Serving LLMs on AMD MI300X: Best Practices
TL;DR: vLLM unlocks incredible performance on the AMD MI300X, achieving 1.5x higher throughput and 1.7x faster time-to-first-token (TTFT) than Text Generation Inference (TGI) for Llama 3.1 405B. It also achieves 1.8x higher throughput and 5.1x faster TTFT than TGI for Llama 3.1 70B. This guide explores 8 key vLLM settings to maximize efficiency, showing you how to leverage the power of open-source LLM inference on AMD. If you just want to see the optimal parameters, jump to the Quick Start Guide.
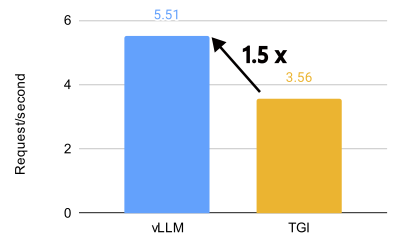
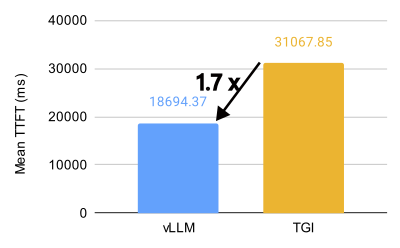
vLLM vs. TGI performance comparison for Llama 3.1 405B on 8 x MI300X (BF16, 32 QPS).
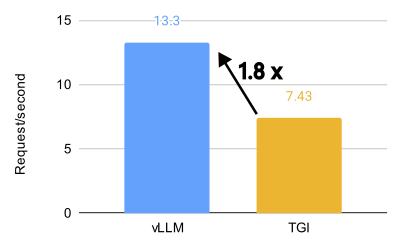
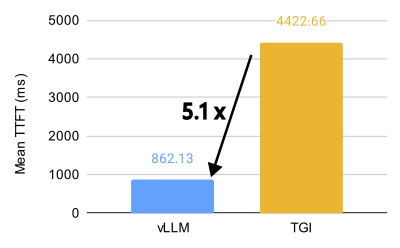
vLLM vs. TGI performance comparison for Llama 3.1 70B on 8 x MI300X (BF16, 32 QPS).
Introduction
Meta recently announced they’re running 100% of their live Llama 3.1 405B model traffic on AMD MI300X GPUs, showcasing the power and readiness of AMD’s ROCm platform for large language model (LLM) inference. This exciting news coincides with the release of ROCm 6.2, which brings significant improvements to vLLM support, making it easier than ever to harness the power of AMD GPUs for LLM inference.
ROCm, AMD’s answer to CUDA, might be less familiar to some, but it’s rapidly maturing as a robust and performant alternative. With vLLM, harnessing this power is easier than ever. We’ll show you how.
vLLM v.s. TGI
vLLM unlocks incredible performance on the AMD MI300X, achieving 1.5x higher throughput and 1.7x faster time-to-first-token (TTFT) than Text Generation Inference (TGI) for Llama 3.1 405B. It also achieves 1.8x higher throughput and 5.1x faster TTFT than TGI for Llama 3.1 70B.
On Llama 3.1 405B, vLLM demonstrates significantly better performance compared to TGI in both time to first token (TTFT) and throughput across various query-per-second (QPS) scenarios. For TTFT, vLLM achieves approximately 3.8x faster response times on average compared to TGI at 16 QPS in the optimized configuration. Throughput-wise, vLLM consistently outperforms TGI, with the highest throughput of 5.76 requests/second on the ShareGPT dataset at 1000 QPS in the optimized setup, compared to TGI’s 3.55 requests/second.
Even in the default configuration, vLLM shows superior performance compared to TGI. For instance, at 16 QPS, vLLM’s default configuration achieves a throughput of 4.05 requests/second versus TGI’s 2.58 requests/second. This performance advantage is maintained across different QPS levels, highlighting vLLM’s efficiency in handling large language model inference tasks.
.png)
.png)
vLLM vs. TGI performance for Llama 3.1 405B on 8 x MI300X (BF16, QPS 16, 32, 1000; see Appendix for commands).
