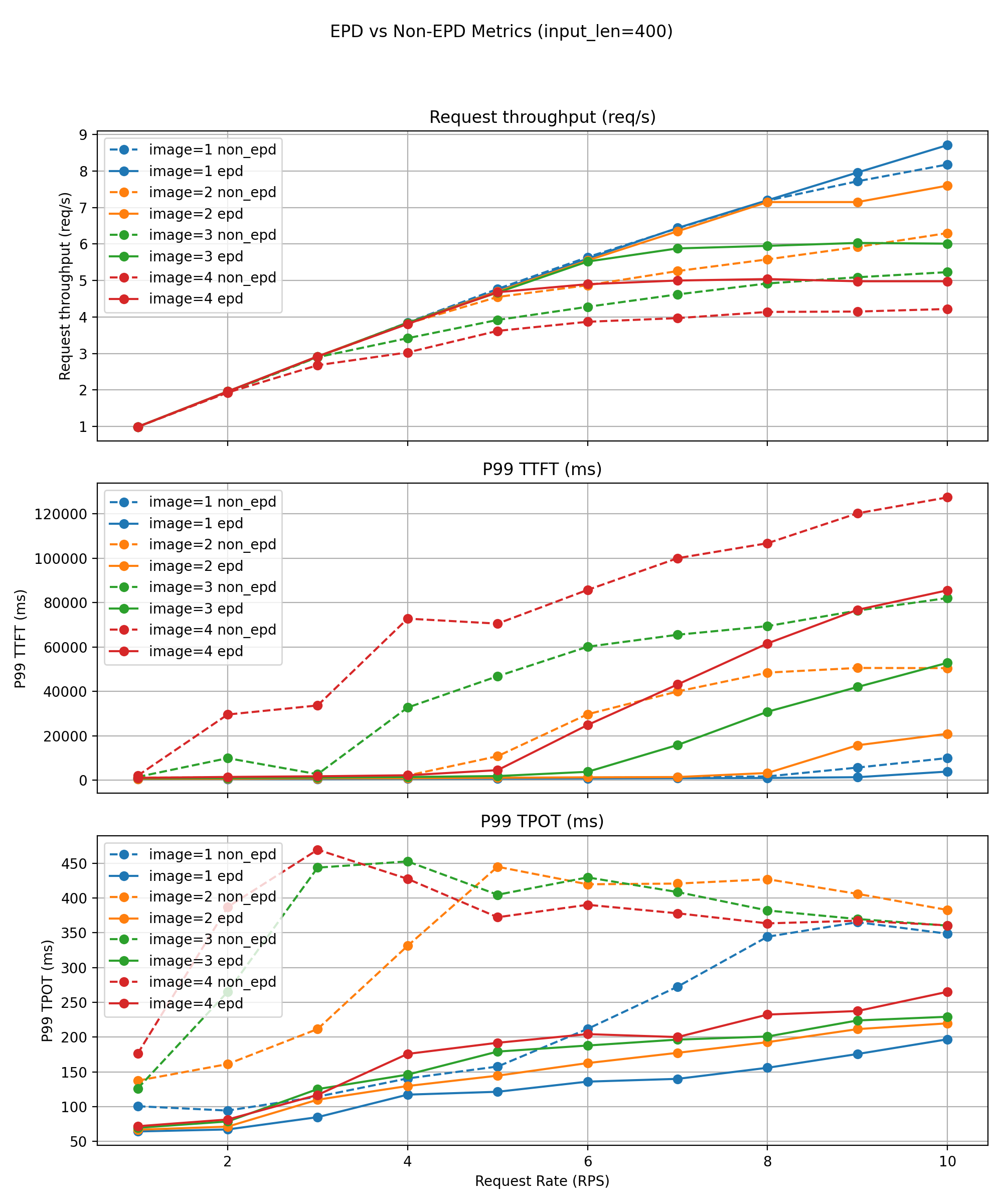
Short‑Text Workloads (~400 tokens)
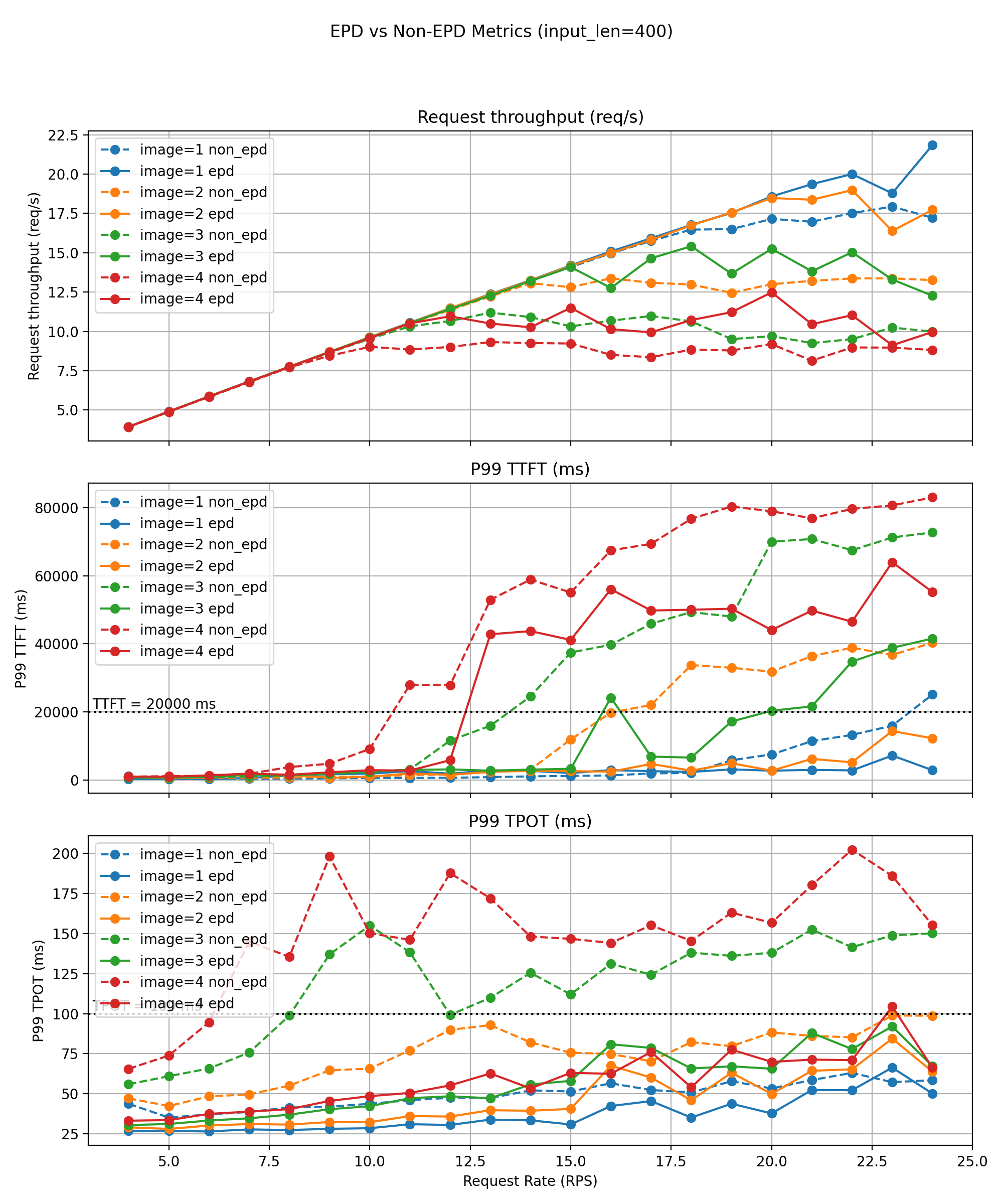
For short‑text requests, EPD’s benefits increase sharply with the number of images per request.
