vLLM Semantic Router v0.1 Iris: The First Major Release
vLLM Semantic Router is the System Level Intelligence for Mixture-of-Models (MoM), bringing Collective Intelligence into LLM systems. It lives between users and models, capturing signals from requests, responses, and context to make intelligent routing decisions—including model selection, safety filtering (jailbreak, PII), semantic caching, and hallucination detection. For more background, see our initial announcement blog post.
We are thrilled to announce the release of vLLM Semantic Router v0.1, codename Iris—our first major release that marks a transformative milestone for intelligent LLM routing. Since our experimental launch in September 2025, we’ve witnessed extraordinary community growth: over 600 Pull Requests merged, 300+ Issues addressed, and contributions from more than 50 outstanding engineers worldwide. As we kick off 2026, we’re excited to deliver a production-ready semantic routing platform that has evolved dramatically from its origins.

Why Iris?
In Greek mythology, Iris (Ἶρις) served as the divine messenger who bridged the realms of gods and mortals, traveling on the arc of the rainbow to deliver messages across vast distances. This symbolism perfectly captures what vLLM Semantic Router v0.1 achieves: a bridge between users and diverse AI models, intelligently routing requests across different LLM providers and architectures.
What’s New in v0.1 Iris?
1. Architecture Overhaul: Signal-Decision Plugin Chain Architecture
Before: The early Semantic Router relied on a single-dimensional approach—classifying queries into one of 14 MMLU domain categories with statically orchestrated jailbreak, PII, and semantic caching capabilities.