How to run vLLM with Optimal Performance
Key Settings and Configurations
We’ve been extensively testing various vLLM settings to identify optimal configurations for MI300X. Here’s what we’ve learned:
- Chunked Prefill: The rule of thumb is to disable it for now on MI300X in most cases for better performance.
- Multi-Step Scheduling: Significant gains in GPU utilization and overall performance can be achieved with multi-step scheduling. Set the
--num-scheduler-stepsto a value between 10 and 15 to optimize GPU utilization and performance. - Prefix Caching: Combining prefix caching with chunked prefill can enhance performance in specific scenarios. However, if user requests have a low prefix caching hit rate, it might be advisable to disable both chunked prefill and prefix caching.
- Graph Capture: When working with models that support long context lengths, set the
--max-seq-len-to-captureto 16384. However, be aware that increasing this value doesn’t always guarantee performance improvements and may sometimes lead to degradation due to suboptimal bucket sizes. - AMD-Specific Optimizations: Disabling NUMA balancing and tuning
NCCL_MIN_NCHANNELScan yield further performance improvements. - KV Cache Data Type: For optimal performance, use the default KV cache data type, which automatically matches the model’s data type.
- Tensor Parallelism: For throughput optimization, use the minimum tensor parallelism (TP) that accommodates the model weights and context, and run multiple vLLM instances. For latency optimization, set TP equal to the number of GPUs in a node.
- Maximum Number of Sequences: To optimize performance, increase
--max-num-seqsto 512 or higher, based on your GPU’s memory and compute resources. This can significantly improve resource utilization and throughput, especially for models handling shorter inputs and outputs. - Use CK Flash Attention: the CK Flash Attention implementation is a lot faster than triton implementation.
Detailed Analysis and Experiments
Case 1: Chunked Prefill
Chunked prefill is an experimental feature in vLLM that allows large prefill requests to be divided into smaller chunks batched together with decode requests. This improves system efficiency by overlapping compute-bound prefill requests with memory-bound decode requests. You can enable it by setting --enable_chunked_prefill=True in the LLM constructor or using the --enable-chunked-prefill command line option.
Based on the experiment we ran, we found that there’s a slight improvement with tuning the chunked prefill values over disabling the chunked prefill feature. However, if you’re not sure whether to enable chunked prefill or not, simply start off by disabling it and you should generally expect better performance than with using the default settings. This is specific to MI300X GPUs.
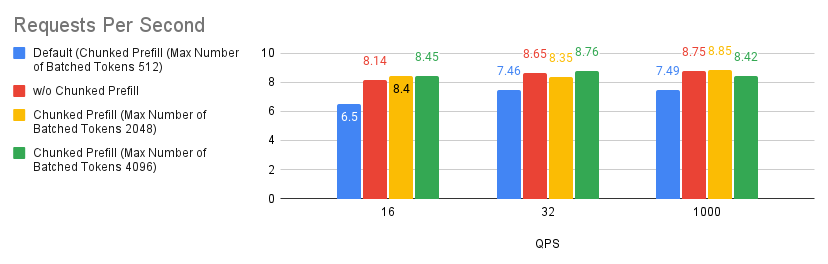
.png)
.png)
Case 2: Number of scheduler steps
Multi-step scheduling has been introduced In vLLM v0.6.0 promising higher gpu utilization and better overall performance. As detailed in this blog post, the magic behind this performance boost lies in its ability to perform scheduling and input preparation once and run the model for a number of consecutive steps without interrupting the GPU. By cleverly spreading CPU overhead across these steps, it dramatically reduces GPU idle time and supercharges performance.
To enable multi-step scheduling, set the --num-scheduler-steps argument to a number larger than 1, which is the default value (It’s worth mentioning that we found that using multi-step scheduling can provide diminishing returns the higher it goes up in value, hence, we stick with an upper bound of 15).
