GPT-OSS Performance Optimizations on NVIDIA Blackwell: Pushing the Pareto Frontier
TL;DR: In collaboration with the open-source community, vLLM + NVIDIA has achieved significant performance milestones on the gpt-oss-120b model running on NVIDIA’s Blackwell GPUs. Through deep integration with FlashInfer, novel kernel fusions via torch.compile, and various inference runtime features, we have set a new record for the model’s performance Pareto frontier —simultaneously optimizing for maximum throughput (+38%) and best interactivity (+13%).
This post details the engineering journey, technical breakthroughs, and instructions to reproduce the results. Continuous benchmarks are also available on SemiAnalysis Inference MAX and vLLM Recipes.
Table of Contents
- Introduction
- FlashInfer + torch.compile
- Runtime Improvements
- Deployment Recipes
- Results
- Next Steps
- Acknowledgements
Introduction
Optimizing for a single metric—like maximum throughput or single-batch latency—is often insufficient for real-world deployments. Different use cases require different latency constraints and request concurrency. As a result, the real challenge lies in optimizing the Pareto frontier: the curve that represents the best possible trade-off between Tokens Per Second (TPS) per GPU (TCO, total cost of ownership) and TPS per User (interactivity). Pushing this curve upwards and to the right means delivering faster generation for individual users while allowing more users to share the hardware. SemiAnalysis InferenceMAX has identified this critical need to measure, report and improve performance data for such LLM inference workloads on modern GPUs.
One of the key use-cases is serving OpenAI’s gpt-oss-120b model, a natively 4-bit quantized (MXFP4) Mixture-of-Experts (MoE) LLM. It has achieved SoTA model accuracy for its size along with strong agentic capabilities. At the recent SemiAnalysis InferenceMAX showcase, vLLM demonstrated its capability to handle this workload efficiently on NVIDIA’s latest Blackwell (B200/GB200) architecture.
The heart of the optimizations is hardware-software co-design. The NVIDIA B200/GB200 GPUs introduce powerful features like native FP4 TensorCores and 192GB HBM per GPU, which are critical for serving large MoE models like gpt-oss. To leverage this hardware fully, vLLM and NVIDIA teams have integrated with FlashInfer and adopted a rigorous optimization strategy focusing on kernel fusion, communication overhead reduction, and host-device overlapping.
FlashInfer Integration and torch.compile based fusion
To maximize the utilization of Blackwell’s tensor cores, vLLM leverages FlashInfer as its primary kernel backend for attention, MoE, and other compute-intensive and fused operations.
1. Key Compute Kernel Integration:
- MoE Backends: We enabled both
trtllm-gen(PR23819) andcutlass(PR23696) backends for MoE operations with FlashInfer. This allows vLLM to select the most performant kernel for expert routing and computation. In addition to providing the best-performing kernels for LLMs, FlashInfer also includes jit-in-time compilation, auto-tuning, and kernel caching, which greatly improves the user experience for any developer with high-performance kernel needs. - FP8 KV-Cache: Storing kv-cache in FP8 precision allows the engine to serve more concurrent requests with the same kv-cache budget. Moreover, carrying out some of the attention operations in FP8 precision also reduces the compute/memory complexity of the attention operation. To achieve the best performance for this use case, vLLM has integrated FlashInfer’s optimized attention kernels in PR25674.
2. Graph Fusions via torch.compile A significant portion of our optimization effort focused on kernel fusion to reduce memory access and kernel launch overhead. Instead of hard-coded fusion optimizations, vLLM has built an extensive infrastructure based on torch.compile to conduct kernel fusion automatically. This approach not only improves performance, but significantly reduces the effort to enable, generalize, and maintain such improvements.
- AR + Norm Fusion: We implemented the fusion of AllReduce (AR) and RMSNorm operations. This is particularly important for tensor-parallel (TP) deployments, where communication overhead can become a bottleneck, details please see PR20691.
- Pad + Quant & Finalize + Slice: We are actively rolling out the fusion passes, PR30647 for padding/quantization and finalize/slice operations to further streamline the MoE execution path, with an expected 6% performance gain.
As we identify and develop new fused operations, the team will continue to deliver automatic performance gains via this infrastructure.
Runtime Improvements
On next-generation hardware like Blackwell, the GPU is so fast that the CPU (host) often becomes the bottleneck, struggling to dispatch kernels quickly enough to keep the GPU busy. In addition, prepare\_batch, request scheduling and sampling logic also require heavy CPU side logic. This “host overhead” manifests as gaps between kernel executions, degrading performance and overall GPU utilization.