Now: We’ve introduced the Signal-Decision Driven Plugin Chain Architecture, a complete reimagining of semantic routing that scales from 14 fixed categories to unlimited intelligent routing decisions.
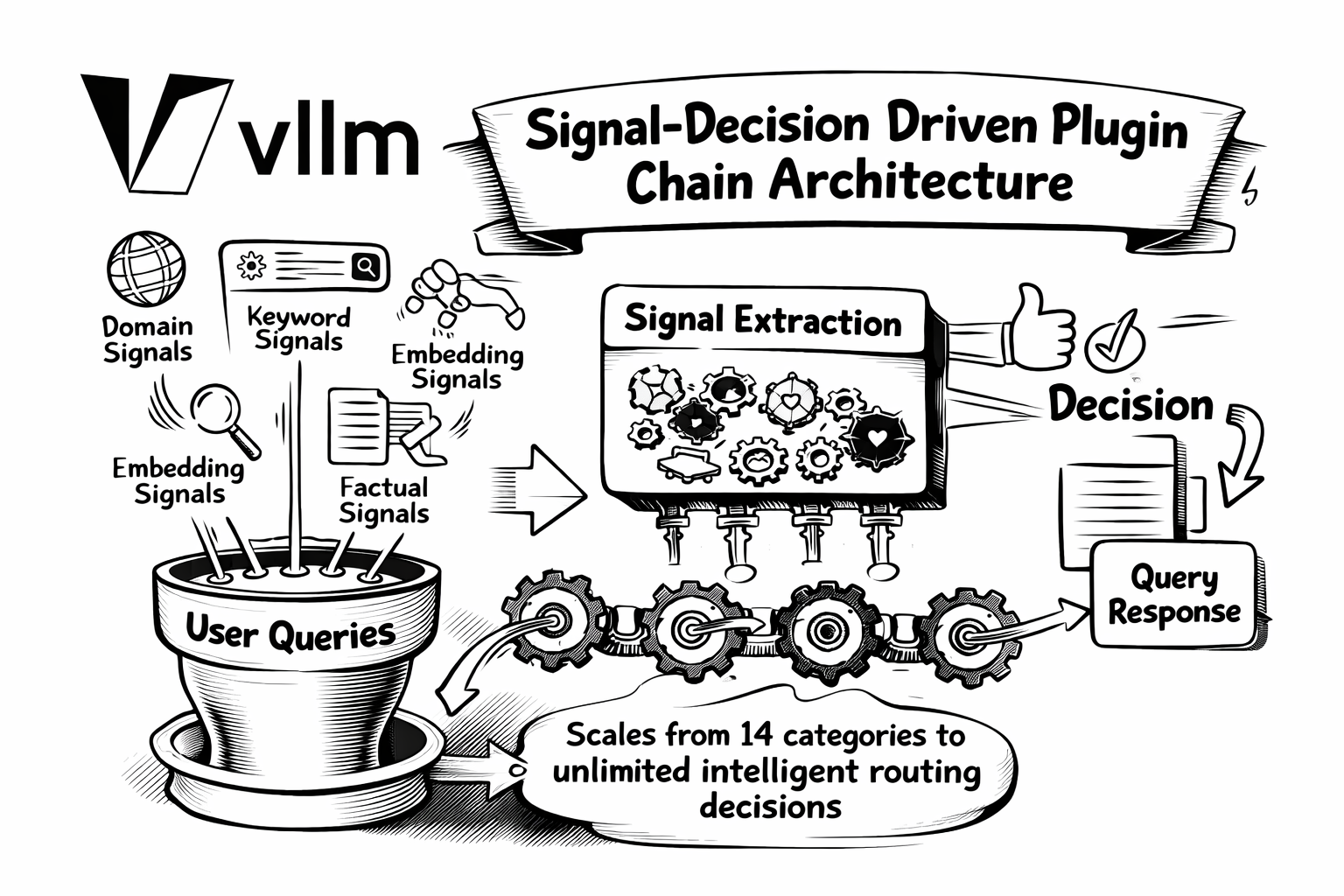
The new architecture extracts six types of signals from user queries:
- Domain Signals: MMLU-trained classification with LoRA extensibility
- Keyword Signals: Fast, interpretable regex-based pattern matching
- Embedding Signals: Scalable semantic similarity using neural embeddings
- Factual Signals: Fact-check classification for hallucination detection
- Feedback Signals: User satisfaction/dissatisfaction indicators
- Preference Signals: Personalization based on user defined preferences
These signals serve as inputs to a flexible decision engine that combines them using AND/OR logic with priority-based selection. Previously static features like jailbreak detection, PII protection, and semantic caching are now configurable plugins that users can enable per-decision:
| Plugin | Purpose |
|---|---|
semantic-cache |
Cache similar queries for cost optimization |
jailbreak |
Detect prompt injection attacks |
pii |
Protect sensitive information |
hallucination |
Real-time hallucination detection |
system_prompt |
Inject custom instructions |
header_mutation |
Modify HTTP headers for metadata propagation |
This modular design enables unlimited extensibility—new signals, plugins, and model selection algorithms can be added without architectural changes. Learn more in our Signal-Decision Architecture blog post.
2. Performance Optimization: Modular LoRA Architecture
In collaboration with the Hugging Face Candle team, we’ve completely refactored the router’s inference kernel. The previous implementation required loading and running multiple fine-tuned models independently—computational cost grew linearly with the number of classification tasks.