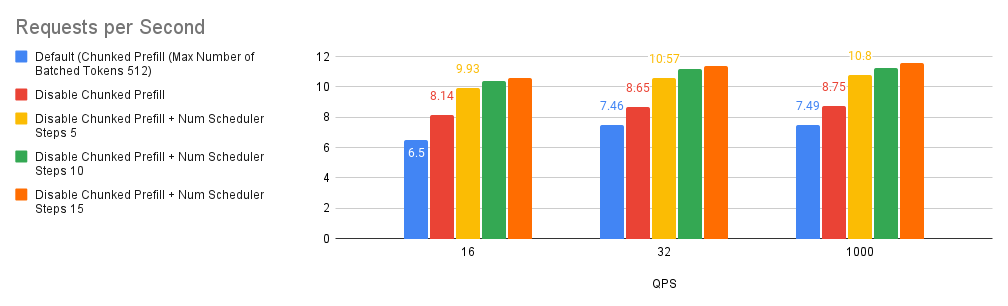
.png)
.png)
Case 3: Chunked Prefill and Prefix caching
Chunked Prefill and prefix caching are optimization techniques in vLLM that improve performance by breaking large prefills into smaller chunks for efficient batching and reusing cached KV (key-value) computations for shared prefixes across queries, respectively.
By default, vLLM will automatically enable the chunked prefill feature if a model has a context length of more than 32k tokens. The maximum number of tokens to be chunked for prefill is set to 512 by default.
Before we dive deep into the graph, we’ll first try to explain the terminology used in the experiment. Fresh Run refers to the situation where the prefix caching memory is not populated at all. 2nd Run refers to rerunning the benchmark script again after the Fresh Run. In general, when rerunning the ShareGPT benchmark dataset on the 2nd Run, we get around a 50% prefix caching hit-rate.
Looking at the graphs below, we can make three observations about this experiment.
- Based on the comparison of Bar 2 (red) with the baseline (blue), there is a huge gain in performance.
- Based on the comparison of Bar 3 (yellow), Bar 5 (orange) and Bar 6 (teal) with the baseline, the chunked prefill performance depends on the user request input prompt length distribution.
- In our experiments we found that the prefix caching hit rates of Bar 3 (yellow) and Bar 4 (green) are around 0.9% and 50%. Based on the comparison of Bar 3 (yellow) and Bar 4 (green) with the baseline and Bar 2 (red), this tells us that if the user requests do not have high prefix caching hit rate, disabling both chunked prefill and prefix caching might be considered a good rule of thumb.
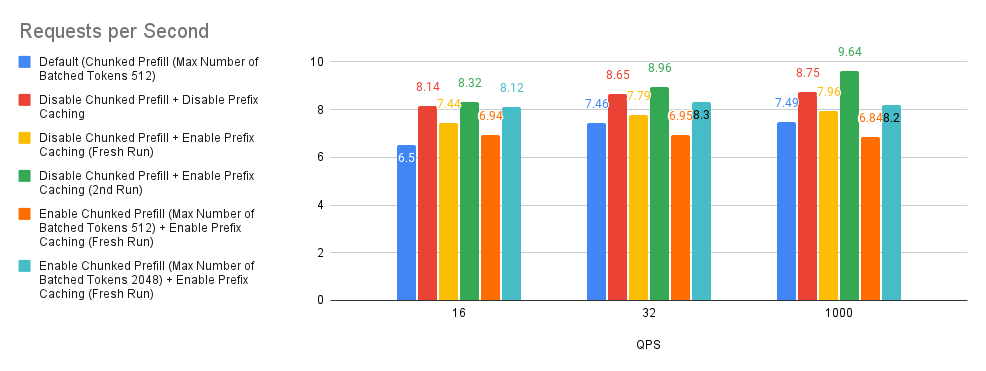
.png)
.png)
Case 4: Max sequence length to capture
The --max-seq-len-to-capture argument in vLLM controls the maximum sequence length that can be handled by CUDA/HIP graphs, which optimize performance by capturing and replaying GPU operations. If a sequence exceeds this length, the system reverts to eager mode executing operations one by one, which can be less efficient. This applies to both regular and encoder-decoder models.
Our benchmarks reveal an interesting trend: increasing --max-seq-len-to-capture doesn’t always improve performance and can sometimes even degrade it. This might be due to how vLLM creates buckets for different sequence lengths.