- Single‑image: modest goodput improvement (23 → 24 QPS).
- Four‑image: goodput doubles (6 → 12 QPS).
Tail latency improves significantly:
- P99 TTFT/TPOT often 20–50% lower than the non‑EPD baseline.
Throughput‑versus‑rate curves show:
- Without EPD, multi‑image workloads destabilize around 12–14 QPS, where P99 TPOT spikes by 30–50%, violating SLOs.
- EPD shifts this instability threshold substantially higher and maintains smoother, slower‑growing latency curves, thanks to the removal of encoder‑decode interference and the ability for text‑only requests to bypass visual workloads entirely.
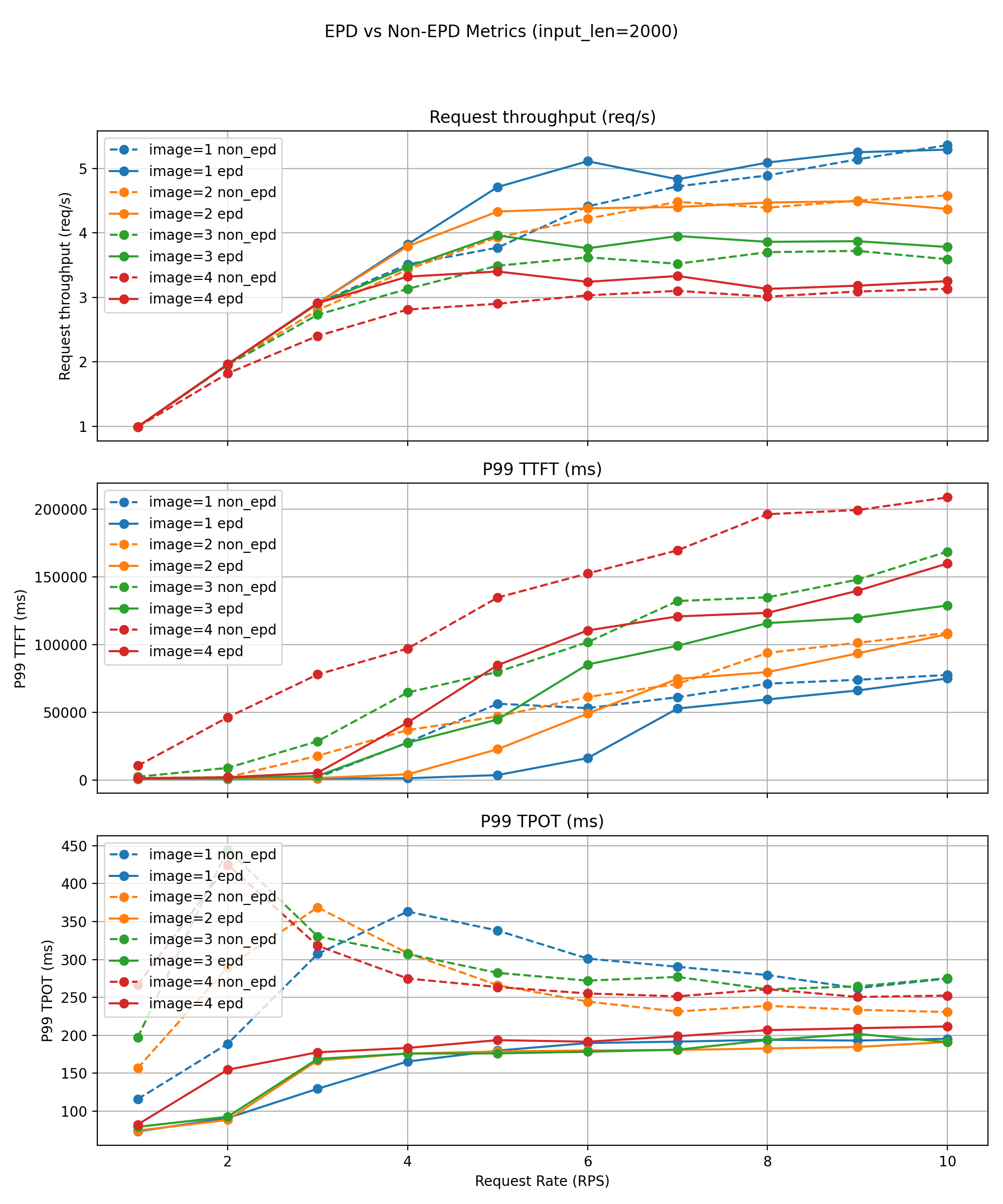
Long‑Text Workloads (~2000 tokens)
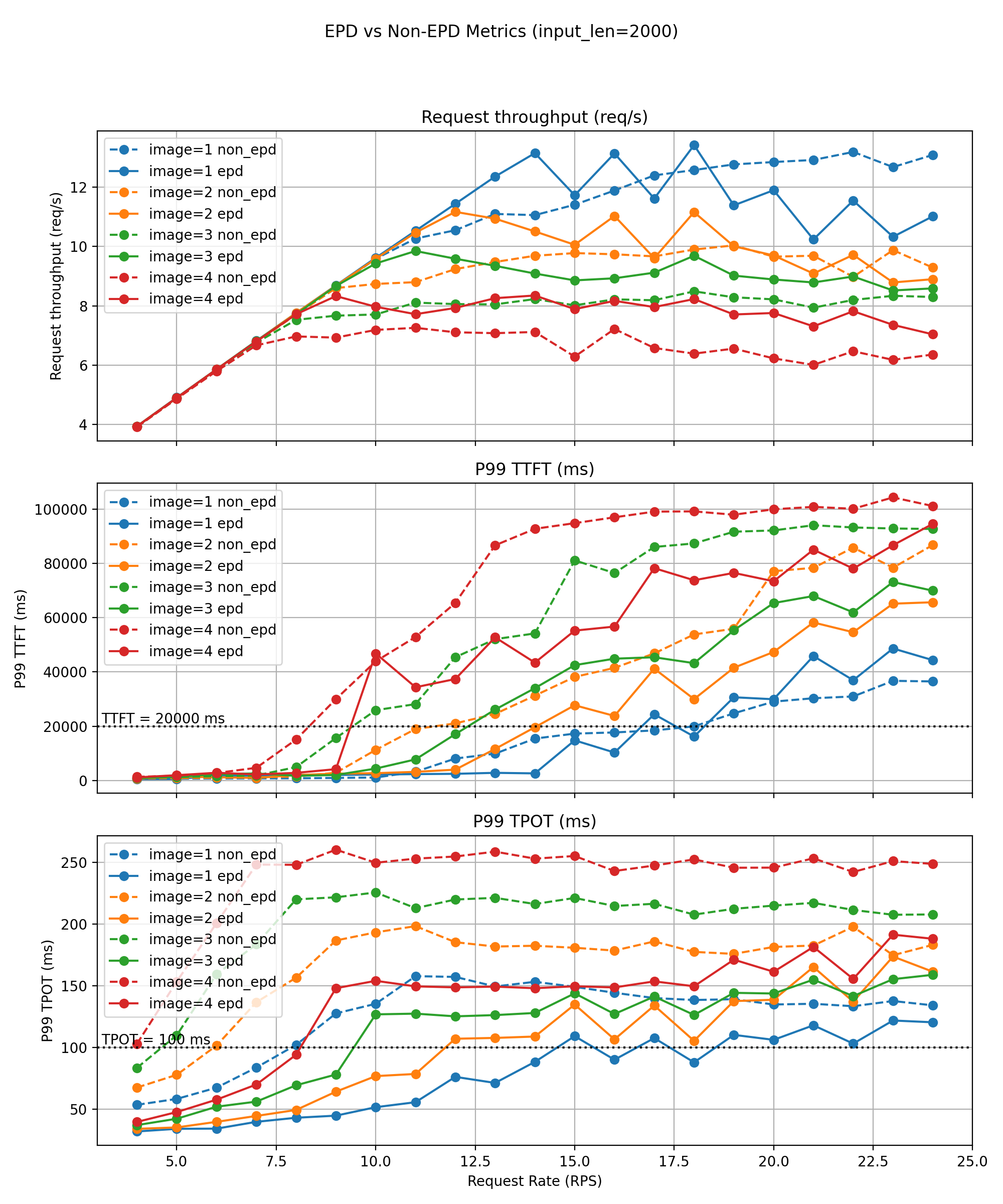
With longer inputs, image‑encoding costs become a small fraction of total work, placing the system in a decode‑dominated regime. Even here, EPD achieves substantial gains.
