Driving vLLM WideEP and Large-Scale Serving Toward Maturity on Blackwell (Part I)
Introduction
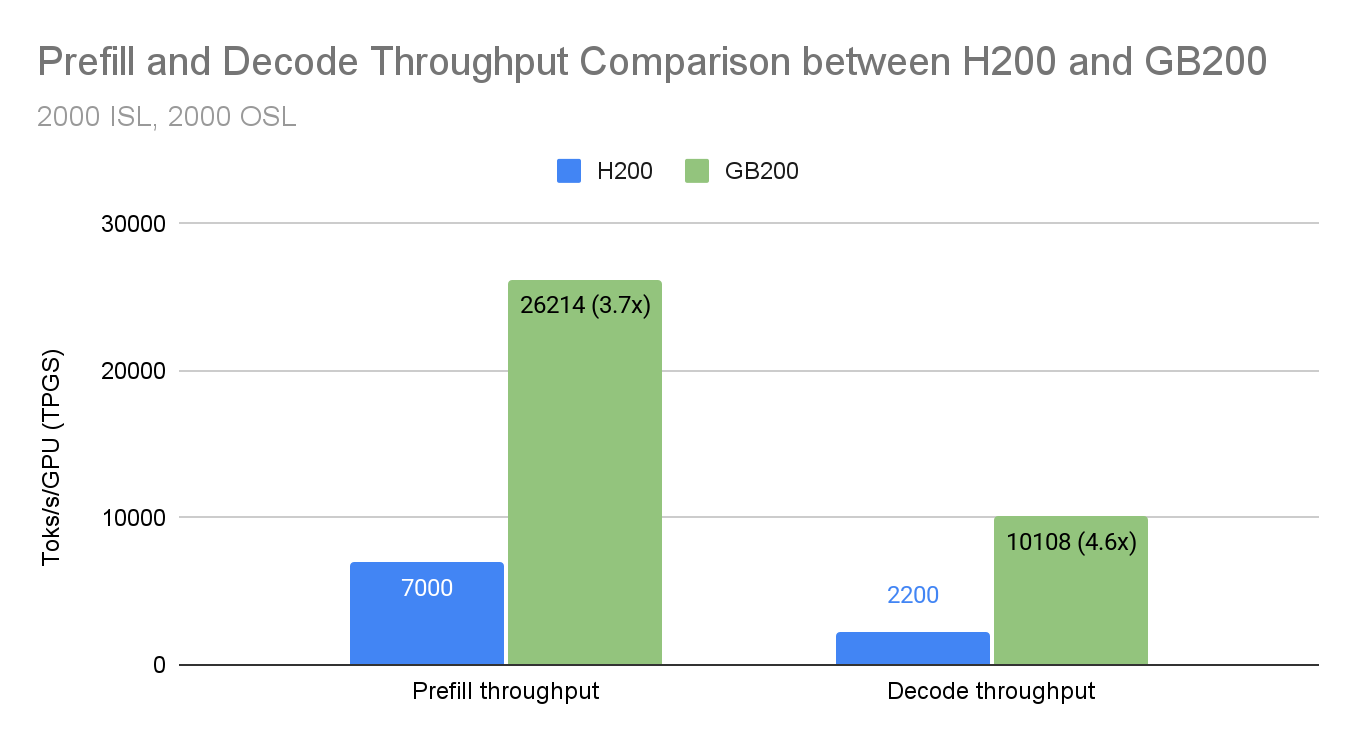
Building on our previous work achieving 2.2k tok/s/H200 decode throughput with wide-EP, the vLLM team has continued performance optimization efforts targeting NVIDIA’s GB200 platform. This blog details the key optimizations that enable vLLM to achieve 26.2K prefill TPGS (tokens per GPU second) and 10.1K decode TPGS on GB200 using workload of 2K input tokens and 2K output tokens for DeepSeek-style MoE models including DeepSeek R1/V3/V3.1. And the above numbers are collected through a deployment with 4 prefill instances (each with 2 GB200) and 1 decode instance (with 8 GB200), all utilizing a combination of data-parallelism (DP) and expert-parallelism (EP).
These gains are driven by a combination of new optimizations:
New Optimizations:
- Lower-precision operations (NVFP4 GEMM, FP8 GEMM, NVFP4 MoE Dispatch)
- Kernel fusion (RoPE+Quant+Q write, RoPE+Quant, Concat K)
- Scaling down prefill via weight offloading
- Minimized chunking overheads
Previously Discussed Features:
- Async scheduling
- Prefill/decode disaggregated serving
The combination of GB200’s increased compute capability and these targeted optimizations results in a significant throughput improvement over H200 deployments.