Here’s why:
- Bucketing: vLLM uses buckets to group sequences of similar lengths, optimizing graph capture for each bucket.
- Optimal Buckets: Initially, the buckets are finely grained (e.g., [4, 8, 12,…, 2048, 4096]), allowing for efficient graph capture for various sequence lengths.
- Coarser Buckets: Increasing
--max-seq-len-to-capturecan lead to coarser buckets (e.g., [4, 8, 12, 2048, 8192]). - Performance Impact: When input sequences fall into these larger, less precise buckets, the captured CUDA/HIP graphs may not be optimal, potentially leading to reduced performance.
Therefore, while capturing longer sequences with CUDA/HIP graphs seems beneficial, it’s crucial to consider the potential impact on bucketing and overall performance. Finding the optimal --max-seq-len-to-capture value may require experimentation to balance graph capture efficiency with appropriate bucket sizes for your specific workload.
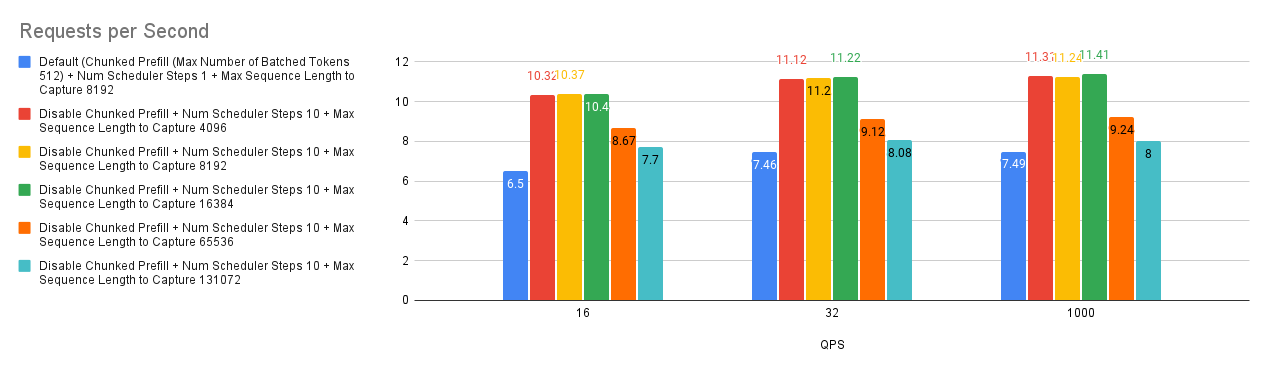
.png)
.png)
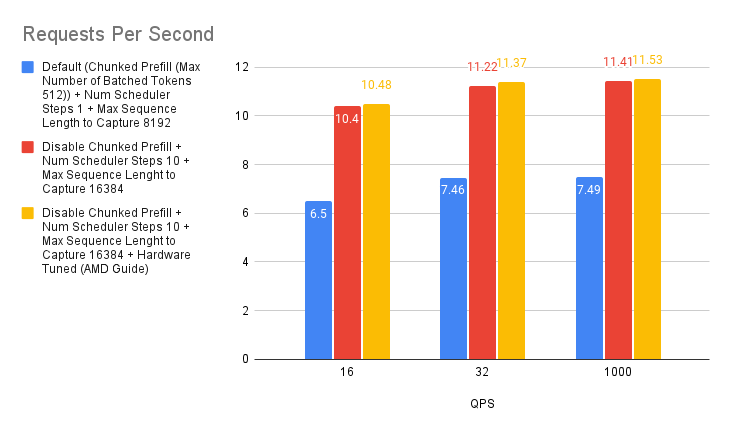
Case 5: AMD Recommended Environmental Variables
To further optimize vLLM performance on AMD MI300X, we can leverage AMD-specific environment variables.
