AMD × vLLM Semantic Router: Building the System Intelligence Together
Introduction
Over the past several months, AMD and the vLLM SR Team have been collaborating to bring vLLM Semantic Router (VSR) to AMD GPUs—not just as a performance optimization, but as a fundamental shift in how we think about AI system architecture.
AMD has been a long-term technology partner for the vLLM community, from accelerating the vLLM inference engine on AMD GPUs and ROCm™ Software to now co-building the next layer of the AI stack: intelligent routing and governance for Mixture-of-Models (MoM) systems.
As AI moves from single models to multi-model architectures, the challenge is no longer “how big is your model” but how intelligently and safely you orchestrate many models together. VSR is designed to be the intelligent control plane for this new era—making routing decisions based on semantic understanding, enforcing safety policies, and maintaining trust as systems scale toward AGI-level capabilities.

This collaboration focuses on three strategic pillars:
- Signal-Based Routing: Intelligent request routing using keyword matching, domain classification, semantic similarity, and fact-checking for Multi-LoRA and multi-model deployments
- Cross-Instance Intelligence: Shared state and optimization across vLLM instances through centralized response storage and semantic caching
- Guardrails & Governance: Enterprise-grade security from PII detection and jailbreak prevention to hallucination detection and alignment enforcement
Together with AMD, we’re building VSR to run efficiently on AMD GPUs while establishing a new standard for trustworthy, governable AI infrastructure.
The Shift: From Single Models to Mixture-of-Models
In a Mixture-of-Models world, an enterprise AI stack typically includes:
- Router SLMs (small language models) that classify, route, and enforce policy
- Multiple LLMs and domain-specific models (e.g., code, finance, healthcare, legal)
- Tools, RAG pipelines, vector search, and business systems
Without a robust routing layer, this becomes an opaque and fragile mesh. The AMD × VSR collaboration aims to make routing a first-class, GPU-accelerated infrastructure component—not an ad-hoc script glued between services.
VSR Core Capabilities
1. Signal-Based Routing for Multi-LoRA Deployments
VSR provides multiple routing strategies to match different use cases:
- Keyword-based routing: Simple pattern matching for fast, deterministic routing
- Domain classification: Intent-aware adapter selection using trained classifiers
- Embedding-based semantic similarity: Nuanced routing based on semantic understanding
- Fact-checking and verification routing: High-stakes queries routed to specialized verification pipelines
2. Cross-Instance Intelligence
VSR enables shared state and optimization across all vLLM instances:
- Response API: Centralized response storage enabling stateful multi-turn conversations
- Semantic Cache: Significant token reduction through cross-instance vector similarity matching
3. Enterprise-Grade Guardrails
From single-turn to multi-turn conversations, VSR provides:
- PII Detection: Prevent sensitive information leakage
- Jailbreak Prevention: Block malicious prompt injection attempts
- Hallucination Detection: Verify response reliability for critical domains
- Super Alignment: Ensuring AI systems remain aligned with human values and intentions as they scale toward AGI capabilities
Running VSR on AMD GPUs: Two Deployment Paths
Our near-term objective is execution-oriented: deliver a production-grade VSR solution that runs efficiently on AMD GPUs. We’re building two complementary deployment paths:
Path 1: vLLM-Based Inference on AMD GPUs
Using the vLLM engine on AMD GPUs, we run:
Router SLMs for:
- Task and intent classification
- Risk scoring and safety gating
- Tool and workflow selection
LLMs and specialized models for:
- General assistance
- Domain-specific tasks (finance, legal, code, healthcare)
VSR sits above as the decision fabric, consuming semantic similarity, business metadata, latency constraints, and compliance requirements to perform dynamic routing across models and endpoints.
AMD GPUs provide the throughput and memory footprint needed to run router SLMs + multiple LLMs in the same cluster, supporting high-QPS workloads with stable latency—not just one-off demos.