Results
The following benchmarks compare vLLM performance on GB200 versus H200 for DeepSeek-V3/R1 workloads using a fixed workload of 2K input tokens and 2K output tokens. Detailed deployment setup can be found in the following table.
| Deployment setup | H200 | GB200 |
|---|---|---|
| Prefill | 16 GPUs | 8 GPUs (4 instances x 2 GPUs) |
| Decode | 32 GPUs | 8 GPUs (1 instance x 8 GPUs) |
The GB200’s increased memory bandwidth (8 TB/s vs 4.8 TB/s), higher compute throughput through FP4, and NVLink-C2C interconnect between CPU and GPU all contribute to these gains. We maximized this potential by applying the optimizations detailed below.
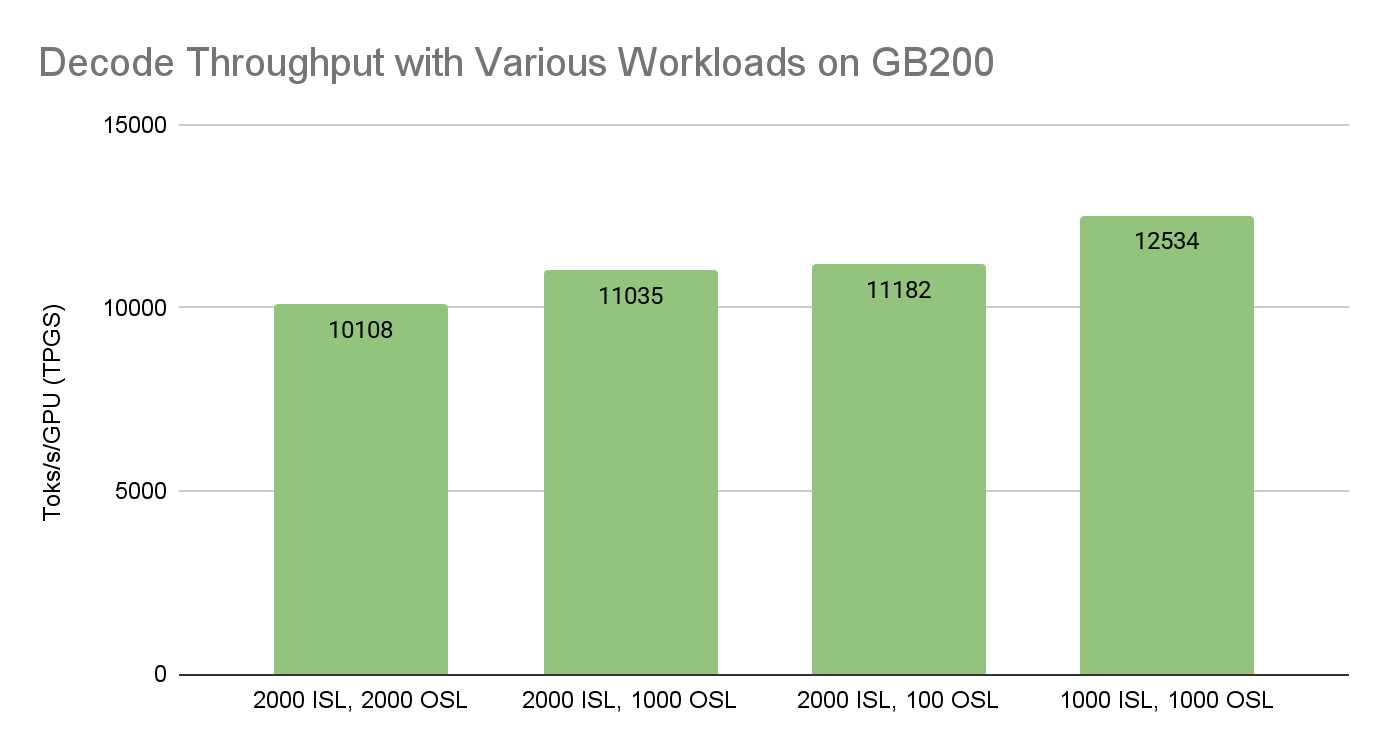
We also benchmarked the DeepSeek-V3/R1 decode throughput on GB200 for a range of standard workloads, maintaining the same parallelism setup while varying the decode batch size that fully utilizates GPU memory.
Instructions for reproducing all benchmark results can be found here.
Key Optimizations
Lower-Precision Operations
GB200 introduces significantly higher throughput for FP4 and FP8 operations compared to H200. vLLM leverages these capabilities through several precision optimizations.
NVFP4 GEMM (MoE GEMMs, O-proj)
DeepSeek-V3/R1 models can be quantized to FP4 precision for the MoE expert weights and output projection layers. vLLM integrates FlashInfer’s TRTLLM-Gen GEMM kernels, which are specifically optimized for GB200’s FP4 tensor cores.
The FP4 checkpoint format stores weights in a packed 4-bit representation with per-group scaling factors. At runtime, the TRTLLM-Gen kernels dequantize on-the-fly within the tensor cores, achieving near-native FP4 throughput while maintaining model quality.
