DeepSeek-V3.2 on GB300: Performance Breakthrough
Summary
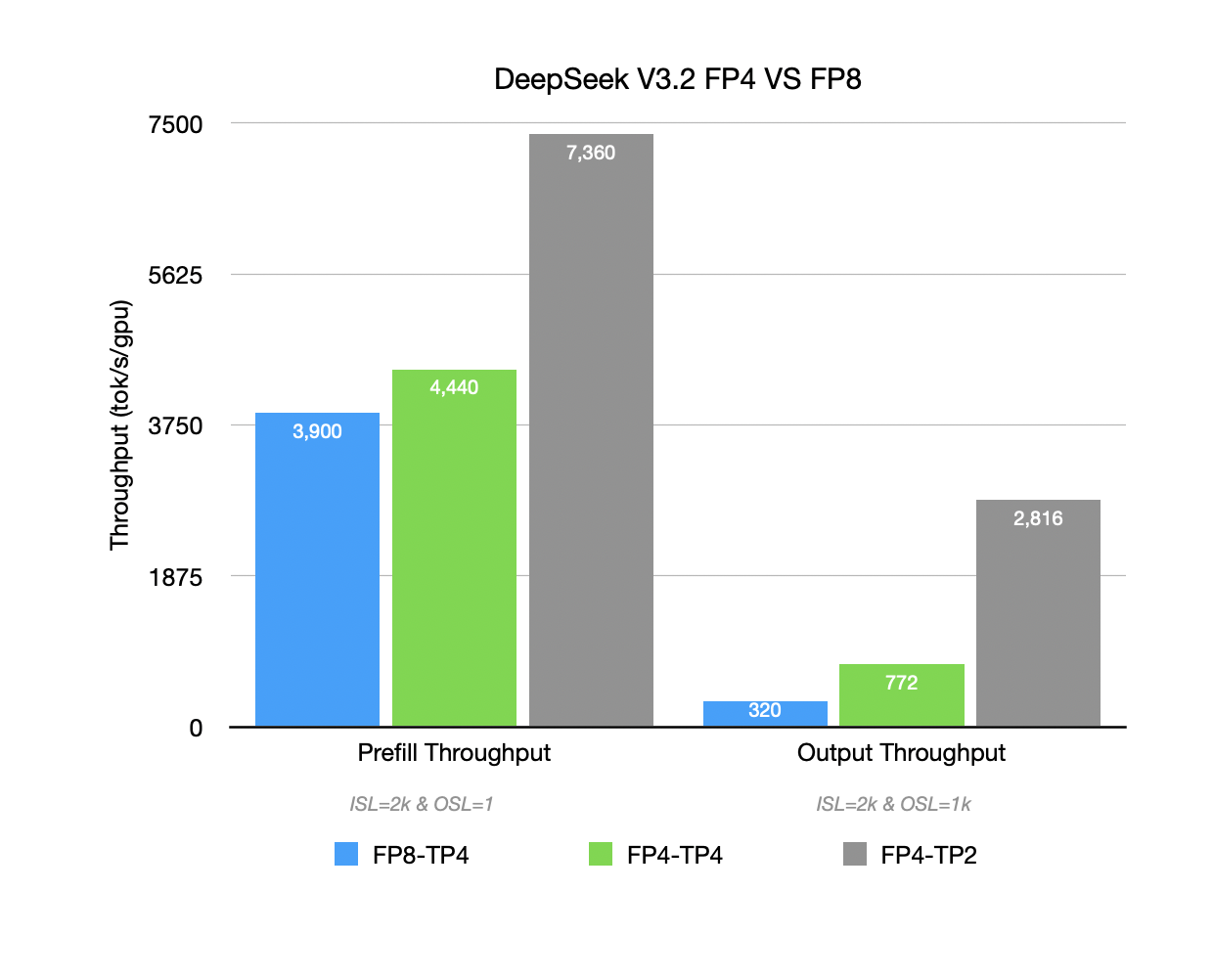
DeepSeek-V3.2 (NVFP4 + TP2)has been successfully and smoothly run on GB300 (SM103 - Blackwell Ultra). Leveraging FP4 quantization, it achieves a single-GPU throughput of 7360 TGS (tokens / GPU / second) in a prefill-only scenario. In a mixed-context scenario (ISL=2k,OSL=1k), the output throughput is 2816 TGS.
However, compared to DeepSeek-R1, DeepSeek-V3.2 in vLLM still has significant room for improvement in inference performance.
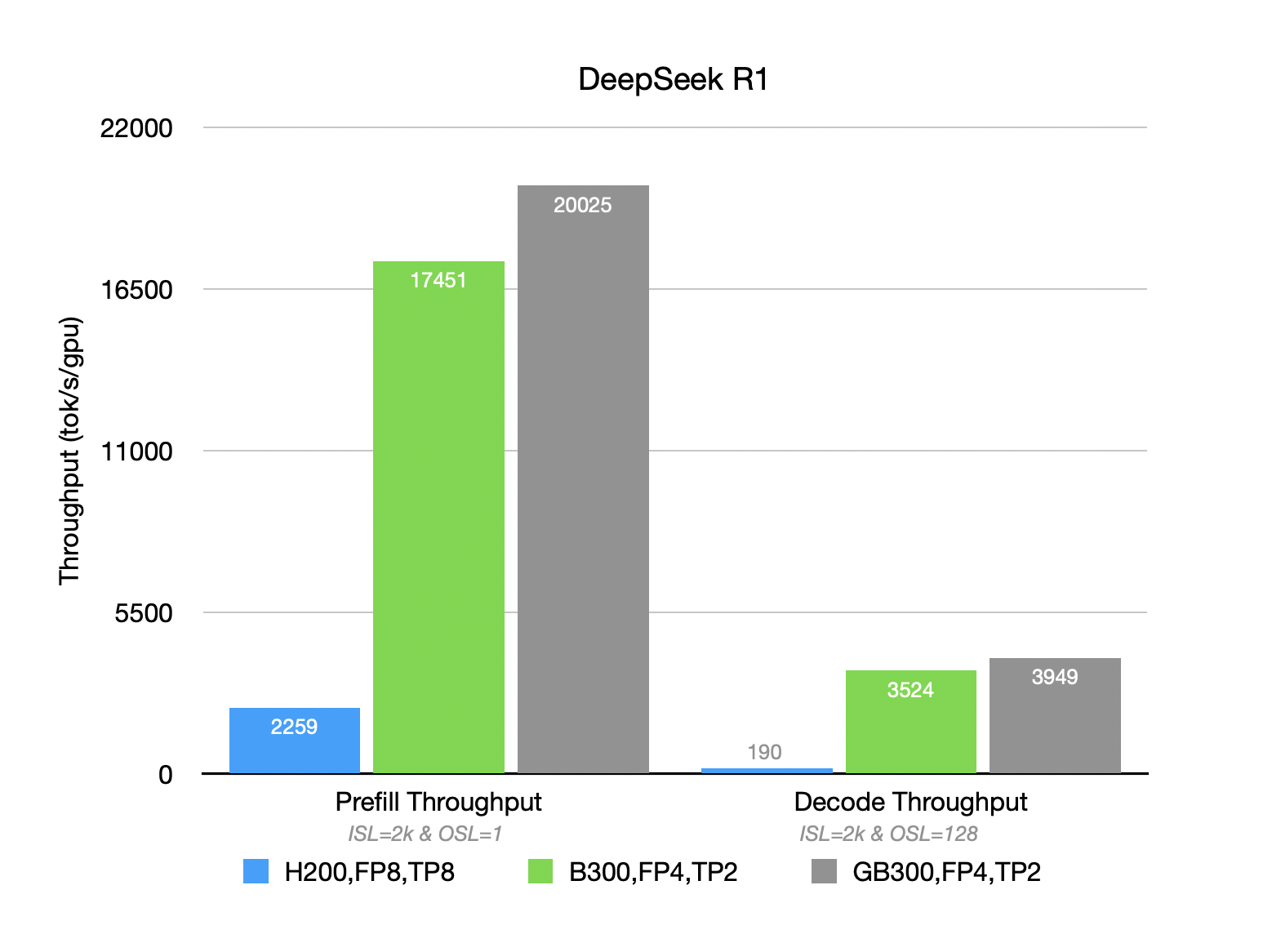
Meanwhile, with 2x GB300 GPUs, DeepSeek-R1 (NVFP4 + EP2) can achieve a throughput of 22476 TGS(ISL=2K,OSL=1,batch=256) in a prefill-only scenario, and reach 3072 TGS in a mixed-context scenario (ISL=2k,OSL=1k).
Compared to the Hopper series, the B300 series demonstrates an 8x performance improvement in Prefill, and 10-20x improvement in mixed-context scenarios.
Note
This blog emphasizes architectural and deployment validation over peak-throughput tuning, and the results reflect reproducible baseline performance. All experiments can be reproduced with the following software stack:
- vLLM: v0.14.1
- CUDA: 13.0
Benchmark Setup
In this blog, we evaluate performance under three representative benchmark scenarios:
- Prefill-only scenario
This scenario sets the output sequence length to OSL =1, so execution time is dominated by the prefill phase. It is mainly used to measure prefill throughput and compare how different architectures and parallelization strategies handle long input contexts.
- Mixed-context scenario (short output)
This scenario uses a short output length ISL=2k, OSL= 64/128 with long input contexts.