Path 2: Lightweight ONNX-Based Routing
Not all routing needs a full inference stack. For ultra-high-frequency, latency-sensitive stages at the “front door” of the system, we’re enabling:
- Exporting router SLMs to ONNX
- Running them on AMD GPUs through ONNX Runtime
- Forwarding complex generative work to vLLM or other back-end LLMs
This lightweight path is designed for:
- Front-of-funnel traffic classification and triage
- Large-scale policy evaluation and offline experiments
- Enterprises that want to standardize on AMD GPUs while keeping model providers flexible
Moving to the Next Stage of Semantic Router
When we first built vLLM Semantic Router, the goal was clear and practical: intelligent model selection—routing requests to the right model based on task type, cost constraints, and performance requirements.

vLLM Engine delivers the foundation—running large models stably and efficiently. vLLM Semantic Router provides the scheduler—dispatching requests to the right capabilities.
But as AI systems move toward AGI-level capabilities, this framing feels incomplete. It’s like discussing engine efficiency without addressing brakes, traffic laws, or safety systems.
The real challenge isn’t making models more powerful—it’s maintaining control as they become more powerful.
From Models Director to Intelligence Judger
Working with AMD, we’ve come to see Semantic Router’s evolution differently. Its potential lies not just in “routing,” but in governance—transforming from a traffic director into an Intelligence Control Plane for the AGI era.
This shift changes how we think about the collaboration. We’re not just optimizing for throughput and latency on AMD hardware. We’re building a constitutional layer for AI systems—one defined by responsibilities, not just features.
Three Control Lifelines That Must Be Secured
As we architect VSR on AMD’s infrastructure, we’re designing around three critical control points that determine whether AI systems remain trustworthy at scale:
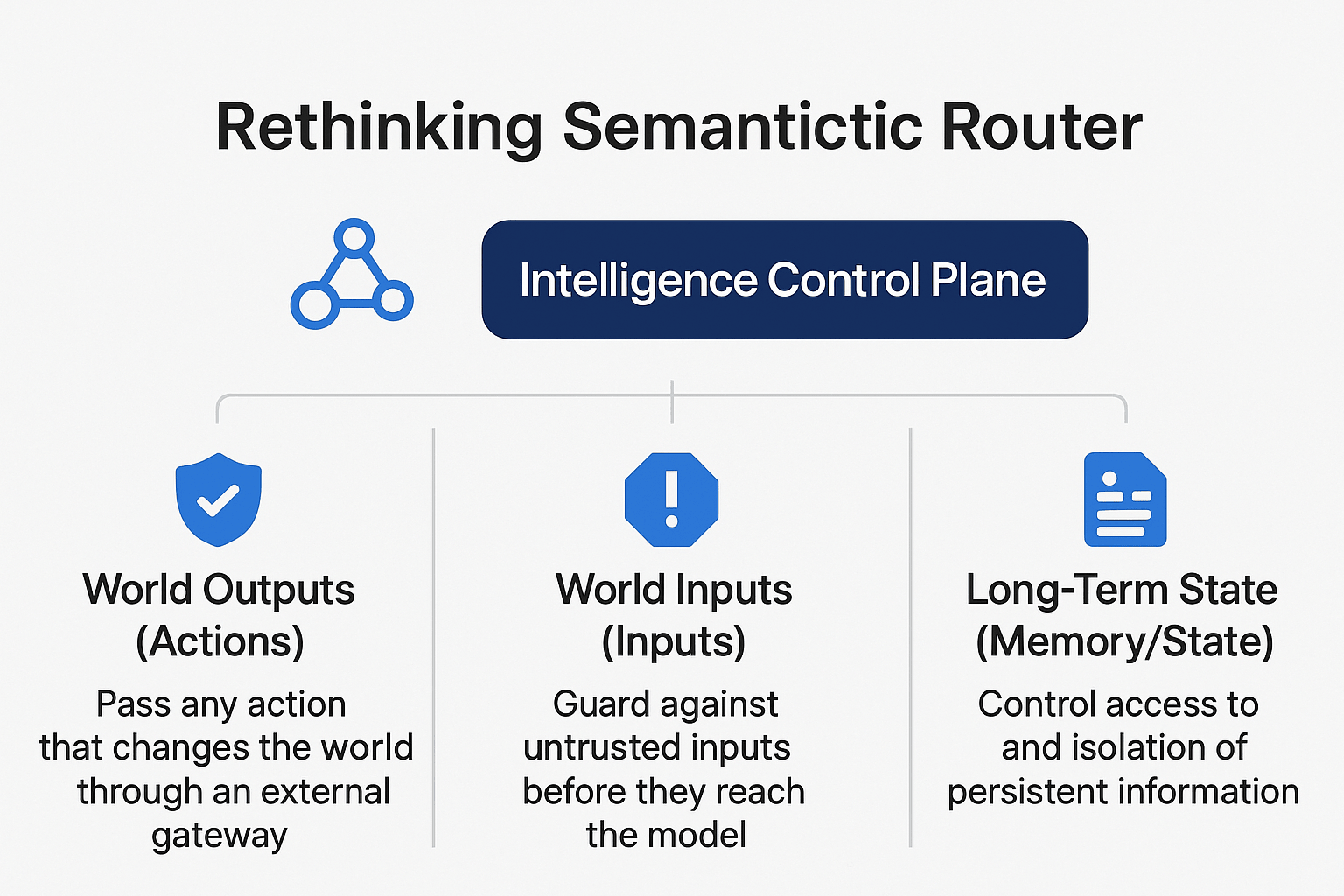
1. World Output (Actions)
The most dangerous capability of powerful models isn’t reasoning—it’s execution. Every action that changes the world (tool calls, database writes, API invocations, configuration changes) must pass through an external checkpoint before execution.
With AMD GPUs, we can run these checkpoints inline at production scale—evaluating risk, enforcing policies, and logging decisions without becoming a bottleneck.
2. World Input (Inputs)