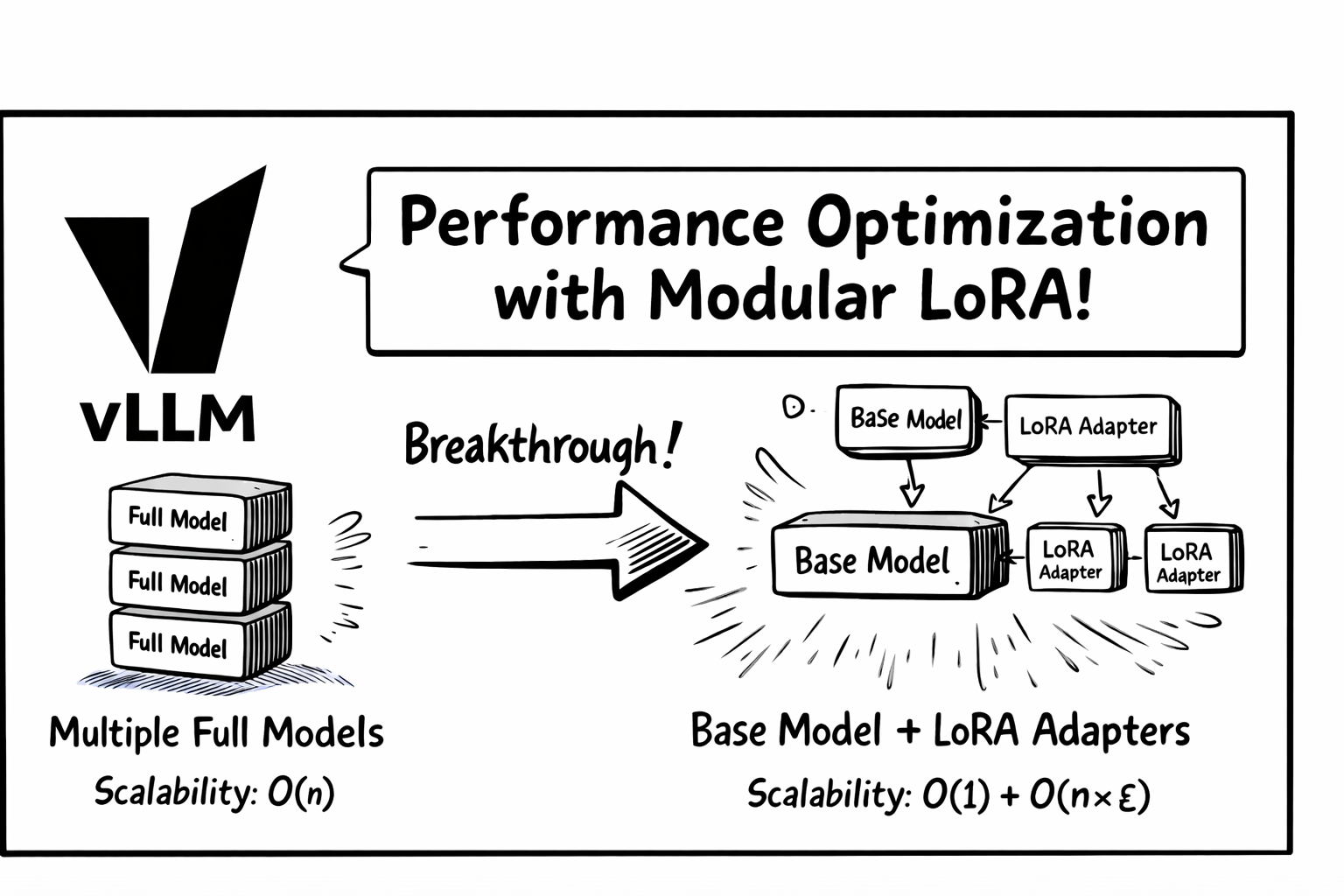
The breakthrough: By adopting Low-Rank Adaptation (LoRA), we now share base model computation across all classification tasks:
| Approach | Workload | Scalability |
|---|---|---|
| Before | N full model forward passes | O(n) |
| After | 1 base model pass + N lightweight LoRA adapters | O(1) + O(n×ε) |
Note: Here ε represents the relative cost of a LoRA adapter forward pass compared to the full base model—typically ε « 1, making the additional overhead negligible.
This architecture delivers significant latency reduction while enabling multi-task classification on the same input. See the full technical details in our Modular LoRA blog post.