- Disabling NUMA Balancing: Non-Uniform Memory Access (NUMA) balancing can sometimes hinder GPU performance. As recommended in the AMD MAD repository, disabling it can prevent potential GPU hangs and improve overall efficiency. This can be achieved with the following command:
# disable automatic NUMA balancing sh -c 'echo 0 > /proc/sys/kernel/numa_balancing' # check if NUMA balancing is disabled (returns 0 if disabled) cat /proc/sys/kernel/numa_balancing 0 - Tuning NCCL Communication: The NVIDIA Collective Communications Library (NCCL) is used for inter-GPU communication. For MI300X, the AMD vLLM fork performance document suggests setting the
NCCL_MIN_NCHANNELSenvironment variable to 112 to potentially enhance performance.
In our tests, enabling these two configurations yielded a slight performance improvement. This aligns with the findings in the “NanoFlow: Towards Optimal Large Language Model Serving Throughput” paper, which indicates that while optimizing network communication is beneficial, the impact might be limited since LLM inference is primarily dominated by compute-bound and memory-bound operations.
Even though the gains might be small, fine-tuning these environment variables can contribute to squeezing out the maximum performance from your AMD system.
.png)
.png)
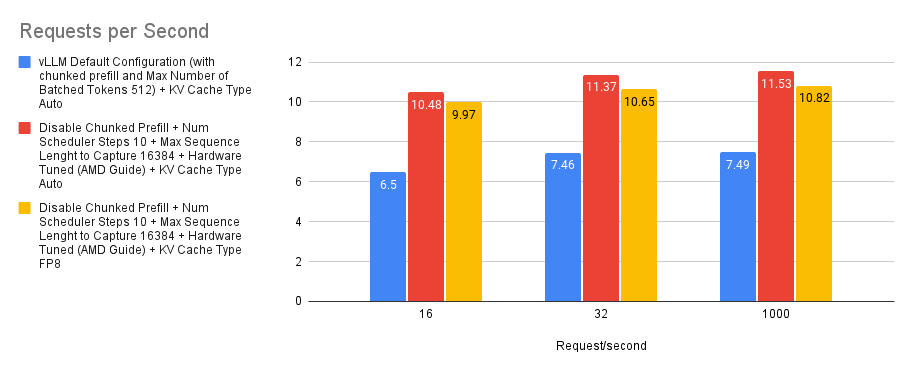
Case 6: KVCache Type Auto/FP8
By default, vLLM will automatically allocate a KV Cache type that matches the model’s data type. However, vLLM also supports native FP8 on MI300X which we can exploit to reduce the memory requirement of KVCache and thereby increasing the deployable context length of the model.
We experiment by using Auto KVCache type and KV Cache type FP8 and compare it to the default baseline. We can see from the figure below that using Auto KVCache type (red) achieves a higher request per second rate than using KV Cache type set to FP8 (yellow). Theoretically, this might be due to a quantization overhead in Llama-3.1-70B-Instruct (bfloat16) model, but since the cost of the overhead seems to be small, it could still be a good tradeoff in some cases to obtain a huge reduction in the KVCache requirements.
.png)
.png)
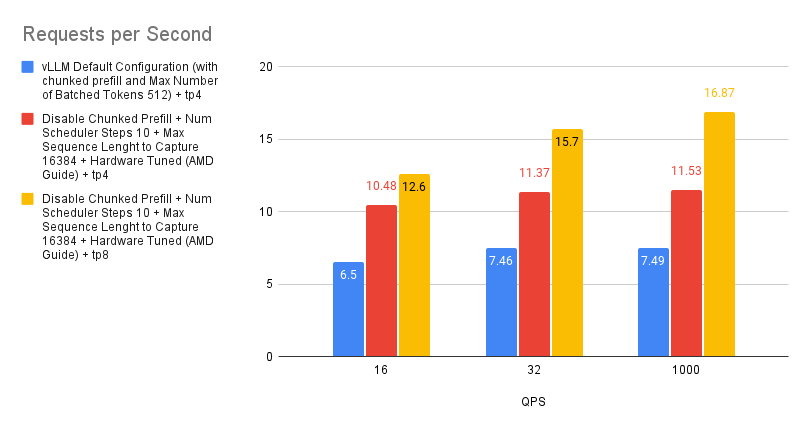
Case 7: Performance Difference between TP 4 and TP 8
Tensor parallelism is a technique for distributing the computational load of large models. It works by splitting individual tensors across multiple devices, allowing for parallel processing of specific operations or layers. This approach reduces the memory footprint of the model and enables scaling across multiple GPUs.