- Mixed-context scenario (moderate output)
This represents a more realistic online serving workload, where both prefill and decode phases contribute meaningfully to execution time. We typically use ISL=2k, OSL=1k to evaluate throughput under mixed execution.
Below is an example command used to generate these benchmarks:
vllm bench serve --model nvidia/DeepSeek-R1-0528-NVFP4 \
--seed $RANDOM \
--dataset-name random \
--base-url http://${PROXY_NODE_IP}:8000 \
--tokenizer /mnt/models/DeepSeek-V3.2 \
--num-prompts 1000 \
--max-concurrency $MAX_CONCURRENCY \
--random-input-len $ISL \
--random-output-len $OSL \
--ignore-eos
Metrics reported by vllm bench serve are used in all figures:
- Prefill Throughput
Total token throughput (tok/s)
- Decode Throughput
Output token throughput (tok/s)
Basic Recipe with FP4 Weight Quantization
One of Blackwell’s most notable features is the fifth-generation Tensor Core’s native support for NVFP4.
1. Download NVFP4 Model Weights from Hugging Face
2. Use FP4 MoE kernel provided by FlashInfer
FP4 MoE models on Blackwell require you to explicitly set VLLM_USE_FLASHINFER_MOE_FP4=1 to enable the FlashInfer FP4 MoE kernel.
export VLLM_USE_FLASHINFER_MOE_FP4=1
3. Serve the Model
The GB300/B300 single-GPU memory is 288GB. Two GPUs are sufficient to hold the NVFP4 format weights of the DeepSeek series models.
vllm serve nvidia/DeepSeek-V3.2-NVFP4 -tp 2
# or
vllm serve nvidia/DeepSeek-R1-0528-NVFP4 -tp 2
4. Optimized Configurations
Below are reference values for the max boundary batch to achieve better prefill throughput for TP2, using the additional parameter --max-num-batched-tokens:
# DeepSeek-R1-0528-NVFP4
--max-num-batched-tokens 32768
# DeepSeek-V3.2-NVFP4
--max-num-batched-tokens 20480
Performance Boost by Blackwell Architecture
FP8 vs. FP4 (for DeepSeek V3.2)
While deploying DeepSeek V3.2 on GB300 (B300), we observed a notable performance characteristic: NVFP4 quantization delivers significant performance gains, achieving superior overall performance even while using only half the hardware resources(GPU count) of standard configurations. However, the experimental results also clearly show that low precision alone is insufficient to fully unlock performance potential, and the choice of parallelization strategy is equally critical.
The data highlights a clear advantage for NVFP4 with TP2. In prefill-only scenarios (ISL=2k, OSL=1, batch=64), TP2 delivers a 1.8× improvement over FP8 and achieves up to 7360 TGS total throughput. In mixed-context scenarios (ISL=2k, OSL=1k), the output throughput increases to 2816 TGS (an 8× gain). In contrast, the TP4 configuration shows more modest gains—only 14% in prefill and a 2× improvement in mixed-context scenarios, making the TP2 results significantly more efficient.