3. Safety Enhancement: HaluGate Hallucination Detection
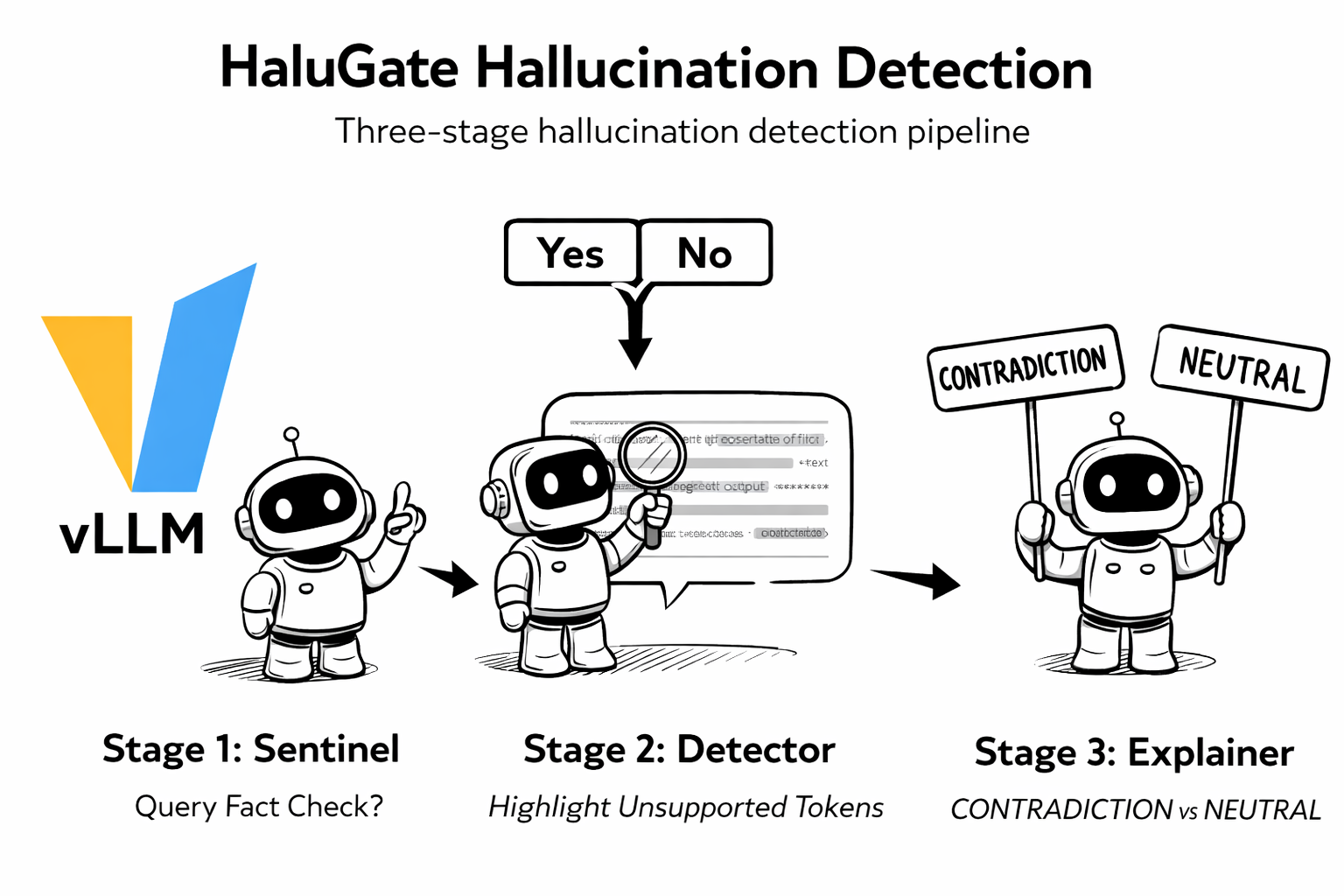
Beyond request-time safety (jailbreak, PII), v0.1 introduces HaluGate—a three-stage hallucination detection pipeline for LLM responses:
Stage 1: HaluGate Sentinel – Binary classification determining if a query warrants factual verification (creative writing and code don’t need fact-checking).