While increasing the tensor parallelism degree can improve performance by providing more compute resources, the gains aren’t always linear. This is because communication overhead increases as more devices are involved, and the workload on each individual GPU decreases. Given the substantial processing power of the MI300X, smaller workloads per GPU can actually lead to underutilization, further hindering performance scaling.
Therefore, when optimizing for throughput, we recommend launching multiple instances of vLLM instead of aggressively increasing tensor parallelism. This approach tends to yield more linear performance improvements. However, if minimizing latency is the priority, increasing the tensor parallelism degree may be the more effective strategy.
.png)
.png)
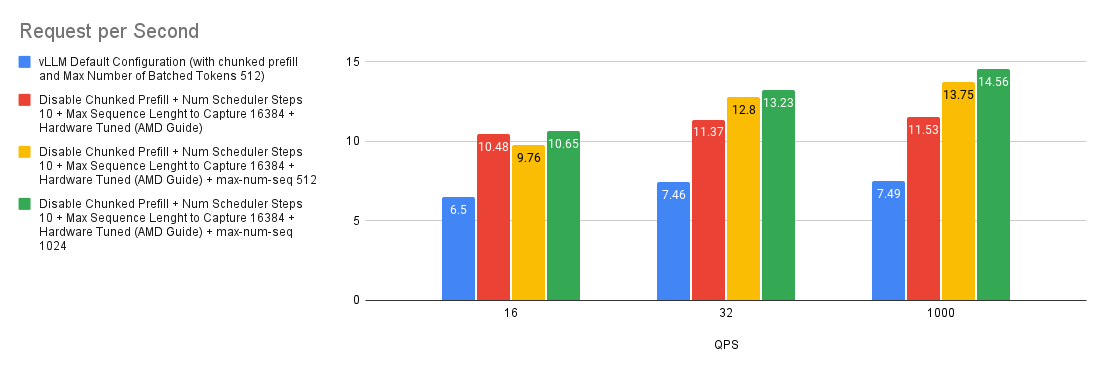
Case 8: Effect of Maximum Number of (Parallel) Sequences
The --max-num-seqs argument specifies the maximum number of sequences that can be processed per iteration. This parameter controls the number of concurrent requests in a batch, impacting memory usage and performance. In the ShareGPT benchmark, due to the shorter input and output length of the samples, the Llama-3.1-70B-Instruct hosted on MI300X can process a large number of requests per iteration. In our experiment, the --max-num-seqs is still a limiting factor, even if --max-num-seqs is set at 1024.
.png)
.png)
Quick Start Guide
If you are not sure about the deployment setting and the distribution of the user requests, you could:
- Use CK Flash Attention* (thought we didn’t show here, the CK Flash Attention implementation is a lot faster than triton counterpart implementation)
export VLLM_USE_TRITON_FLASH_ATTN=0
- Disable chunked prefill
--enable-chunked-prefill=False - Disable prefix caching
- If the model supports long context length, set the
--max-seq-len-to-captureto 16384 - Set
--num-scheduler-stepsto 10 or 15. - Set the AMD environment:
sh -c 'echo 0 > /proc/sys/kernel/numa_balancing'export NCCL_MIN_NCHANNELS=112
- Increase
--max-num-seqsto 512 and above, depending on the GPU memory and compute resource of the GPUs.