These gains are driven by two factors: reduced memory overhead and simplified compute logic. NVFP4 substantially eases memory bandwidth pressure, which is critical for increasing output token throughput. Additionally, simplified computations within the attention layers directly optimize end-to-end latency during the prefill phase.
Why do we recommend the NVFP4 + TP2 combination?
The results show that weight quantization is only part of the equation; another performance driver lies in the balance between parallelism and per-GPU workload. NVFP4 significantly reduces the model and KV cache footprint, lowering bandwidth pressure and enabling larger batch sizes.
Under a TP2 configuration, the workload per GPU remains sufficiently large to allow Tensor Cores to fully exploit FP4’s higher Tensor Core FLOPs and bandwidth efficiency. Conversely, the finer-grained partitioning of TP4 dilutes the workload per GPU, preventing the system from fully capturing the efficiency gains provided by NVFP4.
Tip
To use FP8, switch to FP8 model weights and then use VLLM_USE_FLASHINFER_MOE_FP8=1.
Under FP8, DeepSeek-V3.2 requires 4 GPUs, then use -tp 4.
Blackwell Ultra vs. Hopper (for DeepSeek R1)
The chart below shows the per-GPU total throughput comparison, under the same requests and vLLM setup, for GB300 (NVL72), B300 (HGX), and last-gen H200:
- In prefill-only (ISL=2k) scenarios, GB300’s per-GPU throughput is 14% higher than B300, and 8x higher compared to H200.
- In short output mixed-context scenarios (ISL=2k,OSL=128), GB300’s per-GPU throughput is 12% higher than B300, and 20x higher than H200.
The reasons are multifaceted: Besides FP4, B300’s FLOPs are 7.5x higher than the Hopper series (peak reaches ~15 PFLOPs). The optimization of attention layer computations by the SM’s SFU modules brings efficiency gains in Prefill.
Its 288GB memory is also 2x that of H200, with memory bandwidth nearly doubled. Additionally, Blackwell Ultra’s high-density NVFP4 FLOPs speed up MoE forward compared to Hopper’s FP8. Those contribute to a significant performance leap in the Decode phase.
Reference: Inside NVIDIA Blackwell Ultra
GB300 also shows minor improvements over B300 even in small-scale intra-node configurations with TP2.
Deployment Tuning
EP2 vs. TP2 Selection
Given that DeepSeek-R1’s weights can fit within the HBM of only two B300 GPUs, we explored whether it’s better to scale via DP based on TP2 or based on EP2.
Note
The CLI parameter to switch to EP2 is -dp=2 --enable-expert-parallel.
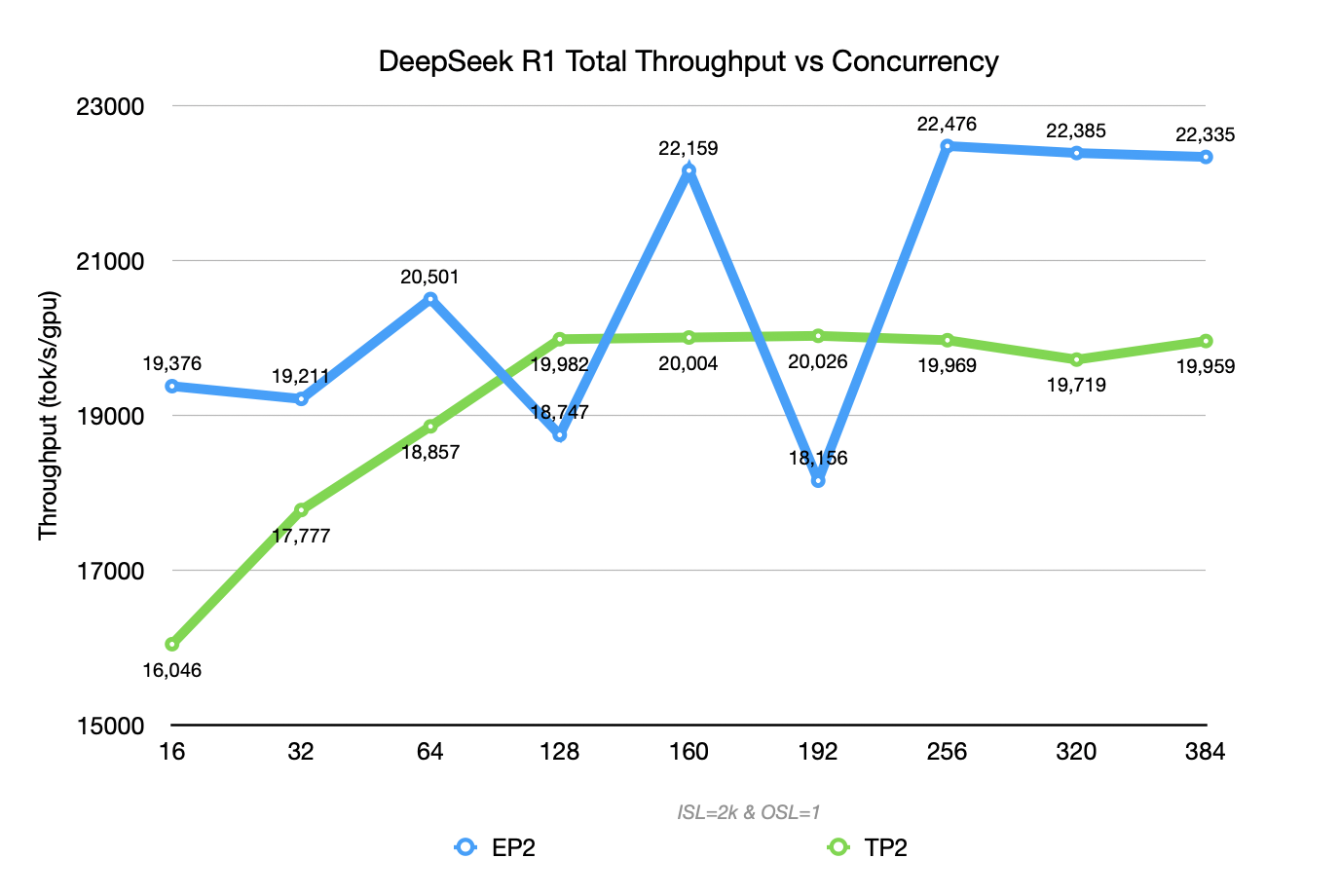
a. Prefill-Only Scenario (ISL=2k, OSL=1)
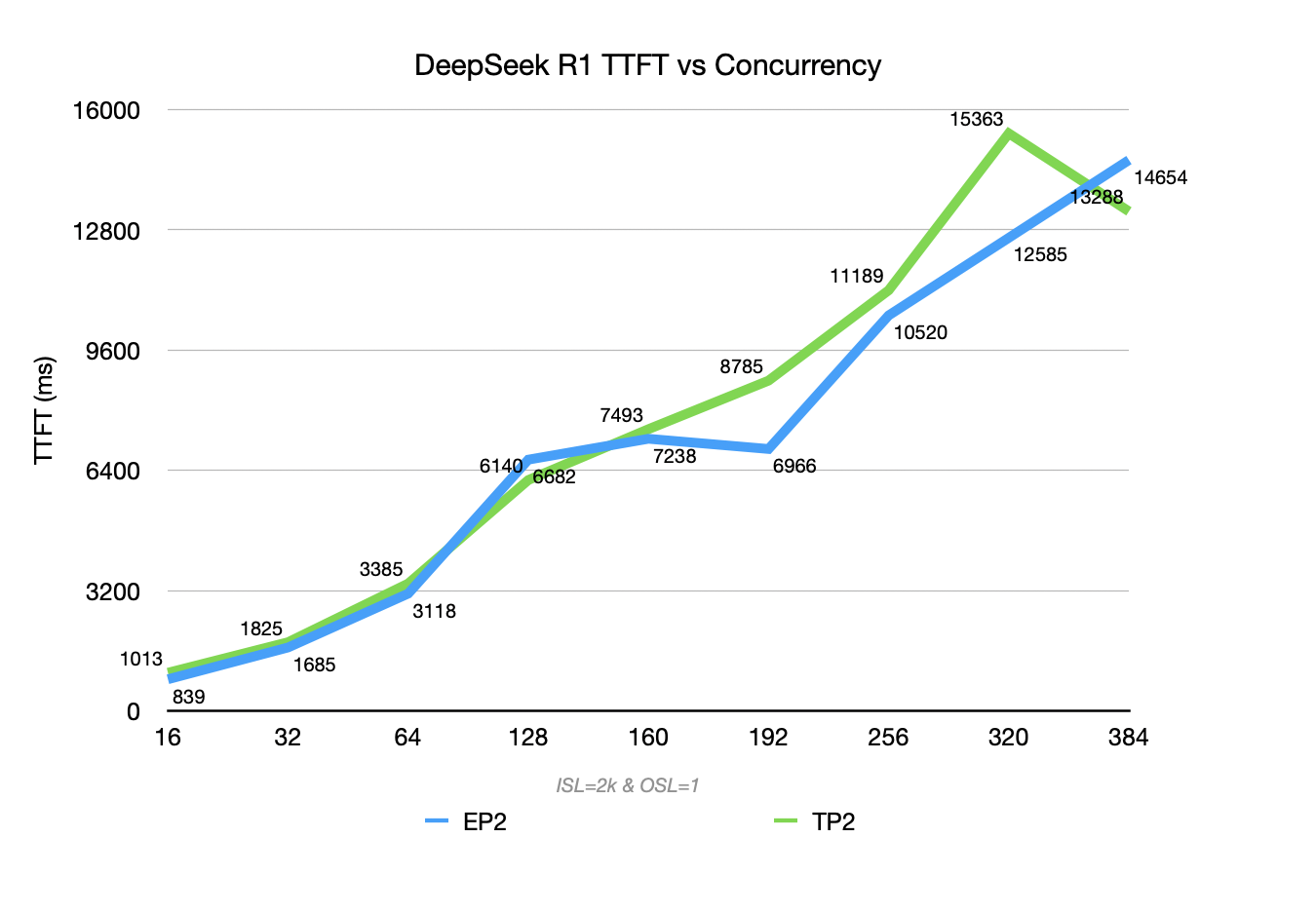
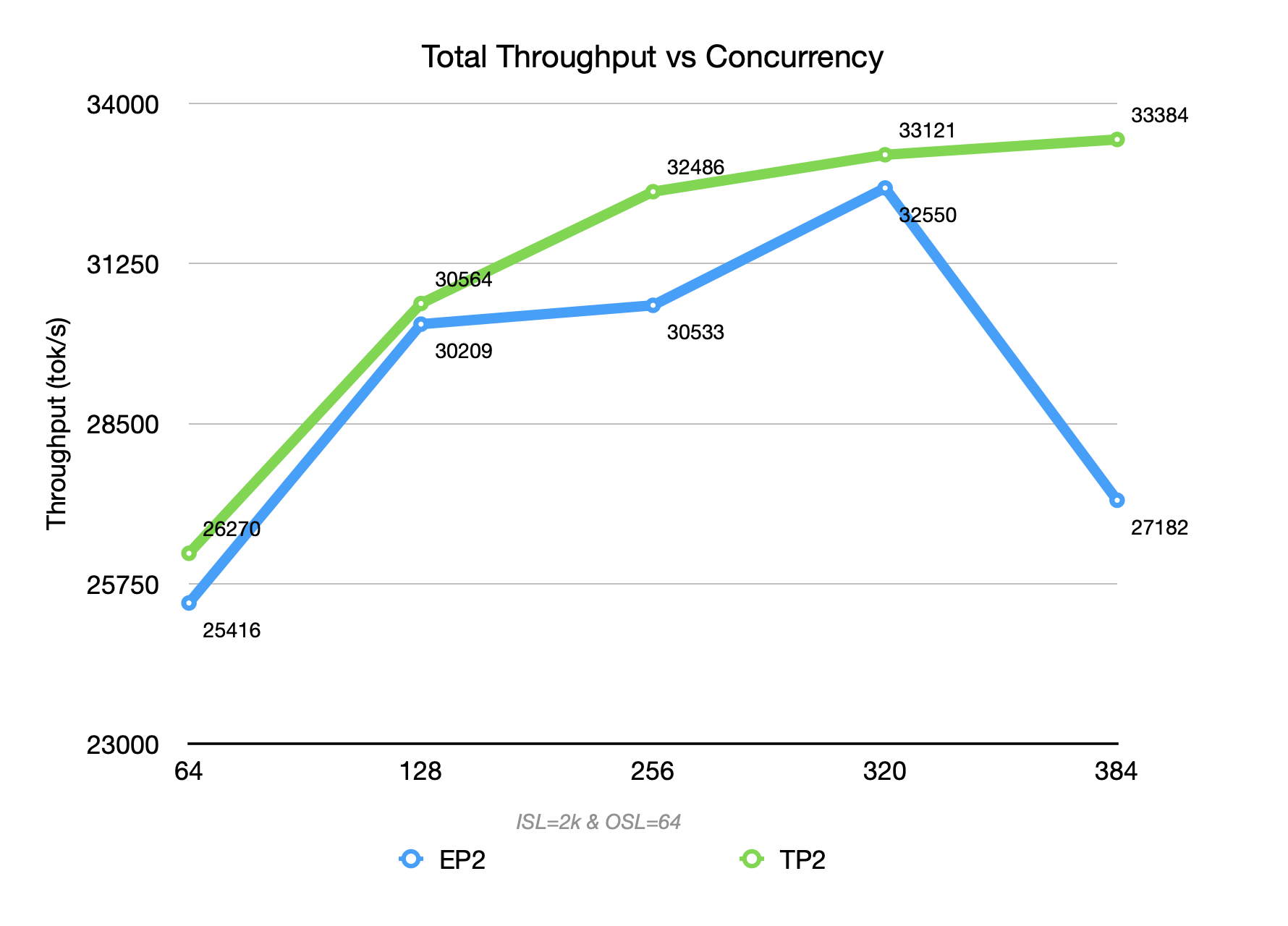
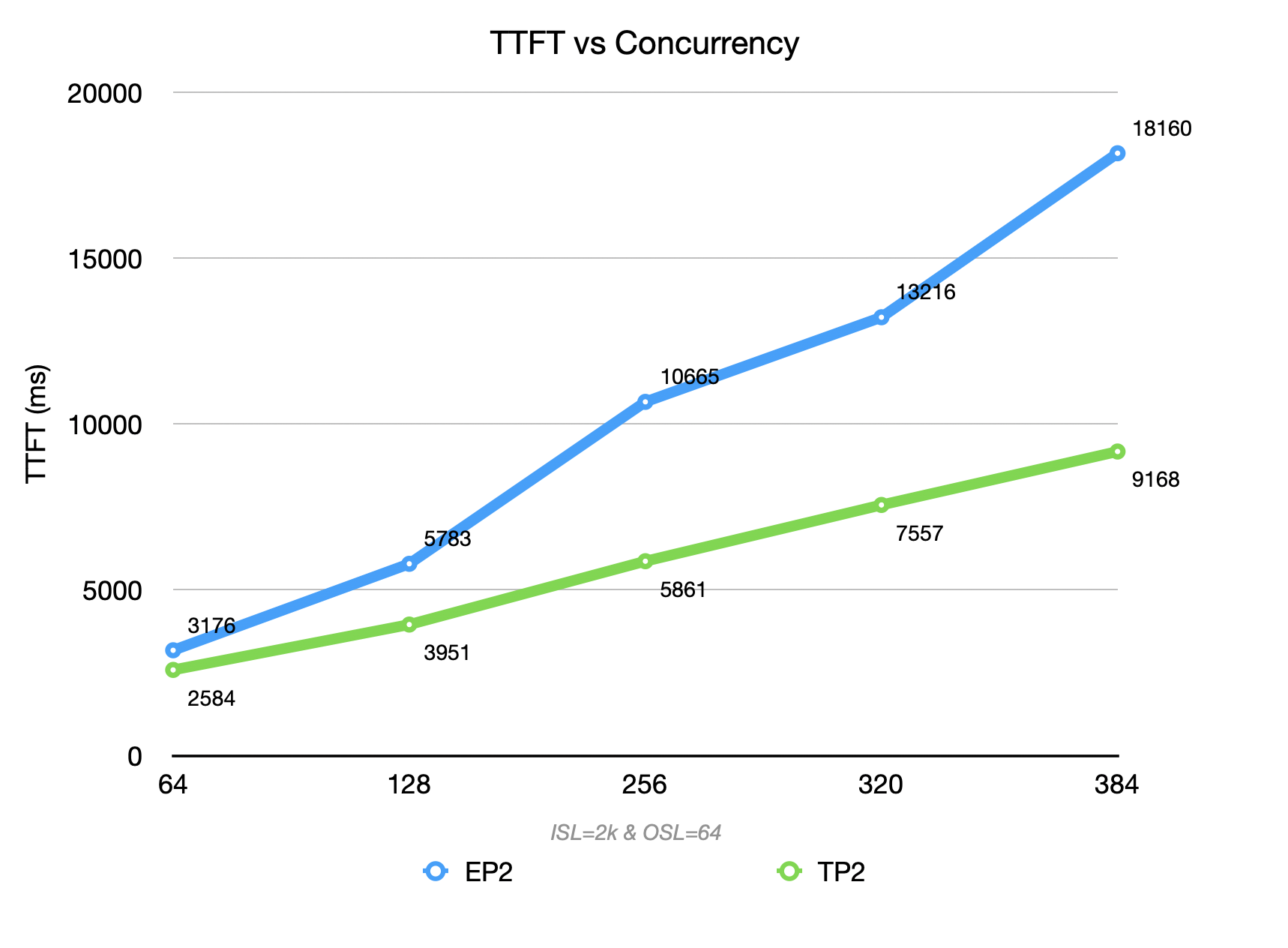
EP2 (blue curve) reaches a throughput ceiling of 22476 TGS, outperforming TP2 (green curve) in both throughput and the growth slope of TTFT. This benefits from EP’s typical “large packet, low frequency” communication pattern, which better utilizes the high bandwidth of RDMA/NVLink under high concurrency.