Stage 2: HaluGate Detector – Token-level detection identifying exactly which tokens in the response are unsupported by the provided context.
Stage 3: HaluGate Explainer – NLI-based classification explaining why each flagged span is problematic (CONTRADICTION vs NEUTRAL).
HaluGate integrates seamlessly with function-calling workflows—tool results serve as ground truth for verification. Detection results are propagated via HTTP headers, enabling downstream systems to implement custom policies. Dive deeper in our HaluGate blog post.
4. UX Improvements: One-Command Installation
Local Development:
pip install vllm-sr
Get started in seconds with a single pip command. The package includes all core dependencies for quickstart.
Configuration: After installation, run
vllm-sr initto generate the defaultconfig.yaml. Then configure your LLM backends in theproviderssection:providers: models: - name: "openai/gpt-oss-120b" # Local vLLM endpoint endpoints: - endpoint: "localhost:8000" protocol: "http" access_key: "your-vllm-api-key" - name: "openai/gpt-4" # External provider endpoints: - endpoint: "api.openai.com" protocol: "https" access_key: "sk-xxxxxx" default_model: "openai/gpt-oss-120b"See the configuration documentation for full details.
Kubernetes Deployment:
helm install semantic-router oci://ghcr.io/vllm-project/charts/semantic-router
Production-ready Helm charts with sensible defaults and extensive customization options. It helps you deploy vLLM Semantic Router in Kubernetes with ease.
Dashboard: A comprehensive web console for managing intelligent routing policies, model configurations, and an interactive chat playground for testing routing decisions in real-time. Visualize routing flows, monitor latency distributions, and fine-tune classification thresholds—all from an intuitive browser-based interface.
5. Ecosystem Integration
vLLM Semantic Router v0.1 integrates seamlessly with the broader AI infrastructure ecosystem:
Inference Frameworks:
- vLLM Production Stack – Reference stack for production vLLM deployment with Helm charts, request routing, and KV cache offloading