Baseline sustainable QPS before P99 violations:
- 1 image: 8 QPS
- 3–4 images: 4 QPS
EPD maintains:
- 18 / 11 / 9 / 8 QPS, respectively — 2× to 2.5× better goodput.
Additional improvements:
- Effective decoding throughput increases 10–30% across all multimodal settings.
- P99 TTFT reductions of 30–50%.
- P99 TPOT reductions of 20–40% within stable operating regions.
The decoupled Encode/Text pipeline eliminates modal contention, enabling higher concurrency, improved throughput, and tighter SLO adherence even under heavy multimodal load.
Hardware Portability: Ascend NPU
We replicated the experiments on Ascend NPUs with minimal changes:
- Environment: 4×Ascend 910B 32G
- Model: Qwen2.5‑VL‑7B‑Instruct
- QPS: 1–10
Across all Ascend experiments, EPD exhibits the same hardware‑agnostic benefits:
- Consistently higher throughput (5–20% across stable regions).
- Significant reductions in P99 TTFT and P99 TPOT.
- Delayed congestion points and tighter tail‑latency profiles.
This confirms that EPD’s gains stem from architectural decoupling—not hardware idiosyncrasies—making it portable across GPU and NPU platforms.
Conclusion
Through careful analysis of LMM inference behavior and production workload demands, we developed a decoupled, pipeline‑parallel multimodal serving architecture that:
- reduces TTFT and TPOT,
- improves throughput and stability,
- eliminates cross‑modal interference, and
- enables efficient, scalable, multimodal serving.
This architecture provides a practical blueprint for next‑generation high‑performance LMM serving systems. Moving forward, we will continue to enhance vLLM by optimizing parameter loading for encoder instances and expanding EC connector support.
Related Work
ViT DP + LM TP
Before exploring encoder disaggregation, vLLM first introduced a hybrid parallelism strategy for multimodal models on a single node: the ViT Data Parallel + LLM Tensor Parallel approach, where the vision encoder runs with data parallelism across GPUs while the language model uses tensor parallelism. This hybrid strategy dramatically reduces TTFT and improves overall throughput. The approach has since been proven effectiveness and adopted by other serving frameworks, such as SGLang.
Prior Art and Industry Adoption
NVIDIA Dynamo team has first supported EPD-style disaggregation with vLLM, though the documentation was limited. The vLLM native EPD implementation (PR #25233) was merged in early November 2025 and became available since release 0.11.1, bringing first-class encoder disaggregation support to the open-source ecosystem.
Reference
- Qiu, Haoran, et al. ModServe: Modality‑ and Stage‑Aware Resource Disaggregation for Scalable Multimodal Model Serving. 2025.
- Singh, G., et al. Efficiently Serving Large Multimodal Models Using Encoder-Decoder Disaggregation. 2025.
Acknowledgments
We would like to thank the main contributors—ZHENG Chenguang, Nguyen Kha Nhat Long, Tai Ho Chiu Hero, Le Manh Khuong, Wu Hang, and Wu Haiyan—for their substantial contributions and technical expertise throughout the development of this project. Special thanks also go to the community maintainers, Roger Wang, Nicolò Lucchesi, and Cyrus Leung, for their valuable feedback, insightful reviews, and careful guidance during code integration, which significantly improved the quality and stability of the codebase.