However, the blue EP curve exhibits some fluctuations due to unbalanced expert routing, causing different batches to hit different expert distributions and resulting in variations in expert load and all-to-all communication volume.
b. Short Output Mixed-Context Scenario (ISL=2k,OSL=64)
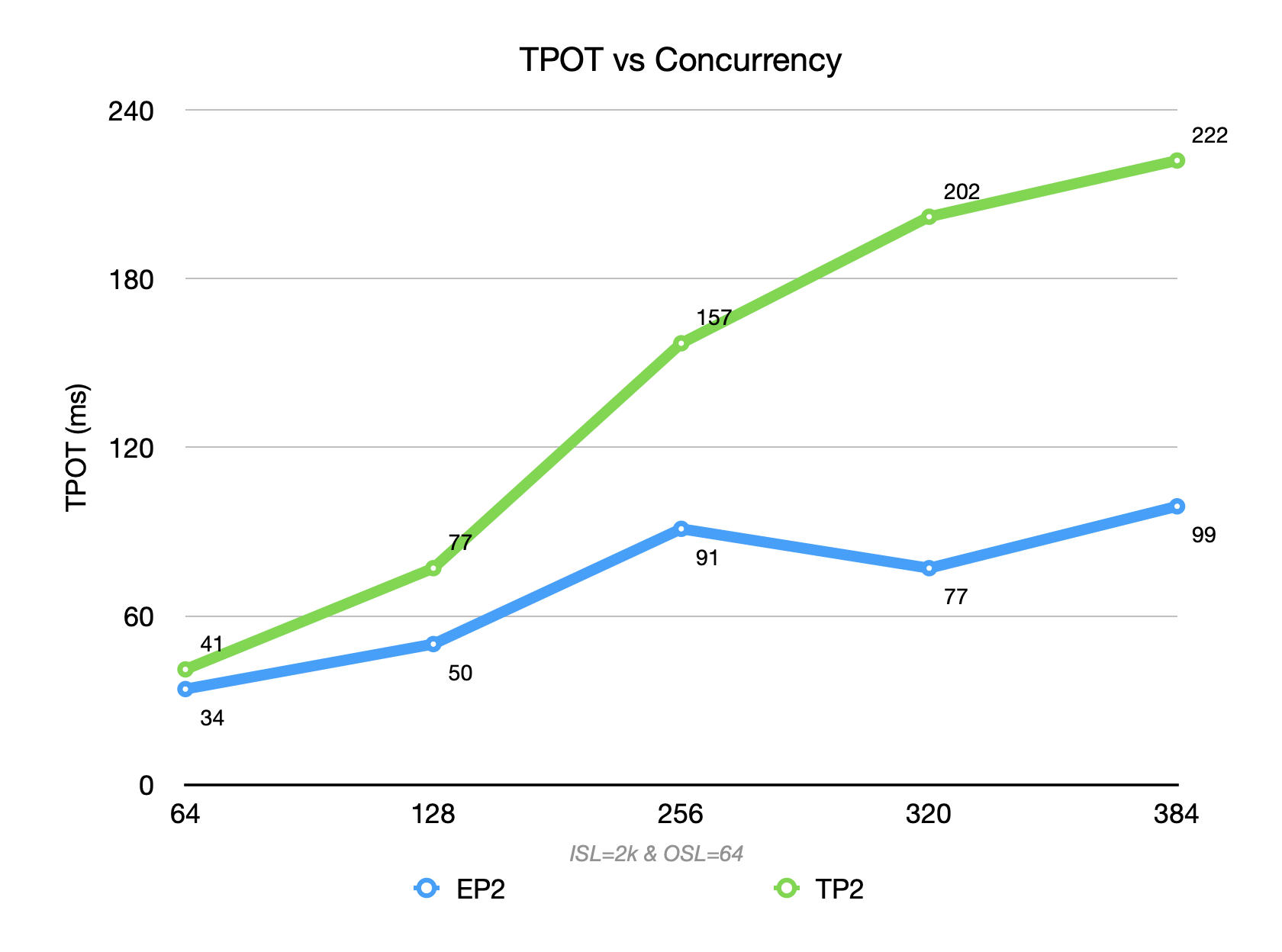
Under TP2, each decode step introduces inter-GPU communication overhead, which leads to a 50% to 2× degradation in TPOT compared to EP2.
However, TP also improves TTFT by ~ 50%, accelerating the execution of each step. This improvement offsets the TPOT degradation, ultimately resulting in an overall throughput gain of 5%–20% in terms of output tokens.
Conclusions
- For DeepSeek-R1 on GB300 in disaggregated prefill, EP is more suitable for prefiller (then simply increase the DP count for scaling). EP has a higher throughput ceiling in Prefill (peak ~10% - 15% higher than TP2), while TTFT growth with concurrency is more gradual, which is more beneficial for controlling queuing and tail latency.
- In a P+D integrated deployment, the strategy depends on workload:
- When ISL is large and OSL is small, the prefill phase becomes the dominant bottleneck,
TP2is recommended, to prevent excessive attention-layer latency from crowding out GPU time in the decode phase. - In contrast, for output-heavy case, the TPOT advantage of
EP2becomes dominant, and it is therefore the preferred configuration.
- When ISL is large and OSL is small, the prefill phase becomes the dominant bottleneck,
Benefits of MTP
MTP provides decent improvements for Decode, but not always a silver bullet.
As argued below, the built-in draft model speculates 1 token at a time, balancing acceptance rate and computational load.