Key implementation details:
- FP4 weights with FP8 or FP16 scales stored in a packed format
- FlashInfer TRTLLM-Gen kernels optimized for GB200 tensor core scheduling
- Applied to MoE expert GEMMs and attention output projection (O-proj)
FP8 GEMM for MLA
For DeepSeek’s Multi-head Latent Attention (MLA), the query up-projection (from latent space to full query dimensions) benefits from FP8 quantization. Unlike the MoE layers where FP4 provides the best throughput/accuracy tradeoff, the attention projections are more sensitive to quantization and the accuracy benefits from FP8’s higher precision.
vLLM uses optimized FP8 GEMM kernels for these projections, achieving significant speedup over FP16 while maintaining attention quality.
NVFP4 MoE Dispatch
Beyond the expert GEMMs themselves, the MoE dispatch operation—which routes tokens to their assigned experts—can also benefit from lower precision. vLLM implements NVFP4 dispatch, quantizing token activations to FP4 before the all-to-all communication.
This reduces the all-to-all communication volume by 4x compared to FP16 dispatch, significantly decreasing inter-GPU communication latency in EP deployments. The quantization overhead is amortized across the communication savings, resulting in net throughput gains.
Kernel Fusion
There are several kernel fusion strategies that reduce memory bandwidth consumption and kernel launch overhead by combining multiple operations into single GPU kernels.
RoPE + Quant + Q Write (Decode)
During decode, the query projection requires:
- RoPE (Rotary Position Embedding) application
- Quantization for the subsequent GEMM
- Writing to the query buffer
vLLM fuses these three operations into a single kernel, eliminating two intermediate memory round-trips.
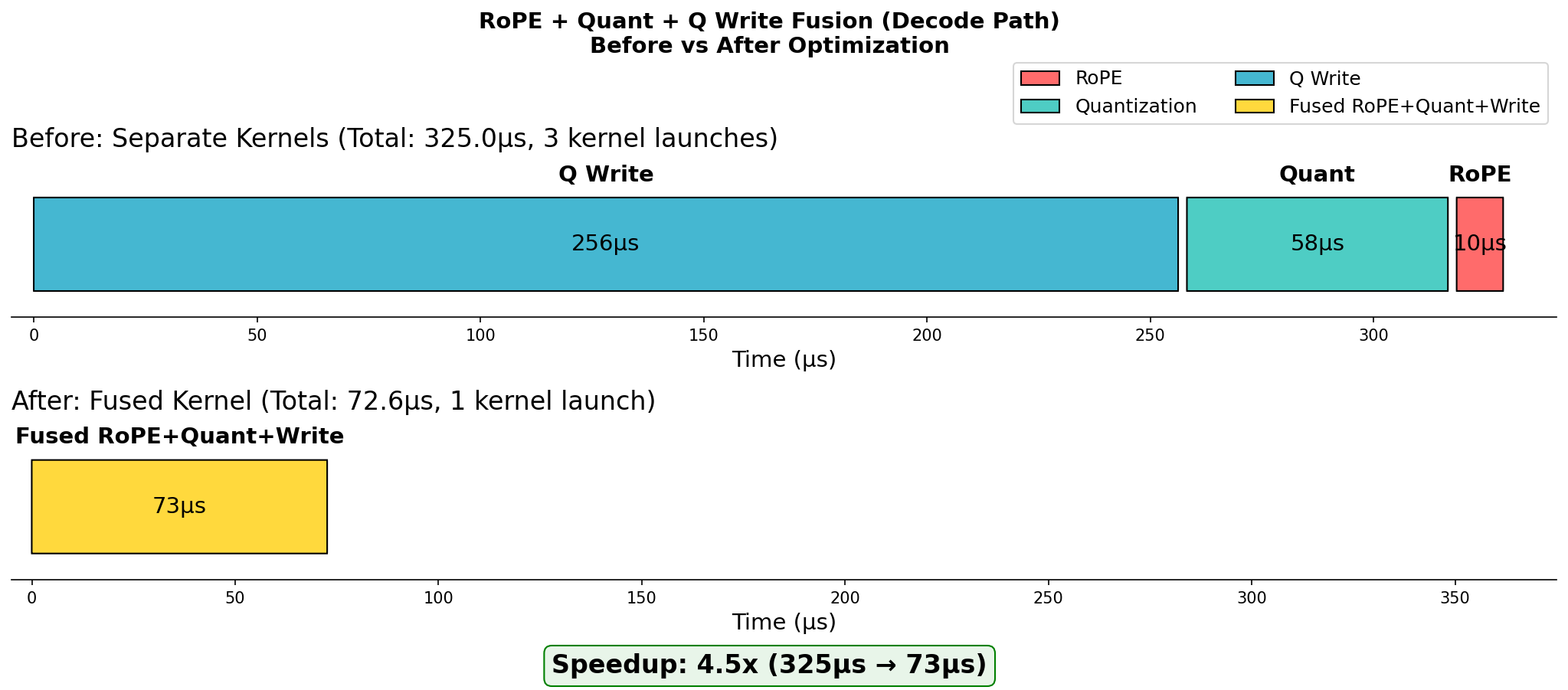
RoPE+Quant+Q Write Fusion in Decode
RoPE + Quant (Prefill)
Similarly for prefill, RoPE application and quantization are fused. The prefill path handles larger token batches, making the memory bandwidth savings from fusion even more impactful.