External inputs are untrusted by default. Web pages, retrieval results, uploaded files, and plugin returns can all carry prompt injection, data poisoning, or privilege escalation attempts.
VSR on AMD infrastructure provides border inspection before data reaches the model—running classifiers, sanitizers, and verification checks as a first line of defense, not an afterthought.
3. Long-Term State (Memory/State)
The hardest failures to fix aren’t wrong answers—they’re wrong answers that get written into long-term memory, system state, or automated workflows.
Our collaboration focuses on making state management a first-class concern: who can write, what can be written, how to undo, and how to isolate contamination. AMD’s GPU infrastructure enables us to run continuous verification and rollback mechanisms that keep state trustworthy over time.
The Ultimate Question
When these three lifelines are secured, Semantic Router stops being just a model selector. It becomes the answer to a fundamental question:
How do we transform alignment from a training-time aspiration into a runtime institution?
This is what the AMD × vLLM Semantic Router collaboration is really about: building not just faster routing, but trustworthy, governable AI infrastructure that can scale safely toward AGI-level capabilities.
Long-Term Vision and Ongoing Work
Our collaboration with AMD extends beyond near-term deployment to building the foundation for next-generation AI infrastructure. We’re working on several long-term initiatives:
Training a Next-Generation Router Model on AMD GPUs
As a longer-term goal, we aim to explore training a next-generation router model based on encoder-only on AMD GPUs, optimized for semantic routing, retrieval-augmented generation (RAG), and safety classification.
While recent encoder models (e.g., ModernBERT) show strong performance, they remain limited in context length, multilingual coverage, and alignment with emerging long-context attention techniques. This effort focuses on advancing encoder capabilities using AMD hardware, particularly for long-context, high-throughput representation learning.
The outcome will be an open encoder model designed to integrate with vLLM Semantic Router and modern AI pipelines, strengthening the retrieval and routing layers of AI systems while expanding hardware-diverse training and deployment options for the community and industry.
Community Public Beta on AMD Infrastructure
As part of this collaboration, each major release of vLLM Semantic Router will be accompanied by a public beta environment hosted on AMD-sponsored infrastructure, available free of charge to the community.