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 1
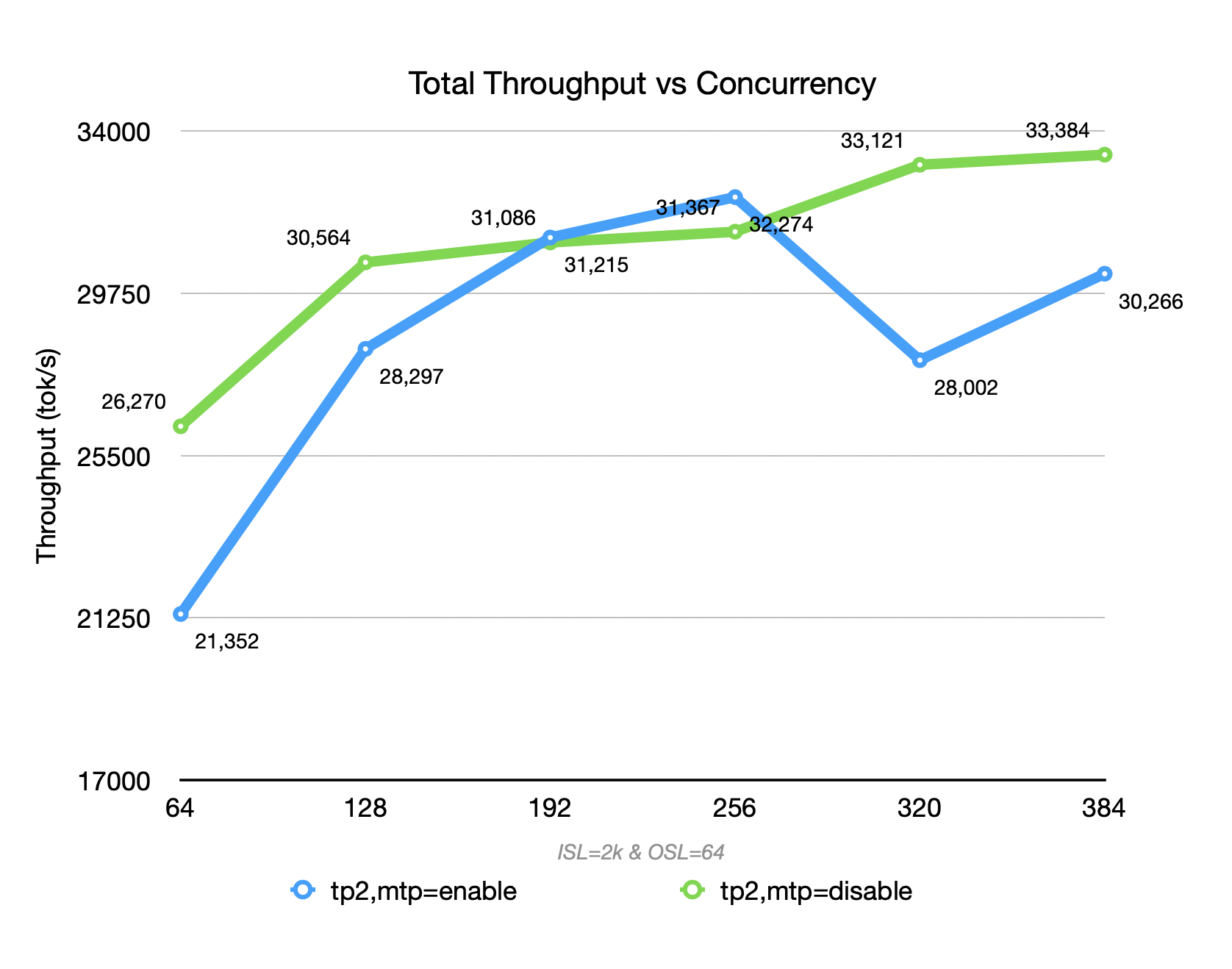
When the context length is not long, enabling MTP (blue) for DeepSeek R1-0528 on GB300 achieves higher throughput than disabling MTP (green) within a certain concurrency range (<=256) (acceptance rate can reach > 80%). However, throughput drops sharply when MTP is enabled under high concurrency.
In a mixed-context scenario (ISL=2k,OSL=64), the decode proportion is extremely low. The overhead of MTP’s multi-token prediction cannot be amortized, resulting in increased per-token compute, memory pressure, and scheduling complexity. At low concurrency, the overhead cannot be amortized; at high concurrency, it further squeezes prefill batching and system concurrency.
Therefore, the overall throughput is lower than that achieved with MTP disabled at both low and high concurrency levels.
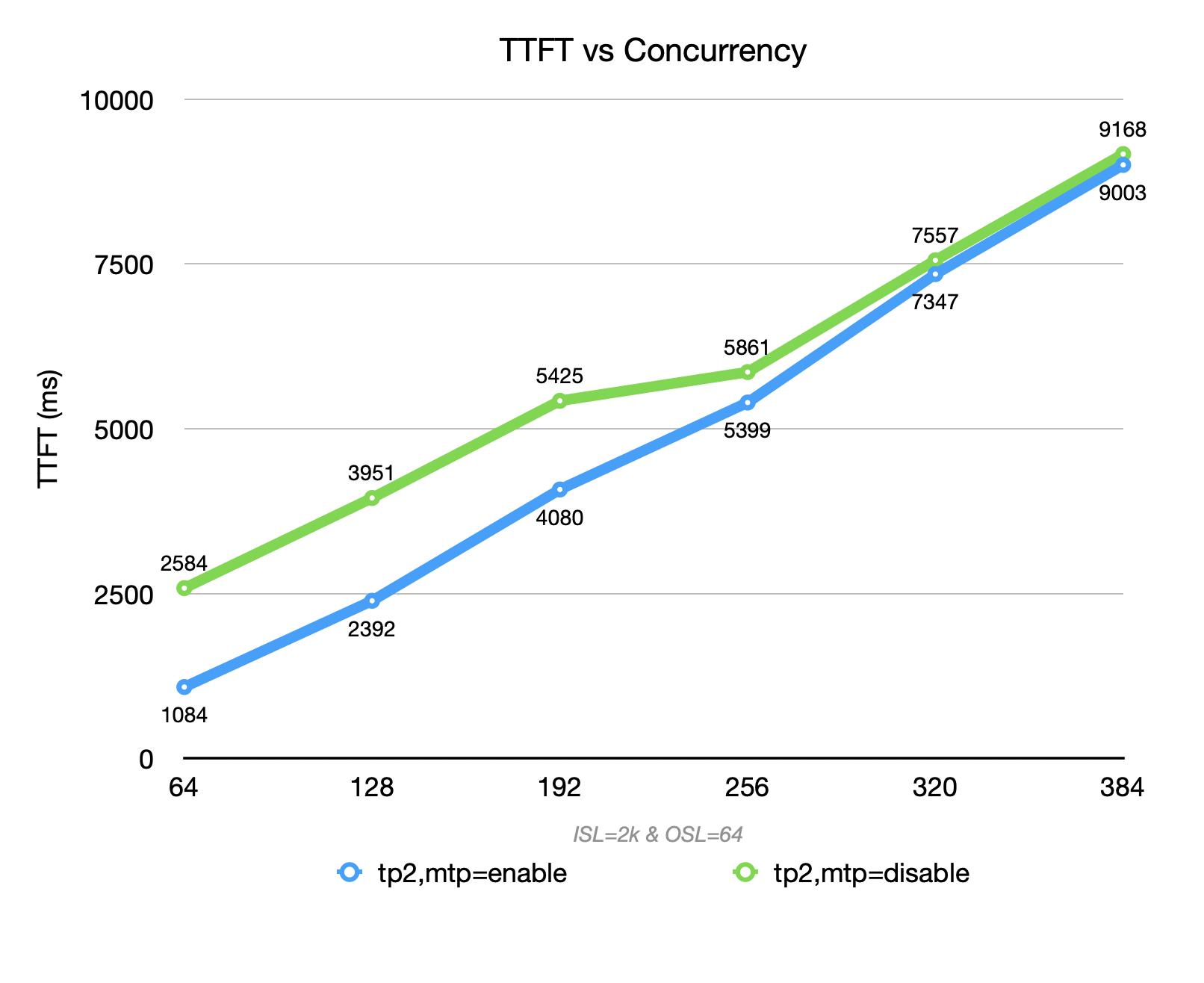
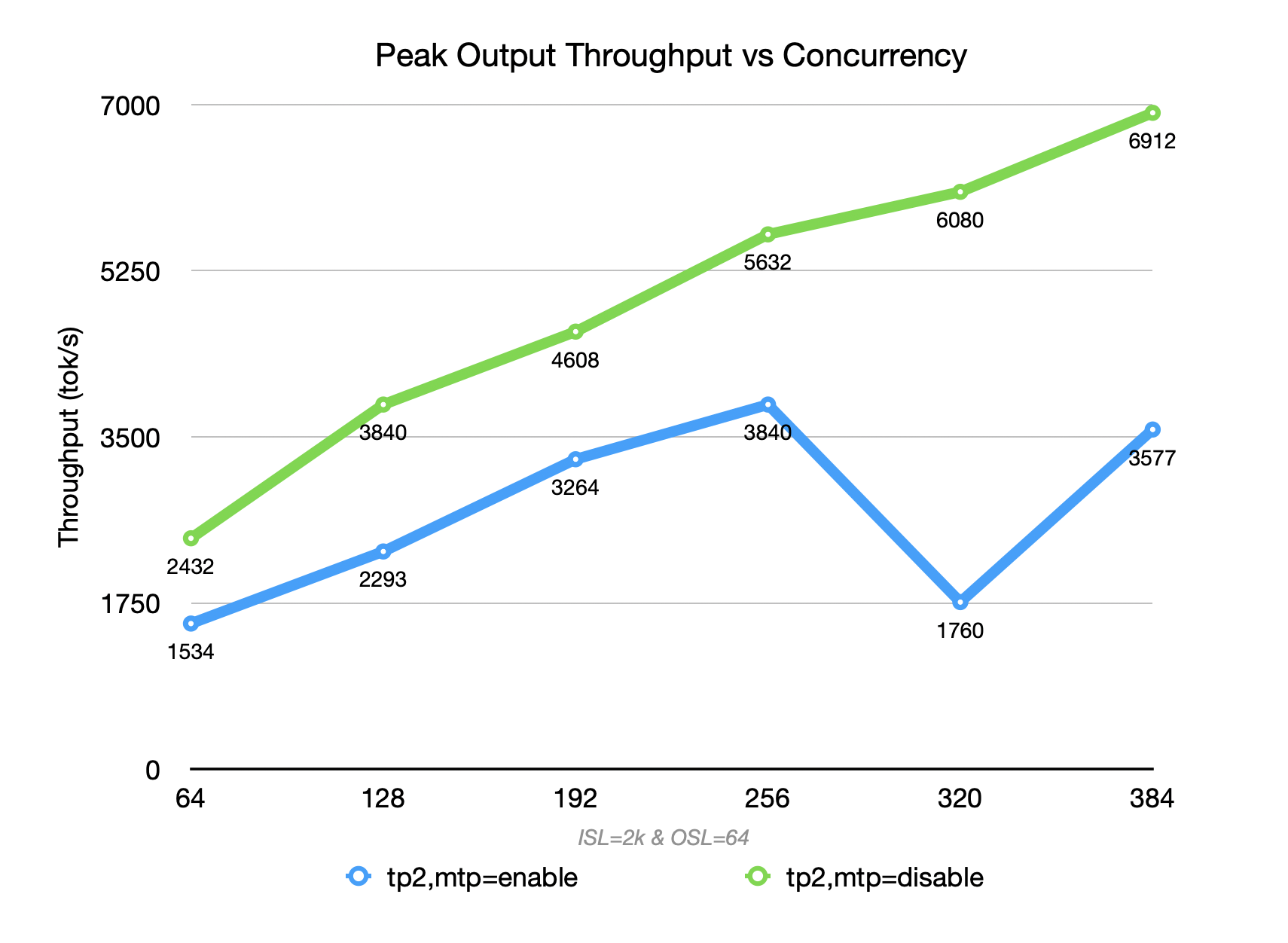
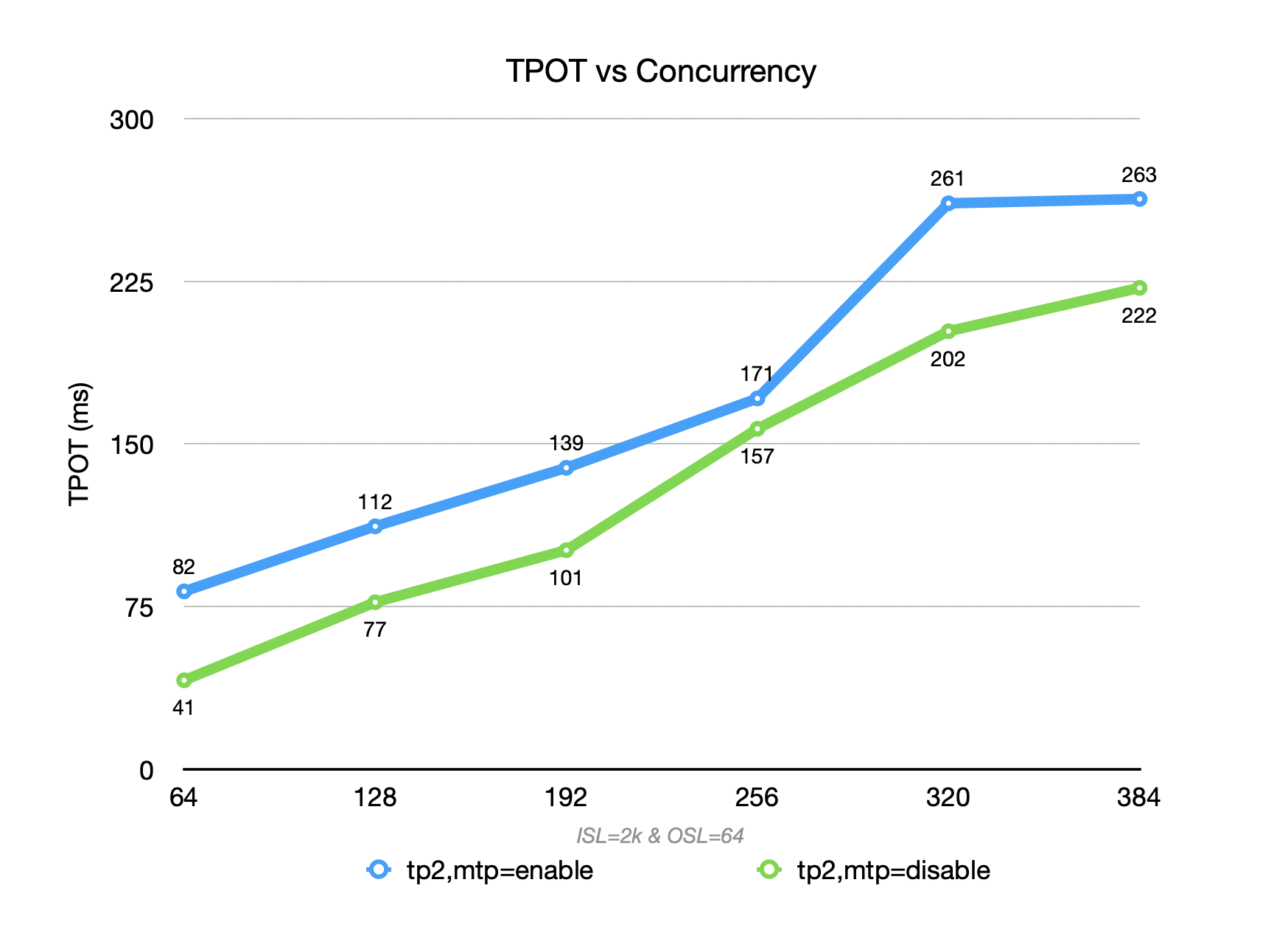
DeepSeek V3.2 - Still Way To Go
As shown in the chart below, with the same GB300 setup, DeepSeek R1’s Prefill throughput capability is ~ 3x that of DeepSeek V3.2.
- DeepSeek R1 in EP2 can reach a peak Prefill throughput of ~ 22476 TGS.
- DeepSeek V3.2 in EP2 is relatively weaker, with a Prefill peak throughput of ~ 7360 TGS.
- Regarding TTFT, with both models using TP2, R1 reduces latency by about 55% compared to V3.2.
However, a mixed-context scenario (ISL=2k,OSL=1k), the gap between the two models in terms of Output Throughput and TPOT is not significant.
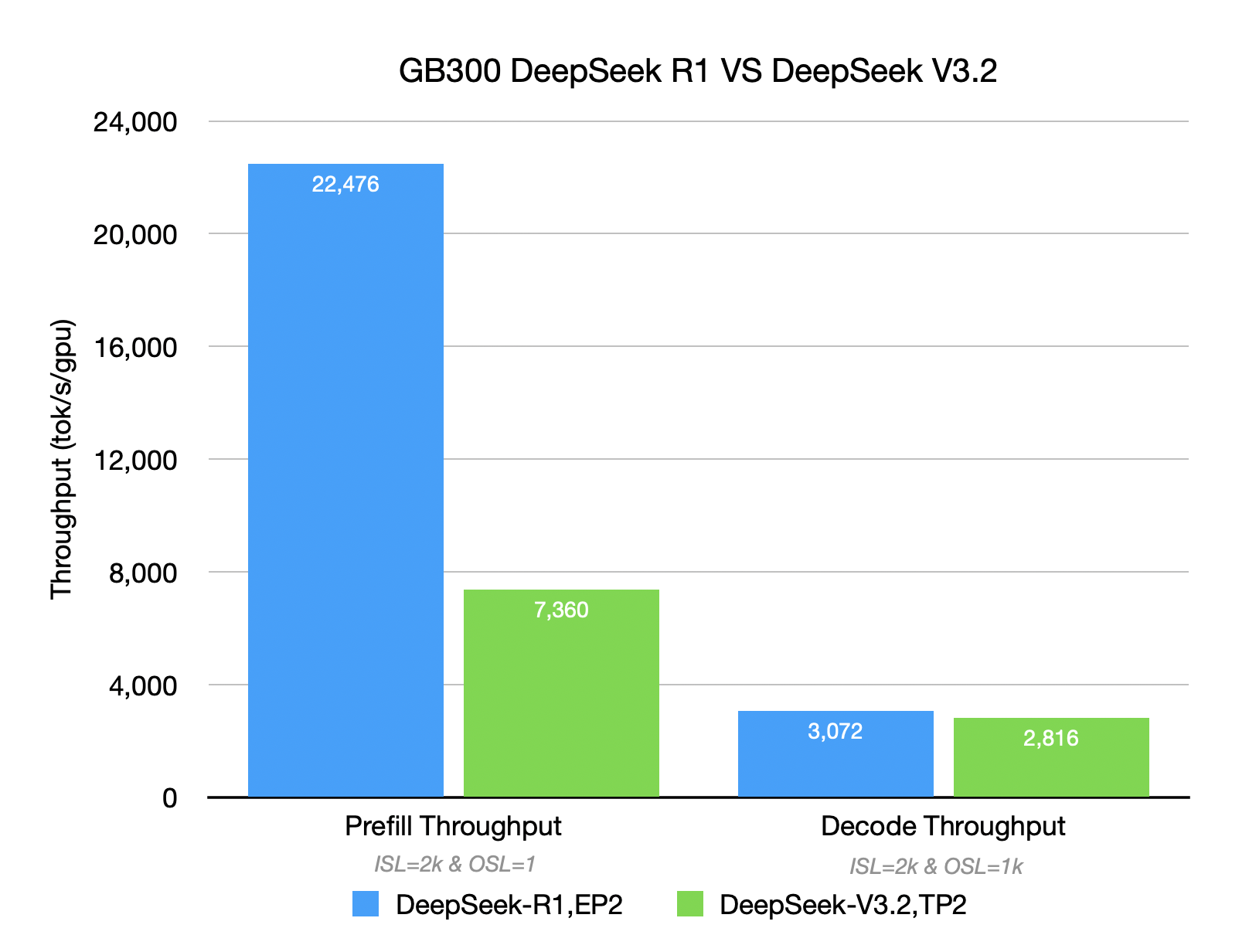
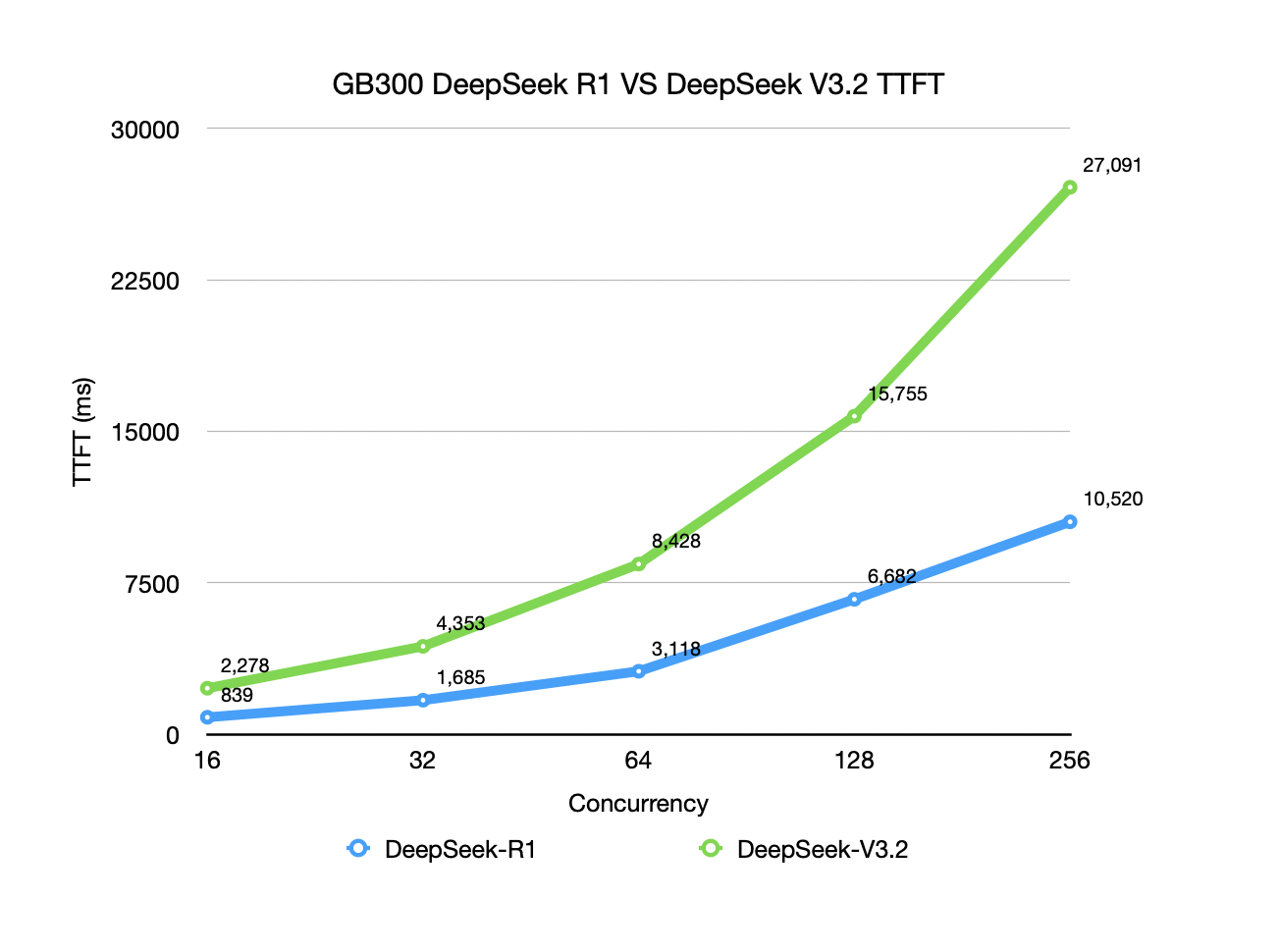
Why does R1’s throughput beat V3.2 overall?