- NVIDIA Dynamo – Datacenter-scale distributed inference framework for multi-GPU, multi-node serving with disaggregated prefill/decode
- llm-d – Kubernetes-native distributed inference stack for achieving SOTA performance across accelerators (NVIDIA, AMD, Google TPU, Intel XPU)
- vLLM AIBrix – Open-source GenAI infrastructure building blocks for scalable LLM serving
API Gateways:
- Envoy AI Gateway – Unified access to generative AI services built on Envoy Gateway with multi-provider support
- Istio – Open-source service mesh for enterprise deployments with traffic management, security, and observability
6. MoM (Mixture of Models) Family
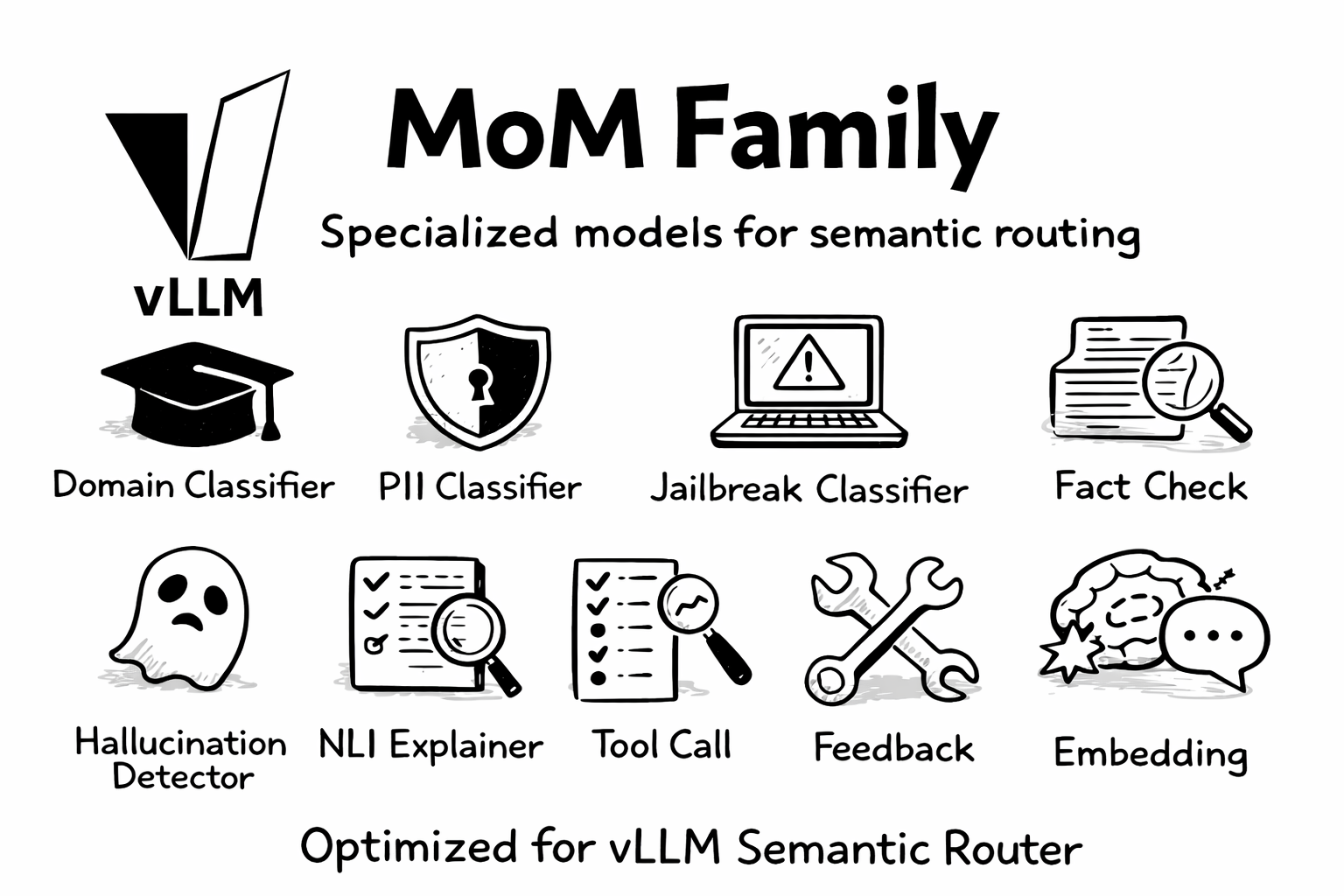
We’re proud to introduce the MoM Family—a comprehensive suite of specialized models purpose-built for semantic routing:
| Model | Purpose |
|---|---|
mom-domain-classifier |
MMLU-based domain classification |
mom-pii-classifier |
PII detection and protection |
mom-jailbreak-classifier |
Prompt injection detection |
mom-halugate-sentinel |
Fact-check classification |
mom-halugate-detector |
Token-level hallucination detection |
mom-halugate-explainer |
NLI-based explanation |
mom-toolcall-sentinel |
Tool selection classification |
mom-toolcall-verifier |
Tool call verification |
mom-feedback-detector |
User feedback analysis |
mom-embedding-x |
Semantic embedding extraction |
All MoM models are specifically trained and optimized for vLLM Semantic Router, providing consistent performance across routing scenarios.
7. Responses API Support
We now support the OpenAI Responses API (/v1/responses) with in-memory conversation state management:
- Stateful Conversations: Built-in state management with
previous_response_idchaining - Multi-turn Context: Automatic context preservation across conversation turns
- Routing Continuity: Intent classification history maintained across the conversation
This enables intelligent routing for modern agent frameworks and multi-turn applications.