These public betas will allow users to:
- Validate new routing, caching, and safety features
- Gain hands-on experience with Semantic Router running on AMD GPUs
- Provide early feedback that helps improve performance, usability, and system design
By lowering the barrier to experimentation and validation, this initiative aims to strengthen the vLLM ecosystem, accelerate real-world adoption, and ensure that new Semantic Router capabilities are shaped by community input before broader production deployment.
AMD GPU-Powered CI/CD and End-to-End Testbed
In the long run, we aim to use AMD GPUs to underpin how VSR as an open-source project is built, validated, and shipped, ensuring VSR works consistently well with AMD GPUs as the project grows.
We are designing a GPU-backed CI/CD and end-to-end testbed where:
- Router SLMs, LLMs, domain models, retrieval, and tools run together on AMD GPU clusters
- Multi-domain, multi-risk-level datasets are replayed as traffic
- Each VSR change runs through an automated evaluation pipeline, including:
- Routing and policy regression tests
- A/B comparisons of new vs. previous strategies
- Stress tests on latency, cost, and scalability
- Focused suites for hallucination mitigation and compliance behavior
The target state is clear:
Every VSR release comes with a reproducible, GPU-driven evaluation report, not just a changelog.
AMD GPUs, in this model, are not only for serving models; they are the verification engine for the routing infrastructure itself.
An AMD-Backed Mixture-of-Models Playground
In parallel, we are planning an online Mixture-of-Models playground powered by AMD GPUs, open to the community and partners.
This playground will allow users to:
- Experiment with different routing strategies and model topologies under real workloads
- Observe, in a visual way, how VSR decides which model to call, when to retrieve, and when to apply additional checks or fallbacks
- Compare quality, latency, and cost trade-offs across configurations
For model vendors, tool builders, and platform providers, this becomes a neutral, AMD GPU-backed test environment to:
- Integrate their components into a MoM stack
- Benchmark under realistic routing and governance constraints
- Showcase capabilities within a transparent, observable system
Why This Collaboration Matters
Through the AMD × vLLM Semantic Router collaboration, we are aiming beyond “does this model run on this GPU”.
The joint ambitions are:
- To define a reference architecture for intelligent, GPU-accelerated routing on AMD platforms, including:
- vLLM-based inference paths,
- ONNX-based lightweight router paths,
- multi-model coordination and safety enforcement.
- To treat routing as trusted infrastructure, supported by:
- GPU-powered CI/CD and end-to-end evaluation,
- hallucination-aware and risk-aware policies,
- online learning and adaptive strategies.
- To provide the ecosystem with a long-lived, AMD GPU–backed MoM playground where ideas, models, and routing policies can be tested and evolved in the open.
In short, this is about co-building trustworthy, evolvable multi-model AI infrastructure—with AMD GPUs as a core execution and validation layer, and vLLM Semantic Router as the intelligent control plane that makes the entire system understandable, governable, and ready for real workloads.
The technical roadmap—hallucination detection, online learning, multi-model orchestration—serves this larger mission. AMD’s hardware provides the execution layer. VSR provides the control plane. Together, we’re building the foundation for AI systems that remain aligned not through hope, but through architecture.
Acknowledgements
We would like to thank the many talented people who have contributed to this collaboration:
- AMD: Andy Luo, Haichen Zhang, and the AMD AIG Teams.
- vLLM SR: Xunzhuo Liu, Huamin Chen, Chen Wang, Yue Zhu, and the vLLM Semantic Router OSS team.
We’re excited to keep refining and expanding our optimizations to unlock even greater capabilities in the weeks and months ahead!
Join Us
Looking for Collaborations! Calling all passionate community developers and researchers: join us in training the next-generation router model on AMD GPUs and building the future of trustworthy AI infrastructure.
Interested? Reach out to us:
- Haichen Zhang: haichzha@amd.com
- Xunzhuo Liu: xunzhuo@vllm-semantic-router.ai
Resources:
Join the discussion: Share your use cases and feedback in #semantic-router channel on vLLM Slack