The main reason is that V3.2 introduces the Indexer/Sparse MLA (Indexer + SparseAttnIndexer) and uses DeepseekV32IndexerBackend with a dedicated cache structure. In the prefill phase, this adds extra quantization/indexing computation, which reduces throughput. Profiling analysis also shows that the kernel execution time for a single DSA layer step is 2.7x that of MLA.
From a vLLM code perspective, apart from the Indexer path, NVFP4 MoE kernel selection is identical between V3.2 and R1. So the prefill performance difference primarily comes from the overhead of V3.2’s Indexer/Sparse Attention.
The advantage of DSA better serves ultra-long contexts. If your context doesn’t require sufficient attention computation, the extra overhead becomes pronounced. However, as the context length increases further, DSA’s TPOT advantage in the Decode phase shows up, surpassing MLA between 10k-20k tokens and leading with about a 6x steeper slope.
Lastly, the DeepseekV32IndexerBackend is still relatively new and immature, with considerable optimization potential.
Therefore, we believe DeepSeek-V3.2 still has significant room for improvement.
Disaggregated Prefill (for DeepSeek-V3.2)
Below is a quick-start tutorial for disaggregated prefill of 1P+1D via an RDMA scaleout network (next blog will show tips for NVLink72 across GB serial trays).
# Prefill Node
export VLLM_USE_FLASHINFER_MOE_FP4=1
export UCX_NET_DEVICES=mlx5_bond_0:1 # optional, tell NIXL to use specific RDMA interface
export VLLM_NIXL_SIDE_CHANNEL_HOST=${PREFILL_NODE_IP}
vllm serve nvidia/DeepSeek-V3.2-NVFP4 -tp 2 --max-num-batched-tokens 20480 \
--kv-transfer-config \
'{"kv_connector":"NixlConnector","kv_role":"kv_both","kv_load_failure_policy":"fail","kv_buffer_device":"cuda"}' \