Concat K Optimization
For MLA key projections, vLLM implements an optimized concatenation operation using FlashInfer’s concat_mla_k kernel. In DeepSeek’s MLA architecture, the key tensor is composed of two parts: the non-positional embedding part (k_nope, per-head) and the rotary positional embedding part (k_rope, shared across all heads). These must be concatenated to form the full key tensor.
The naive approach requires copying k_nope and broadcasting k_rope across all 128 heads, resulting in significant memory bandwidth consumption. FlashInfer’s concat_mla_k kernel implements several optimizations:
- Warp-based processing: Each warp handles one (token, head_chunk) pair, processing 16 heads at a time
- Vectorized memory access: Uses 8-byte vector loads for nope data and 4-byte loads for rope data, maximizing memory throughput
- Software pipelining with L2 prefetching: Prefetches the next row while processing the current row, hiding memory latency
- Register reuse for rope values: Since rope is shared across all heads, it is loaded once into registers and written to all 16 heads in the chunk, avoiding redundant memory loads
Scaling Down Prefill
Why Scaling Down Makes Sense
When considering GPU count for throughput-oriented inference serving, we typically scale out either to fit the model or to shard memory (experts, context) to increase batch size. However, for prefill workloads that are already compute-bounded, reducing GPU count can actually improve throughput by reducing communication overhead.
Our microbenchmarks show that MLA backend throughput performance starts plateauing when batch size increases from 16K to 64K tokens. Beyond 64K tokens, MoE throughput gains are also negligible. This means we can saturate compute utilization with a batch size that fits in a 2-GPU serving setup.