8. Tool Selection
Intelligent tool management for agentic workflows:
- Semantic Tool Filtering: Automatically filter irrelevant tools before sending to LLM
- Context-Aware Selection: Consider conversation history and task requirements
- Reduced Token Usage: Smaller tool catalogs mean faster inference and lower costs
Looking Ahead: v0.2 Roadmap
While v0.1 Iris establishes a solid foundation, we’re already planning significant enhancements for v0.2:
Signal-Decision Architecture Enhancements
- More Signal Types: Extract additional valuable signals from user queries
- Improved Accuracy: Enhance existing signal computation precision
- Signal Composer: Design a signal composition layer for complex signal extraction and improved performance
Model Selection Algorithms
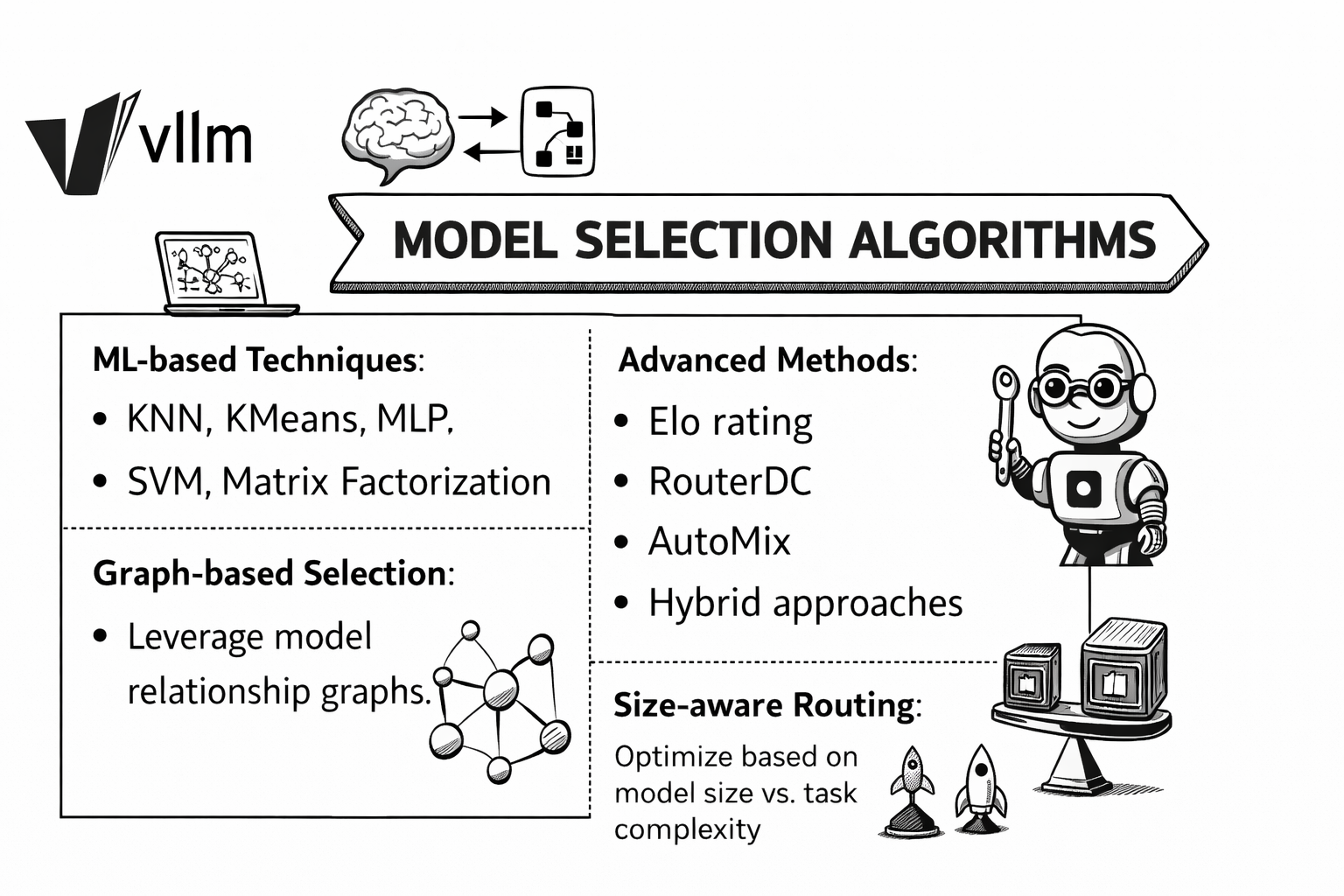
Building on the Signal-Decision foundation, we’re researching intelligent model selection algorithms:
- ML-based Techniques: KNN, KMeans, MLP, SVM, Matrix Factorization
- Advanced Methods: Elo rating, RouterDC, AutoMix, Hybrid approaches
- Graph-based Selection: Leverage model relationship graphs
- Size-aware Routing: Optimize based on model size vs. task complexity
Out-of-Box Plugins
- Memory Plugin: Persistent conversation memory management
- Router Replay: Debug and replay routing decisions and feedback
Multi-turn Algorithm Exploration
- Response API Enhancement: Extended stateful conversation support with extensible backends like Redis, Milvus, and Memcached.
- Context Engineering: Context compression and memory management
- RL-driven Selection: Reinforcement learning for user preference-driven model selection
MoM Enhancements
- Pre-train Base Model: Longer context window for signal extraction
- Post-train SLM: Human preference signal extraction
- Model Migration: Replace existing models with self-trained alternatives
Safety Enhancements
- Tool Calling Jailbreak Detection: Protect against malicious tool invocations
- Multi-turn Guardrails: Safety across conversation sessions
- Improved Hallucination Accuracy: Higher precision hallucination detection
Intelligent Tool Management