--port 8000
# Decode Node
export VLLM_NIXL_SIDE_CHANNEL_HOST=${DECODE_NODE_IP}
...
# Exactly the same environment variables and vLLM CLI as Prefill Node, except `VLLM_NIXL_SIDE_CHANNEL_HOST`
# Proxy Node
cd vllm # move to vLLM source code and may need to install necessary dependencies
python tests/v1/kv_connector/nixl_integration/toy_proxy_server.py \
--port 8000 \
--prefiller-hosts ${PREFILL_NODE_IP} --prefiller-ports 8000 \
--decoder-hosts ${DECODE_NODE_IP} --decoder-ports 8000
# If you have multiple Prefillers or Decoders:
# just append to hosts list, like: `--prefiller-hosts ${IP1} ${IP2} --prefiller-ports 8000 8000 `
# vLLM bench against the proxy (using a random dataset and ISL=4k,OSL=1k)
vllm bench serve --model nvidia/DeepSeek-V3.2-NVFP4 \
--seed $RANDOM --dataset-name random \
--base-url http://${PROXY_NODE_IP}:8000 \
--tokenizer /mnt/models/DeepSeek-V3.2 \
--num-prompts 500 --max-concurrency 100 \
--random-input-len 4096 --random-output-len 1024 \
--ignore-eos
Note
PD Disaggregation on vLLM v0.14.1: To run PD disaggregation with vLLM v0.14.1, you need to manually apply the patch from PR #32698. However, this feature has been merged into the latest vLLM main branch, so if you’re using a newer version, you may not need this patch.
We use the Nixl KV Connector to facilitate KV transfer across processes/nodes. Both P and D roles use the TP2 strategy.
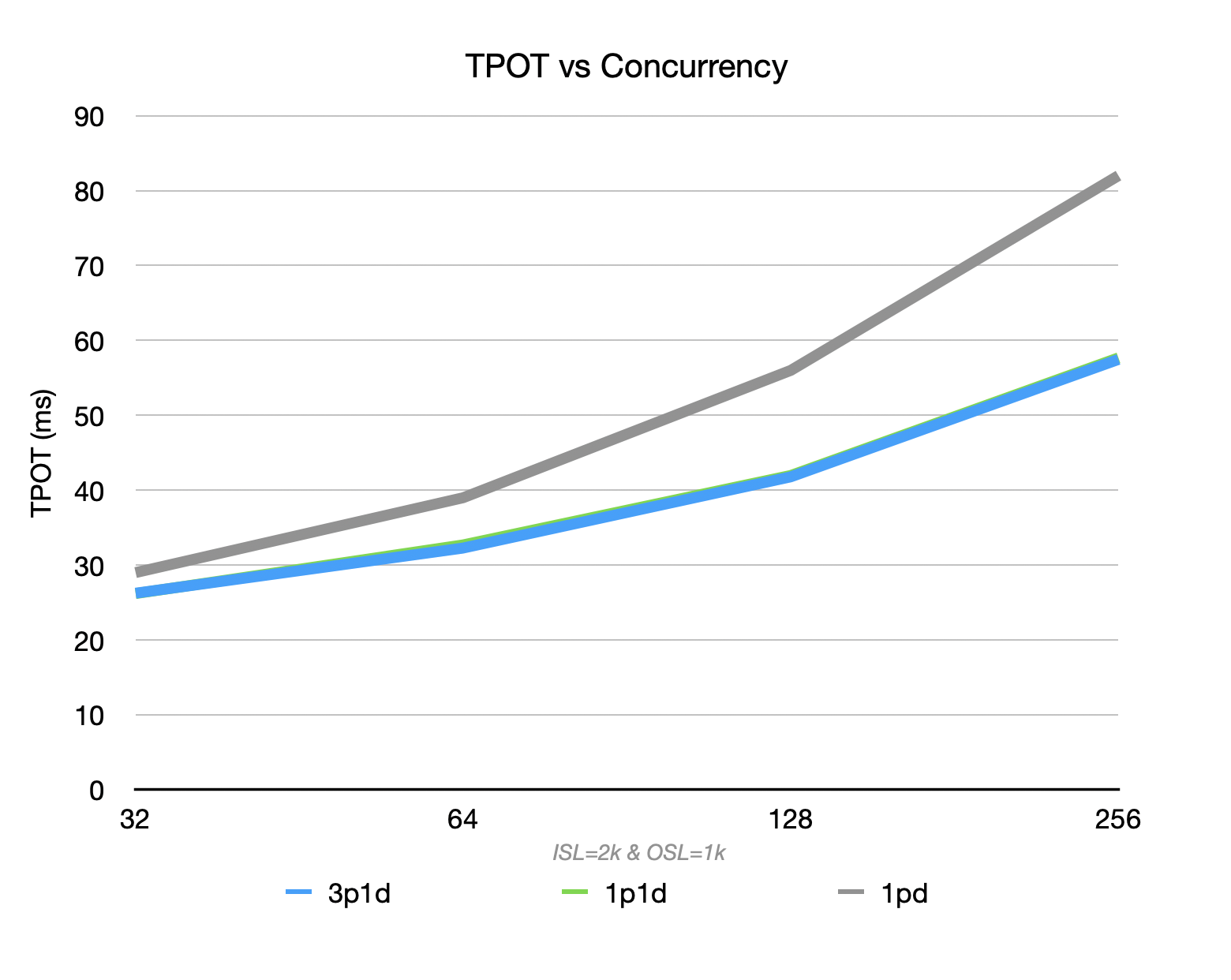
As concurrent load increases, the disagg setup shows throughput advantages over the integrated setup, with the gap widening, while maintaining lower latency (both TTFT and TPOT). The slope of latency increase is also more stable.