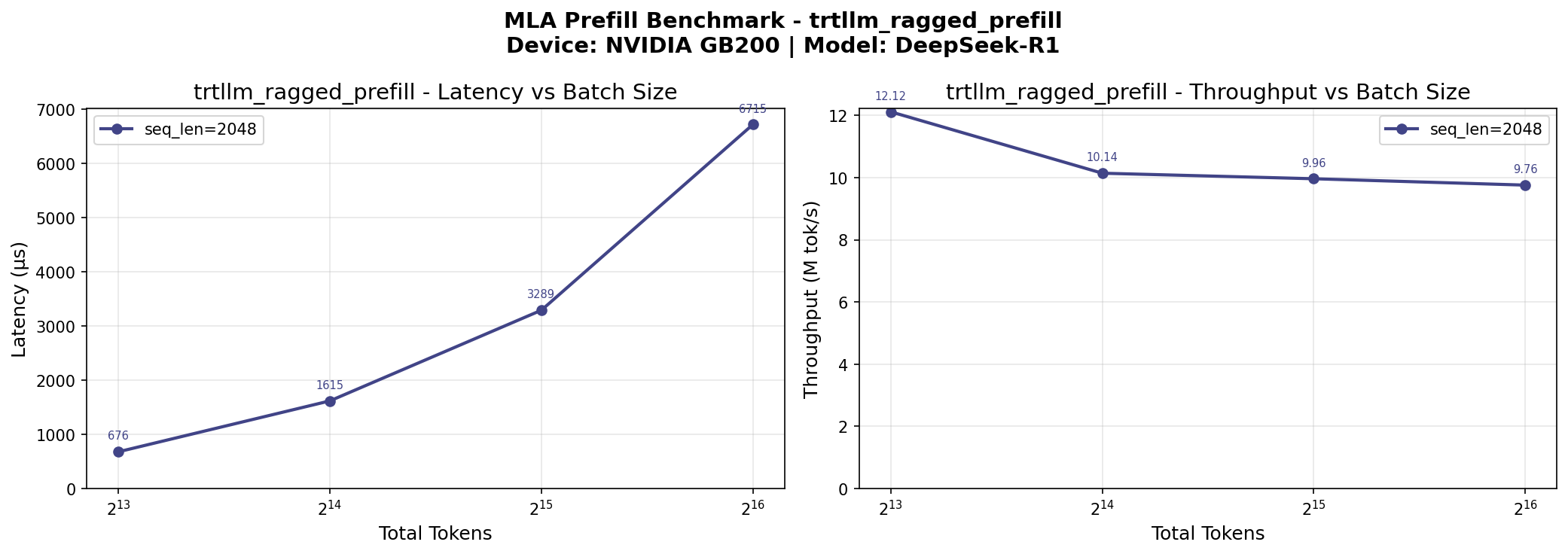
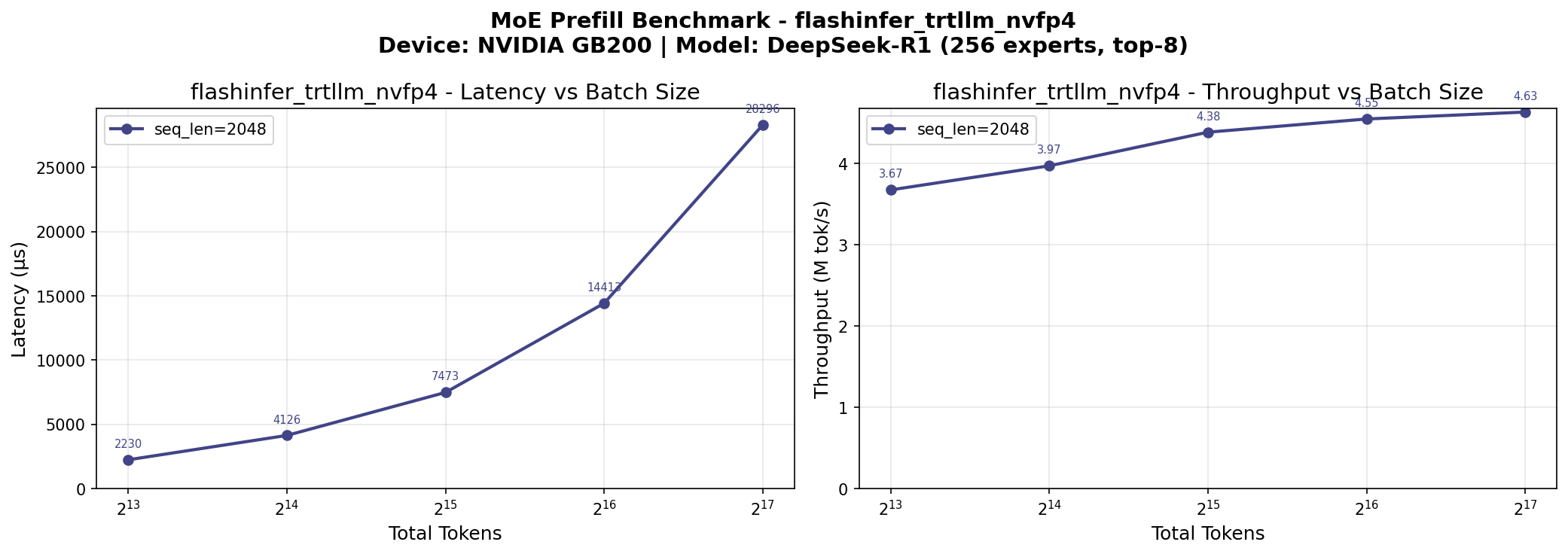
MLA and MoE throughput plateau at ~64K batch size
By reducing GPU count from 4 to 2, we halve the NCCL collectives (all_gather and reduce_scatter) for EP communication, significantly reducing communication overhead.
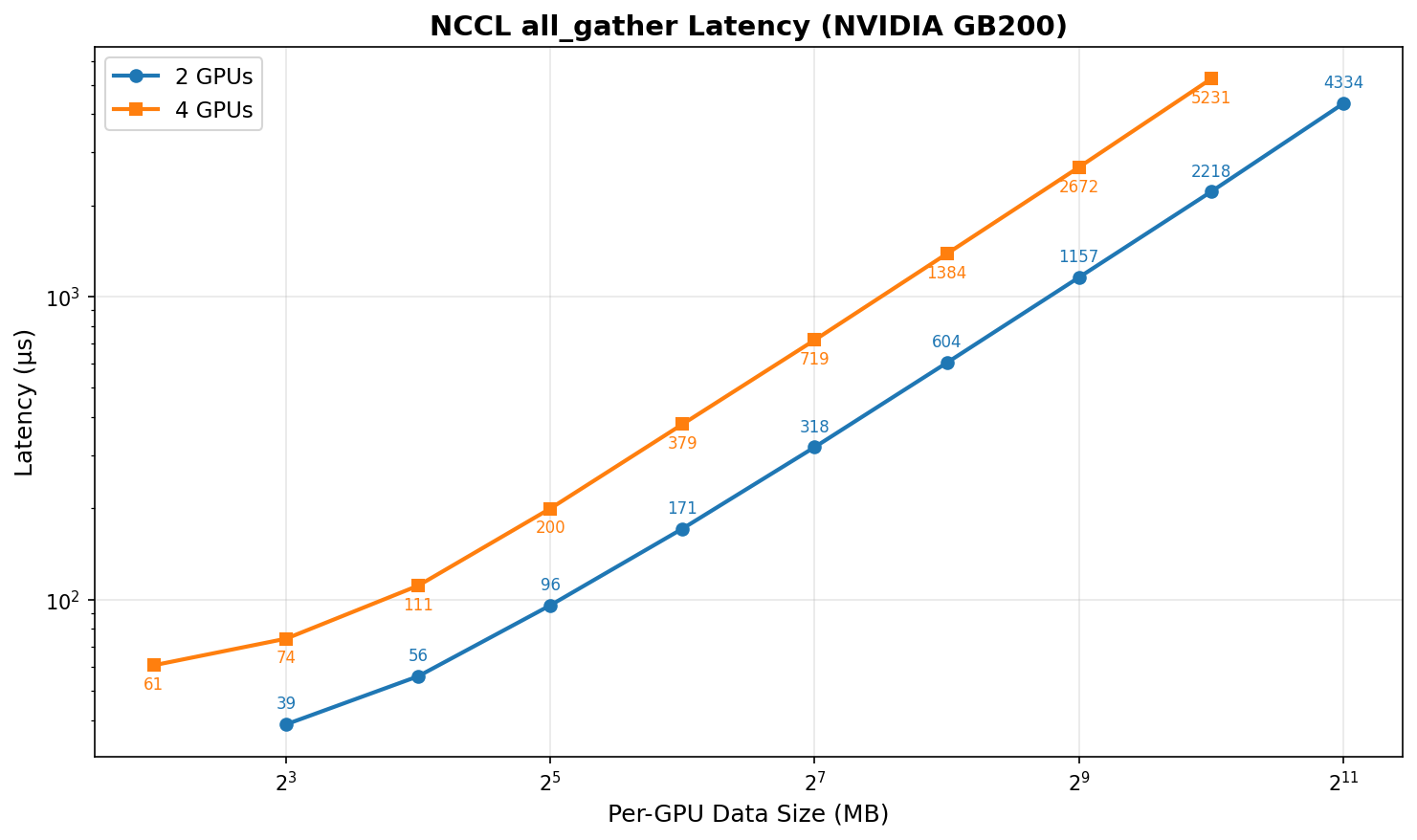
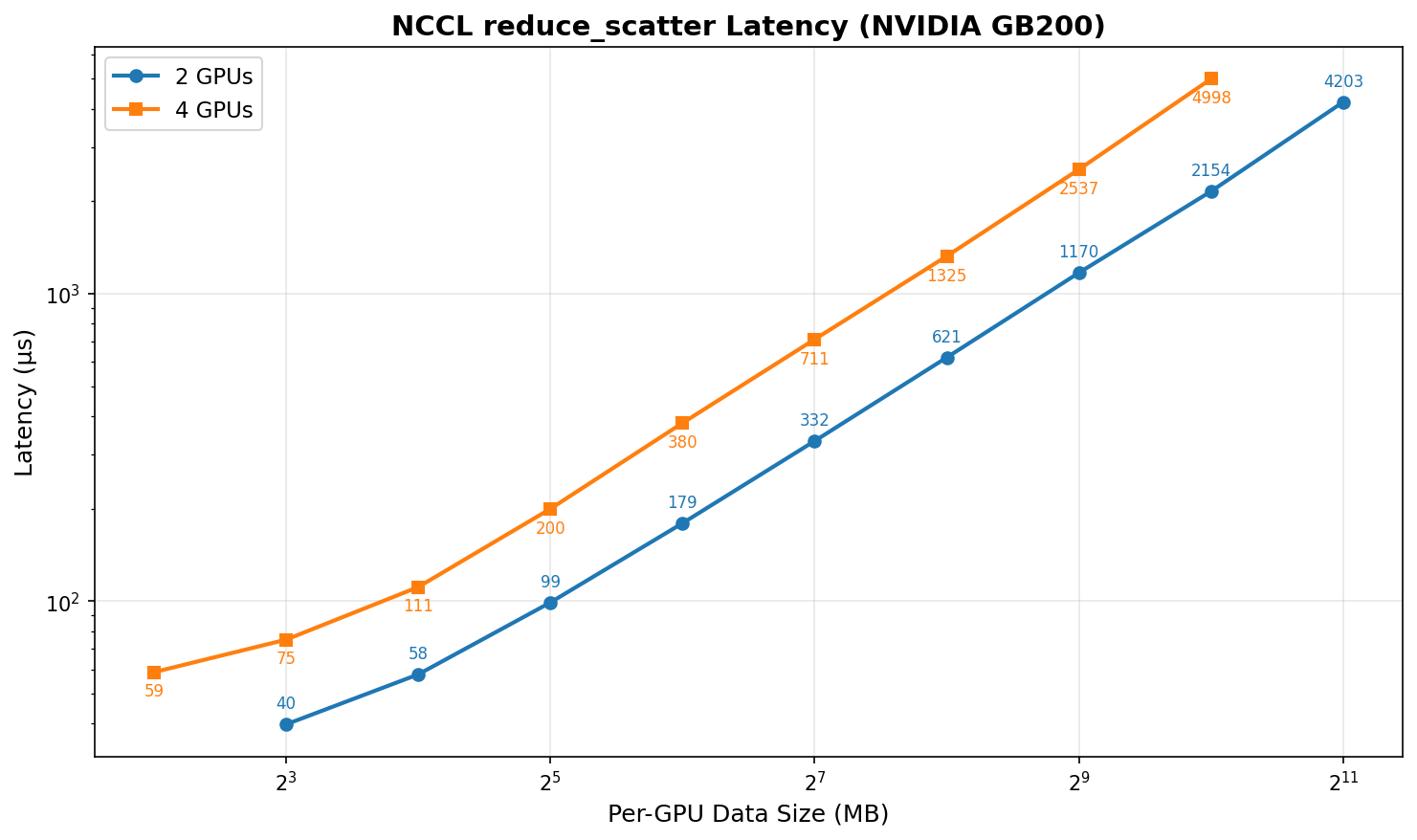
Reducing EP degree halves communication overhead
Weight Offloading v2
To reduce GPU memory footprint while maintaining performance, vLLM implements weight offloading v2 with asynchronous prefetching. This v2 implementation was inspired by the offloading approach in SGLang prefill and now adapted for additional compatibility with torch.compile and CUDA graph within vLLM.