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve meta-llama/Llama-3.1-70B-Instruct --host 0.0.0.0 --port 8000 -tp 4 --max-num-seqs 1024 --max-seq-len-to-capture 16384 --served-model-name meta-llama/Llama-3.1-70B-Instruct --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024
For quick setup, we have compiled the Docker Image of vLLM 0.6.2 (commit: cb3b2b9ba4a95c413a879e30e2b8674187519a93) to Github Container Registry. To get download the image:
# v0.6.2 post
docker pull ghcr.io/embeddedllm/vllm-rocm:cb3b2b9
# P.S. We also have compiled the image for v0.6.3.post1 at commit 717a5f8
docker pull ghcr.io/embeddedllm/vllm-rocm:v0.6.3.post1-717a5f8
To launch a docker container with the image run:
sudo docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v /path/to/hfmodels:/app/model \ # if you have pre-downloaded the model weight, else ignore
ghcr.io/embeddedllm/vllm-rocm:cb3b2b9 \
bash
Now launch the LLM server with the parameters that we have found:
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve meta-llama/Llama-3.1-70B-Instruct --host 0.0.0.0 --port 8000 -tp 4 --max-num-seqs 1024 --max-seq-len-to-capture 16384 --served-model-name meta-llama/Llama-3.1-70B-Instruct --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024
Conclusion
This guide has explored the power of vLLM for serving large language models on AMD MI300X GPUs. By meticulously tuning key settings like chunked prefill, multi-step scheduling, and CUDA graph capture, we’ve demonstrated how to achieve substantial performance gains over standard configurations and alternative serving solutions. vLLM unlocks significantly higher throughput and faster response times, making it an ideal choice for deploying LLMs on AMD hardware.
However, it’s important to acknowledge that our exploration has focused primarily on general chatbot usage with short inputs and outputs. Further investigation is needed to optimize vLLM for specific use cases like summarization or long-form content generation. Additionally, a deeper dive into the performance differences between Triton and CK attention kernels could yield further insights.
We also want to acknolwedge this wonderful blogpost by Leonard Lin on how to further optimize vLLM for MI300X, including hipBLAS vs hipBLASLt, CK Flash Attention vs Triton Flash Attention, Tensor Parallelism vs Pipeline Parallelism, etc.
Acknowledgements
This blog post is drafted by the team at Embedded LLM and thank you to Hot Aisle Inc. for sponsoring MI300X for benchmarking vLLM.
Appendix
Server Specification
The following are the configuration of the amazing Hot Aisle server:
- CPU: 2 x Intel Xeon Platinum 8470
- GPU: 8 x AMD Instinct MI300X Accelerators The model and software that we are using in the benchmark are as follows:
- Model: meta-llama/Llama-3.1-405B-Instruct and meta-llama/Llama-3.1-70B-Instruct
- vLLM (v0.6.2): vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs (github.com) commit: cb3b2b9ba4a95c413a879e30e2b8674187519a93
- Dataset: ShareGPT
- Benchmark script: benchmarks/benchmark_serving.py in the repository
We have built the ROCm compatible vLLM docker from Dockerfile.rocm found in the repository (we have pushed the docker image of the vLLM version that we have used to run our benchmark. Get it by docker pull ghcr.io/embeddedllm/vllm-rocm:cb3b2b9).
All of the benchmarks are run in the docker container instance, and are run with 4 MI300X GPUs using CK Flash Attention with VLLM_USE_TRITON_FLASH_ATTN=0.
Detail Benchmark Configuration
| Configuration | Command |
|---|---|
| vLLM Default Configuration | VLLM_RPC_TIMEOUT=30000 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve Llama-3.1-405B-Instruct -tp 8 --max-num-seqs 1024 --max-num-batched-tokens 1024 |
| TGI Default Configuration | ROCM_USE_FLASH_ATTN_V2_TRITON=false TRUST_REMOTE_CODE=true text-generation-launcher --num-shard 8 --sharded true --max-concurrent-requests 1024 --model-id Llama-3.1-405B-Instruct |
| vLLM (This Guide) | VLLM_RPC_TIMEOUT=30000 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve Llama-3.1-405B-Instruct -tp 8 --max-seq-len-to-capture 16384 --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024 |
| TGI (This Guide) | ROCM_USE_FLASH_ATTN_V2_TRITON=false TRUST_REMOTE_CODE=true text-generation-launcher --num-shard 8 --sharded true --max-concurrent-requests 1024 --max-total-tokens 131072 --max-input-tokens 131000 --model-id Llama-3.1-405B-Instruct |