To address this, we implemented both Async Scheduling and Stream Interval to vLLM that effectively eliminate host-side overhead.
- Mechanism: This scheduler decouples the CPU’s request scheduling from the GPU’s execution. By allowing the CPU to prepare the next batch of requests while the GPU is still processing the current batch, we effectively hide the host overhead.
- Impact: This optimization is crucial for the
gpt-ossmodel, particularly in both high-throughput and min-latency scenarios. On more capable GPUs (H200s, B200s, GB200s), you can expect around a 10% performance gain. - Configuration: This has been turned on by default in recent vLLM releases.
- Mechanism: This feature reduces the granularity of network responses by buffering generated tokens before sending them to the client. Instead of triggering a network call for every single token, the engine waits until a specified buffer size (the “interval”) is reached. Crucially, the implementation preserves responsiveness by ensuring the first token is always sent immediately (keeping Time-To-First-Token low), while subsequent tokens are batched.
- Impact: By reducing the frequency of HTTP/gRPC response dispatching, this significantly lowers the CPU overhead associated with network I/O and serialization. In high-concurrency benchmarks (e.g.,
gpt-oss-20bwith 1024 concurrent requests), this optimization relieved output queue bottlenecks, resulting in a 57% end-to-end performance gain and improved Time Per Output Token (TPOT). - Configuration: Users can configure this behavior using the
--stream-interval <num_tokens>argument. The default value is1(standard streaming), but increasing this value (e.g., to10) is highly effective for reducing host overhead in high-throughput deployments.
Deployment Recipes
Most of the optimizations are already applied by default on the latest vLLM release. In addition, to reproduce the optimized performance for gpt-oss on Blackwell GPUs (B200/GB200), we recommend the following configurations in your vLLM deployment recipes. They can also be found under vLLM Recipes page.
Recommended Configuration Flags:
- Graph Capture:
--cuda-graph-capture-size 2048
- Scheduling:
--api-server-count 20or--stream-interval 20: This helps decouple the HTTP API server overhead from the inference engine, stabilizing performance at high concurrency.
- MoE Backend:
- Explicitly enable the optimized Cutlass backend for FP8/FP4 MoE to ensure maximum throughput:
VLLM_USE_FLASHINFER_MOE_MXFP4_MXFP8=1.
- Explicitly enable the optimized Cutlass backend for FP8/FP4 MoE to ensure maximum throughput:
Results
The combined effect of the optimizations has resulted in a significant uptick of performance since the launch of InferenceMax. Notably, a 38% performance increase at max-throughput, and 13% performance increase at min-latency
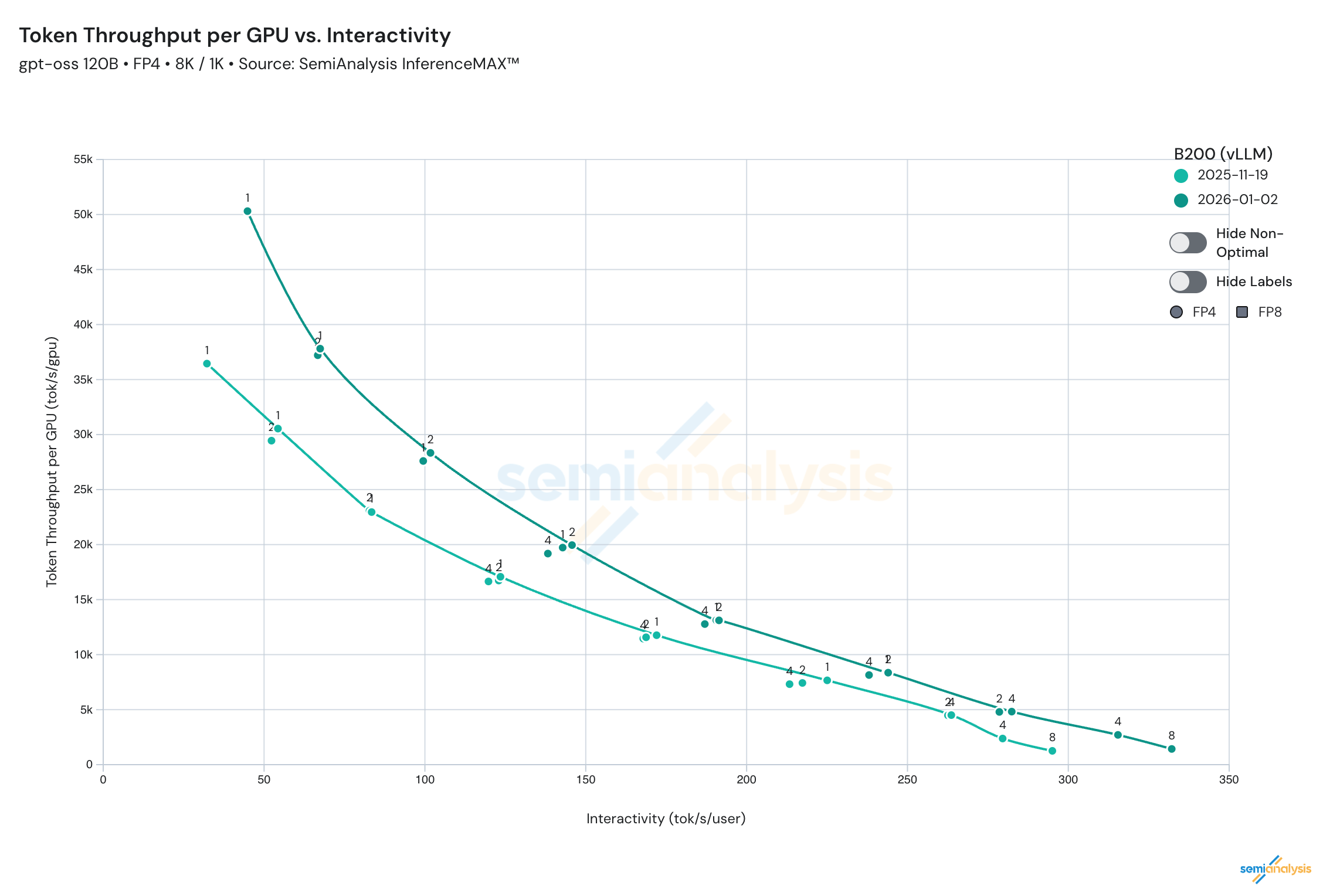
Such improvements are not just for a single use-case, but rather across the entire Pareto curve to benefit the vLLM community at large.
Next steps
Our work on gpt-oss is ongoing. Here is a look at the active engineering tracks to further push the Pareto frontier. The list can also be found in Issue 30758.
Disaggregation
By separating the Prefill stage and the Decode stage on to different GPUs, we can potentially achieve better throughput per GPU. We are currently experimenting with this setup and find the correct configs that achieve better performance.
Data+Expert parallel performance
Our projection shows that using DEP2 (Attention DP + MoE EP on 2 GPUs) can potentially achieve higher throughput per GPU compared to TP1 and TP2 at the same latency (TPS/user). However, currently the DEP2 performance is worse than TP1/TP2 mainly due to the MoE kernel selection issue. We are actively working on this to resolve it.
Minimum latency performance
We have identified a few performance optimization opportunities for min-latency scenario, or TP8 concurrency 8 more specifically:
- RoPE+Q+Cache fusion: Kernel is available in FlashInfer. Integration in vLLM is in progress.
- The router gemm and fc_qkv/fc_o_proj gemms: we can use specialized tiny gemm kernels with better performance and PDL support.
Acknowledgements
We would like to give thanks to the many talented people in the vLLM community who worked together as a part of this effort:
- Red Hat: Michael Goin, Alexander Matveev, Lucas Wilkinson, Luka Govedič, Wentao Ye, Ilia Markov, Matt Bonanni, Varun Sundar Rabindranath, Bill Nell, Tyler Michael Smith, Robert Shaw
- NVIDIA: Po-Han Huang, Pavani Majety, Shu Wang, Elvis Chen, Zihao Ye, Duncan Moss, Kaixi Hou, Siyuan Fu, Benjamin Chislett, Xin Li, Vadim Gimpelson, Minseok Lee, Amir Samani, Elfie Guo, Lee Nau, Kushan Ahmadian, Grace Ho, Pen Chun Li
- vLLM: Chen Zhang, Yongye Zhu, Bowen Wang, Kaichao You, Simon Mo, Woosuk Kwon, Zhuohan Li
- Meta: Yang Chen, Xiaozhu Meng, Boyuan Feng, Lu Fang