- Tool Completion: Auto-complete tool definitions and calling based on intents.
- Advanced Tool Filtering: More sophisticated relevance filtering
UX & Operations
- Dashboard Enhancements: Improved visualization and management capabilities
- Helm Chart Improvements: More configuration options and deployment patterns
Evaluation
- Working with RouterArena Team on comprehensive router evaluation frameworks
Acknowledgments
vLLM Semantic Router v0.1 Iris represents a truly global collaboration. We gratefully acknowledge the contributions from organizations including Red Hat, IBM Research, AMD, Hugging Face, and many others.
We’re proud to welcome our growing committer community:
Senan Zedan, samzong, Liav Weiss, Asaad Balum, Yehudit, Noa Limoy, JaredforReal, Abdallah Samara, Hen Schwartz, Srinivas A, carlory, Yossi Ovadia, Jintao Zhang, yuluo-yx, cryo-zd, OneZero-Y, aeft
And to the 50+ contributors who helped make this release possible—thank you!
Get Started
Ready to try vLLM Semantic Router v0.1 Iris?
pip install vllm-sr
Join the Community
We believe the future of intelligent routing is built together. Whether you’re a company looking to integrate intelligent routing into your AI infrastructure, a researcher exploring new frontiers in semantic understanding, or an individual developer passionate about open-source AI—we welcome your participation.
Ways to contribute:
- Organizations: Partner with us on integrations, sponsor development, or contribute engineering resources
- Researchers: Collaborate on papers, propose new algorithms, or help benchmark performance
- Developers: Submit PRs, report issues, improve documentation, or build community plugins
- Community: Share use cases, write tutorials, translate docs, or help answer questions
Every contribution matters—from fixing a typo to architecting a new feature. Join us in shaping the next generation of semantic routing infrastructure.
- Documentation: vllm-semantic-router.com
- GitHub: vllm-project/semantic-router
- Models: Hugging Face
- Community: Join us on Slack in vLLM Slack
The rainbow bridge is now open. Welcome to Iris. 🌈