Regarding TPOT, both 1P1D and 3P1D outperform the non-disagg setup. At a batch size of 256, the disagg setup suppresses TPOT within 60ms, while the integrated setup exceeds 80ms.
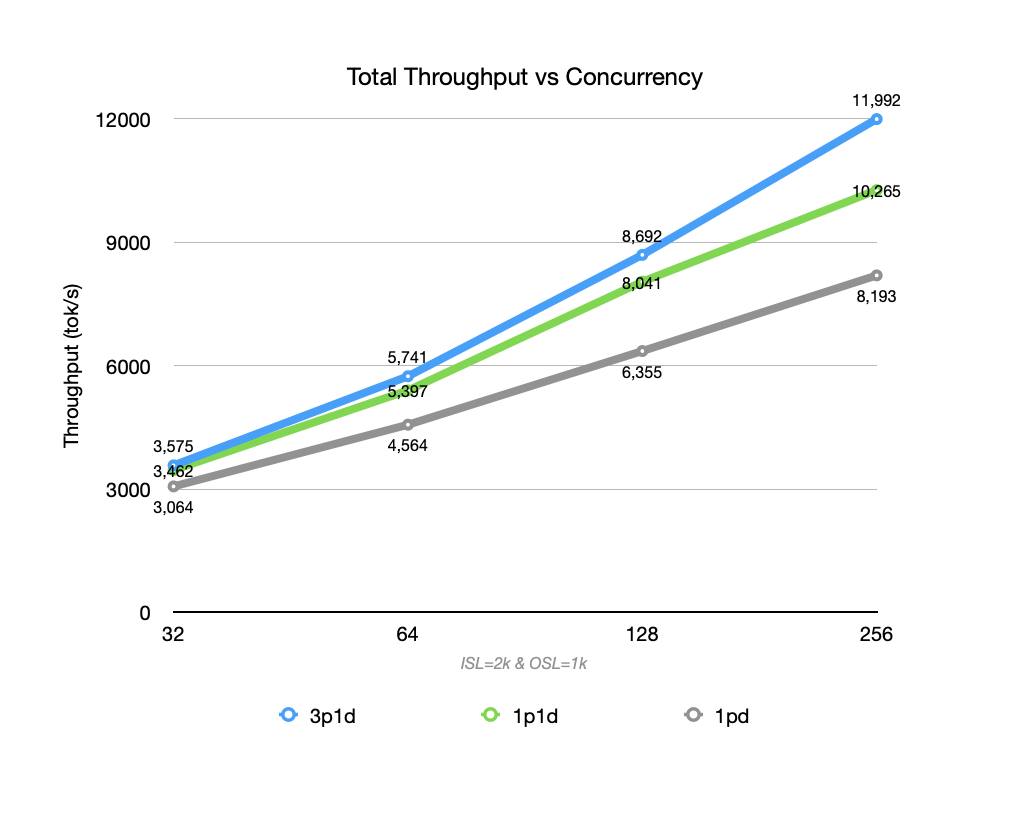
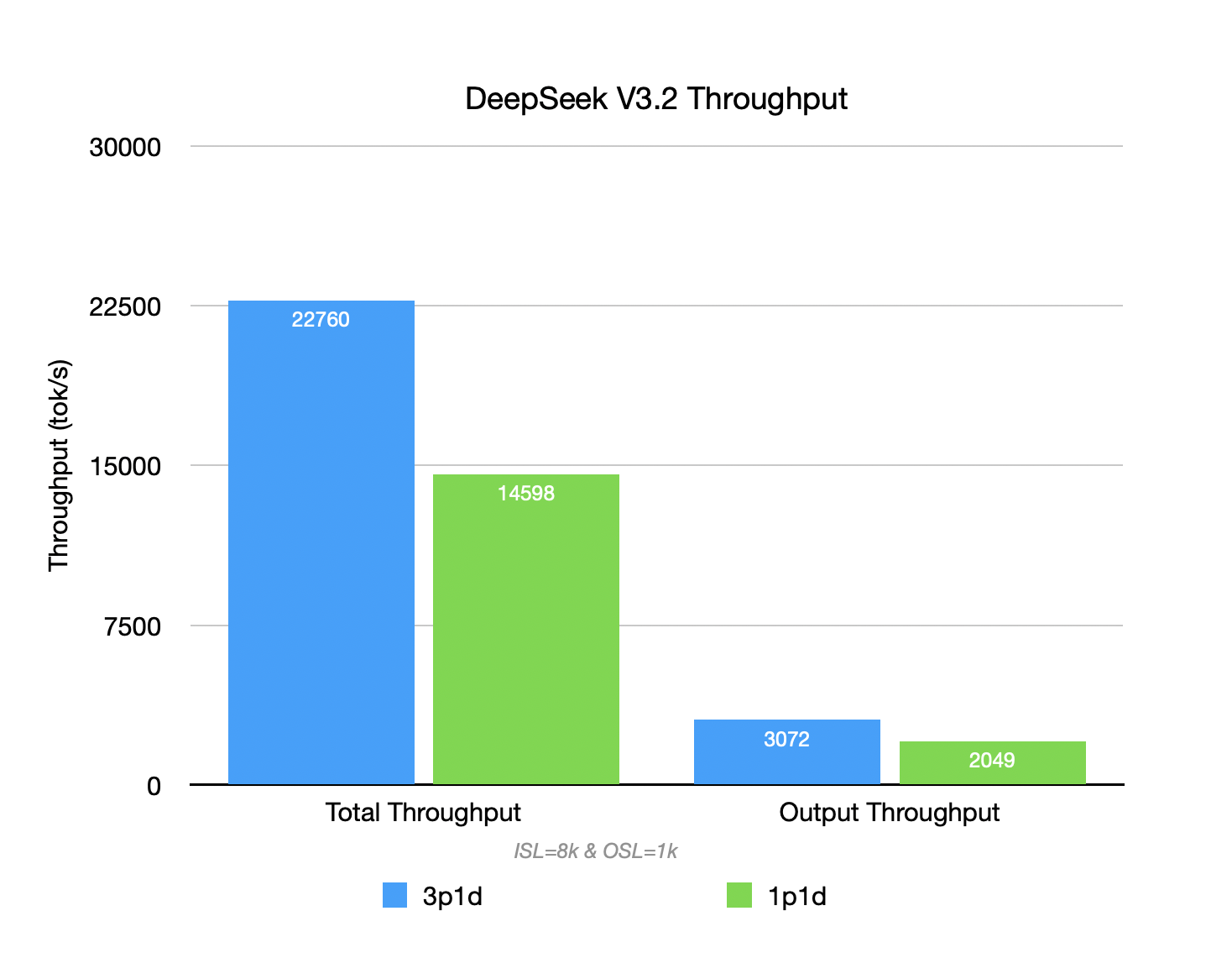
When ISL continues to grow (from 2K to 8K), the throughput of the 1P1D setup begins to struggle, with Prefill becoming the bottleneck. Requests wait in queue at the P node, unable to fully utilize the Decoder’s compute power. When adding 2 P replicas (3P1D), they parallelize the Prefill phase of more requests, achieving better total throughput.
Although the per-GPU throughput may not be the highest for disaggregation, better Goodput and SLO guarantees are achieved with more hardware investment.
Preview: next blog will showcase the practice of P/D disaggregation, leveraging NVL72 on GB200.
Acknowledgements
We would like to give thanks to the many talented people in the vLLM community who worked together as a part of this effort:
- Verda Team: for providing GB300 cluster and offering infrastructure support.
- DaoCloud Team: Xingyan Jiang, Nicole Li, Peter Pan, Kebe Liu
- InferAct Team: Jie Li, Kaichao You