In vLLM weight offloading v1, offloaded weights stayed on CPU and were accessed via Unified Virtual Addressing (UVA), which incurs slow PCIe transfer delays. This was intended as a last resort for running models with limited GPU resources.
Weight offloading v2 takes a different approach: it explicitly copies (onloads) weights to GPU in advance. The key innovation is onloading the weights of the next layer asynchronously on a separate CUDA stream. By carefully overlapping weight onloading with kernel execution, the onloading delay can be completely hidden.
Users configure offloading via group-based selection:
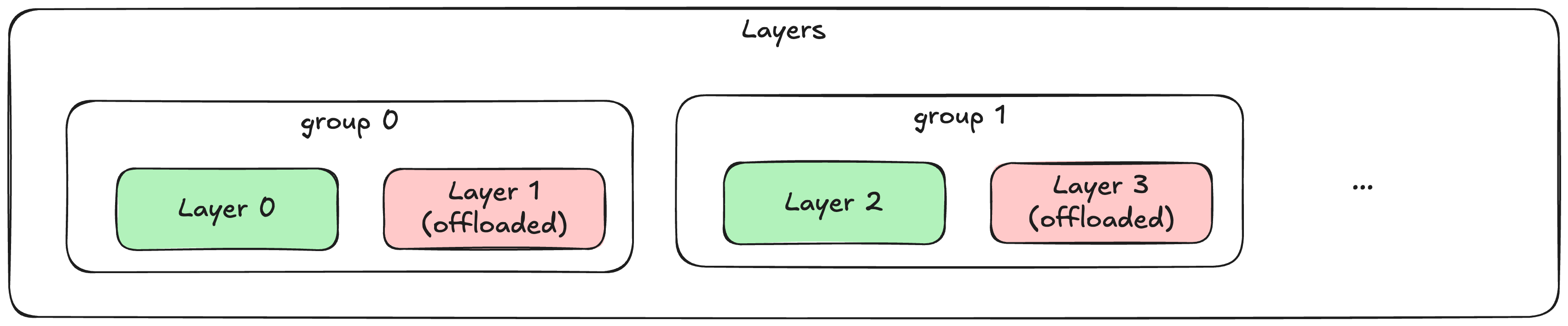
group_size: Group every N layers togethernum_in_group: Offload this many layers per group (last N of each group)prefetch_step: Number of layers to prefetch ahead
For DeepSeek-R1 prefill serving, we offload one of every two MoE GEMM weights, achieving significant memory savings while maintaining full throughput.
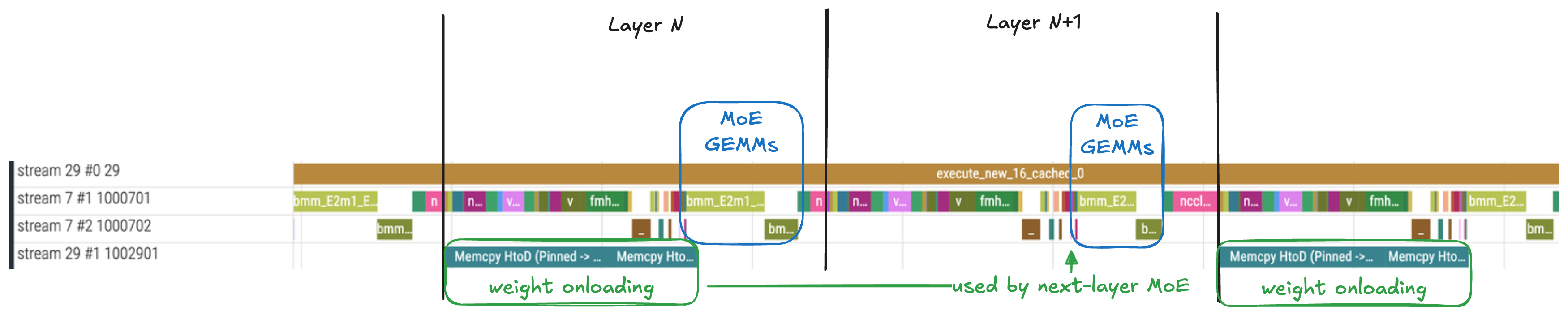
Trace showing weight onload overlapping with layer execution
GB200’s NVLink-C2C connection between CPU and GPU makes weight offloading v2 particularly effective, as the loading latency is minimized compared to PCIe-based systems.
Minimize Chunking Overheads
Large batch processing in MoE models requires chunking to fit within GPU memory constraints. However, smaller chunks introduce overhead from repeated kernel launches and synchronization, creating GPU bubbles. vLLM provides chunk size configuration options to maximize throughput while staying within memory limits.
MoE DP Chunk
When using Data Parallel with Expert Parallel (DP+EP), tokens are dispatched from each DP rank in coordinated chunks. The VLLM_ENABLE_MOE_DP_CHUNK flag (enabled by default) enables this chunking behavior.
Larger chunk sizes reduce GPU bubbles by amortizing dispatch/combine overhead across more tokens. The chunk size is controlled by VLLM_MOE_DP_CHUNK_SIZE (default: 256 tokens). Increasing this value improves throughput by reducing synchronization frequency.
For GB200, we disable MoE DP chunking (VLLM_ENABLE_MOE_DP_CHUNK=0) for prefill and set VLLM_MOE_DP_CHUNK_SIZE to match the batch size for decode.
MoE Activation Chunk
For large prefill batches, vLLM chunks activation tensors to process subsets of tokens through the MoE layers. The VLLM_ENABLE_FUSED_MOE_ACTIVATION_CHUNKING flag controls this behavior (enabled by default).
Larger chunk sizes improve throughput by reducing launch overhead and providing sufficient work to fully utilize GPU compute. The chunk size is controlled by VLLM_FUSED_MOE_CHUNK_SIZE (default: 16K tokens). The optimal setting maximizes chunk size within available GPU memory.
For GB200, we disable activation chunking (VLLM_ENABLE_FUSED_MOE_ACTIVATION_CHUNKING=0) to maximize throughput, as the larger memory capacity accommodates full batches without chunking.
Output Processing Chunk
In the V1 engine’s async serving path, output processing (logit computation, sampling, response generation) is chunked. The VLLM_V1_OUTPUT_PROC_CHUNK_SIZE controls the number of outputs processed per iteration (default: 128).
Larger chunk sizes improve overall throughput by reducing per-chunk overhead. However, for streaming workloads, very large chunks may increase inter-message latency variance. For throughput-optimized decode on GB200, we set the chunk size to 2048.
Future Work
The vLLM team is actively working on the following improvements for GB200 deployments:
- Improving load balancedness and scaling up EP: Extending expert load balancing to handle larger EP degrees and more dynamic workloads, with improved rebalancing algorithms.
- Optimizing MoE dispatch latency: Further reducing the latency of all-to-all dispatch operations through kernel optimizations and communication scheduling.
- Hiding communication latency via compute-communication overlap: Achieving higher GPU utilization in communication-bound scenarios through more aggressive overlapping strategies.
- Expanding WideEP and Large-Scale Serving on GB300: By utilizing GB300’s superior HBM and compute capabilities, we aim to further our WideEP and large-scale serving work, targeting higher TPGS with a reduced host footprint.
For the most up-to-date reference, see roadmap.vllm.ai.
Summary
- vLLM achieves 26.2K prefill TPGS and 10.1K decode TPGS for DeepSeek-style MoE models, representing 3-5x improvement over H200.
- Lower-precision operations (NVFP4 GEMM, FP8 GEMM, NVFP4 dispatch) leverage GB200’s enhanced tensor core capabilities.
- Kernel fusion reduces memory bandwidth pressure and kernel launch overhead.
- Scaling down prefill via weight offloading v2 reduces EP communication overhead while maintaining compute saturation.
- Chunking optimizations controlled via environment variables minimize overhead for large batch processing.
Team
- Meta: Ming Yang, Xiaozhu Meng, Pengchao Wang, Lucia (Lu) Fang, Bangsheng Tang, Yan Cui, Hongyi Jia, Jinghui Zhang, Zebing Lin, Jason Park, Yejin Lee, Jaewon Lee, Bradley Davis, Jingyi Yang, Adi Gangidi, Ayush Goel, Charlotte (Ye) Qi, Stephen Chen, Raj Ganapathy, Akshay Hegde, Lu Fang
- NVIDIA: Duncan Moss, Cyrus Chang, Andrew Briand, Siyuan Fu, Hanjie Qiu, Jason Li, Pavani Majety, Xin Li, Chirayu Garg, Abhinav Singh, Minseok Lee